DPT (2021):Vision Transformer 革新密集深度预测
导出时间:2025/11/24 09:04:25
1、背景:为什么 CNN 在深度估计里有瓶颈?
你可以把 CNN 编码器 想象成一台相机:
- 它一边“拍照”,一边不断缩小画面(下采样),试图把大画面总结成一个小小的摘要。
- 这种方式的好处是节省存储和算力,还能捕捉到一些抽象的高级特征。
但是问题来了:
- 越缩越小,细节模糊
- 就像你把一张照片压缩成缩略图,放大回去的时候,细小的边缘(比如树枝、路灯)已经丢失了,再怎么放大也还原不出来。
- 在深度估计中,这意味着预测结果常常“糊边”,小目标被抹掉。
- 只能“看局部”,缺乏全局眼光
- CNN 的感受野是通过一层层卷积“拼”出来的,就像你走进森林,眼睛只能看附近几棵树,想知道整个森林有多大,要走很久。
- 在深度估计里,这导致模型容易犯“局部判断错误”:比如把远处的天空和山搞混。
论文里就强调了:CNN 编码器一旦在早期丢掉了信息,解码器再强也救不回来
2、动机:为什么用 Vision Transformer (ViT)?
这时,研究者们借鉴了 NLP 的 Transformer,提出了一个新思路:
👉 与其让网络像近视眼一样一层层拼上下文,不如一开始就让它拥有“全局视野”。
比喻:
- CNN 像是一个画工,趴在画布前,从左上角一格格描绘,画完才知道全貌。
- Transformer 更像是一个无人机,直接飞到高空,一眼就能看到整个画布,然后再决定每个局部该怎么处理。
在 Vision Transformer (ViT) 里:
- 图像被切成一个个小块(patch),每个小块就像一个“单词”。
- 通过自注意力机制(self-attention),这些“小块”之间能互相交流,保证全局一致性。
于是,DPT 的动机就是:
- 用 ViT 替代 CNN 做编码器,让网络在每一层都能看到整幅图,而不是只看局部。
- 保持较高的分辨率处理特征,避免了卷积下采样造成的细节损失。
- 再配合卷积解码器,把全局+细节的信息重新组合,生成既细腻又连贯的深度图。
论文里的实验也说明了:
- 在大规模数据上,DPT 比传统 CNN 提升高达 28%
- 不仅细节更清楚,预测结果在整体上也更合理(比如远近关系更自然)。
- Monodepth/2(CNN 系):像个近视眼画工,靠局部堆叠去理解全局,结果边缘模糊、容易犯“整体错误”。
- DPT(ViT 系):像无人机+画工结合体,既能鸟瞰全局,又能落地补细节,所以生成的深度预测更细腻、更连贯。
3、DPT 的核心创新点
- Transformer 编码器取代 CNN 编码器
- 传统深度估计(比如 Monodepth2)用 CNN 来提取特征,但会丢失细节,且只能逐层扩展感受野。
- DPT 用 Vision Transformer (ViT) 作为 backbone,利用自注意力机制,每一层都能建模全局关系。
- 比喻:CNN 像“拿着放大镜看局部”,而 ViT 像“无人机鸟瞰全局”。
- 新颖的解码架构(Reassembly Transformer Features)
- ViT 输出的是一系列“打散”的 patch 特征(没有天然的空间结构),这和 CNN 的特征图不同。
- DPT 提出了一种 特征重组模块 (reassembly module),把 Transformer 的输出重新拼装成多尺度的空间特征图。
- 这样解码器就可以像在 CNN 里那样,逐层恢复分辨率,同时结合局部卷积增强细节。
- 比喻:Transformer 像是“打散成拼图块”的全局信息,而解码器就像“拼图高手”,能把碎片拼成一幅完整的、有细节的图像。
- 多任务通用性
- 论文里,DPT 不仅应用于单目深度预测,还应用到 语义分割 和 人体部件分割。
- 核心原因是:只要是 密集预测任务(dense prediction),都需要 局部细节 + 全局一致性,而 DPT 恰好兼顾了这两点。
- 比喻:DPT 像是一位“通才选手”,不仅能预测深度,还能胜任其他需要像素级理解的任务。
- 更强的大规模训练适应性
- Transformer 的一个特性是:随着训练数据的增大,性能提升幅度比 CNN 更显著。
- DPT 在大规模数据(如 MiDaS 数据集)上训练时,性能远超之前的 CNN 模型。
- 比喻:CNN 像一个“死记硬背型学生”,数据多了也未必能学好;而 Transformer 像“善于举一反三的学生”,学得越多越聪明。
✅ 总结:DPT 的创新点
一句话总结: 👉 DPT 用 Transformer 编码器取代 CNN,并设计了一个特征重组+卷积解码器的结构,使模型既能看到全局,又能还原细节,还能适用于各种密集预测任务。
4、DPT 的整体架构图
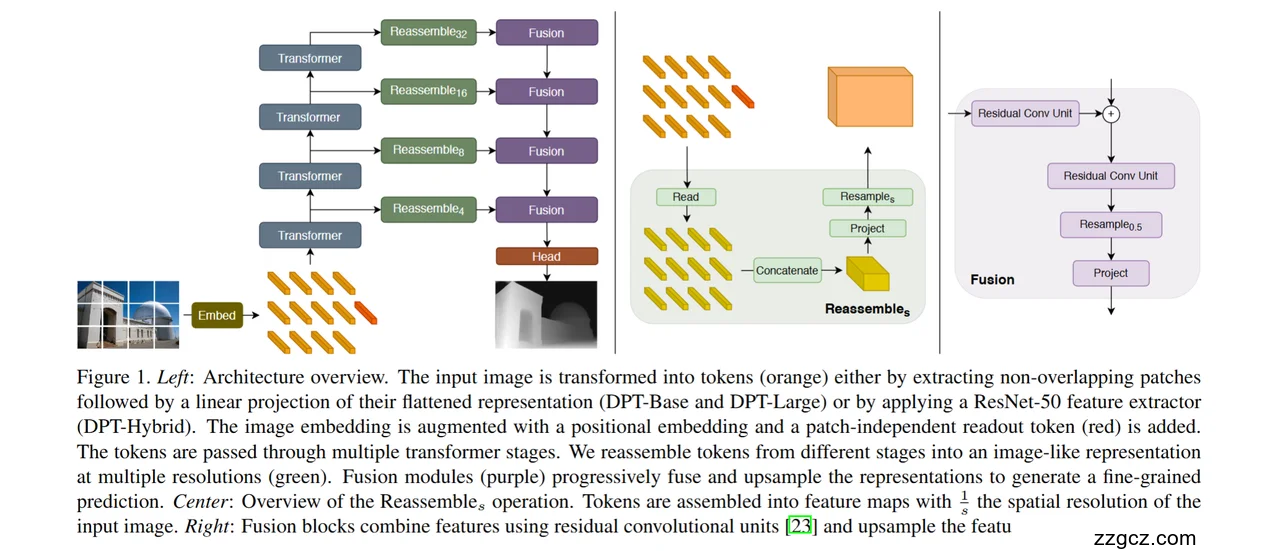
🔎 整体思路
DPT 的流程可以分为三步:
- 编码 (Embedding + Transformer):把图像切成小块 → 变成 token → 用 Transformer 提取全局特征。
- 重组 (Reassemble):把 token 重新拼成空间特征图,不同层对应不同分辨率。
- 融合与预测 (Fusion + Head):多尺度特征逐步融合、上采样,最后输出深度图(或语义分割图)。
🟨 Step 1: 输入和 Transformer 编码
(看图左下角到中间)
- 原始图像被切成一个个小块(patch),就像把照片切成小方块。
- 每个小块通过 Embed 模块,变成一个向量(黄色小条)。
- 这些向量加上位置编码,送进一层层 Transformer(蓝色方块)。
🟩 Step 2: 特征重组 (Reassemble)
(看图中间绿色方块 + 中央示意图)
- Transformer 输出的还是一堆“token”,不像 CNN 那样天然带有空间结构。
- Reassemble 模块就是把这些 token “拼回去”,恢复成类似图像的特征图。
- 而且,作者设计了多个 Reassemble₄, Reassemble₈, Reassemble₁₆, Reassemble₃₂,对应不同分辨率(1/4, 1/8, 1/16, 1/32 尺度)。
👉 比喻:
Transformer 把图像信息“打散”了,就像一盒拼图碎片;Reassemble 模块就是拼图高手,把碎片拼成不同大小的拼图,既有高清的小拼图(细节),也有粗糙的大拼图(全局)。
🟪 Step 3: 融合与解码 (Fusion + Head)
(看图右边紫色 Fusion 块 + 输出 Head)
- 每个 Reassemble 输出的特征图被送到 Fusion 模块。
- Fusion 用 卷积残差单元 (Residual Conv Unit) 来结合不同尺度的特征,并逐步 上采样,恢复到接近原图的分辨率。
- 最后经过 Head,生成密集预测结果(如深度图)。
👉 比喻:
Fusion 就像一位画师,把“拼图高手”提供的不同大小拼图合在一起:
- 大拼图提供全局结构;
- 小拼图提供细节; 最后画师把它们融合成一幅完整、细致的作品(深度图)。
🎯 总结:DPT 架构的关键点
- 输入 → Transformer:用自注意力机制提取全局特征。
- Reassemble:把 token 重新变成多尺度特征图,弥补 Transformer 缺乏空间结构的不足。
- Fusion:多尺度特征逐步融合和上采样,既保证全局一致性,又保留细节。
- Head:输出任务结果(深度估计 / 分割等)。
✅ 一句话概括:
DPT 架构像是 无人机(Transformer)鸟瞰全局 → 拼图高手(Reassemble)重建局部特征图 → 画师(Fusion + Head)整合全局与细节 → 输出精美深度图。
⚠️ DPT 的主要缺陷
- 计算量大,效率低
- Transformer 的自注意力机制是 O(N²) 的复杂度(N = patch 数量)。
- 当输入图像分辨率较高时,token 数量暴涨,显存和计算量都会非常大。
- 这导致 DPT 很难在移动端、实时场景中使用。 👉 比喻:就像开会时,所有人必须互相讨论一遍,参与人数一多,会议效率立刻崩掉。
- 空间结构弱
- CNN 天生保留空间邻域关系(卷积核就是局部感知),但 ViT 把图像切成 patch 后,原始的空间关系被打散,需要 Reassemble 模块再拼回来。
- 这种“先打散再拼回”的方式并不是最优,导致 DPT 在边缘细节和小目标处理上仍有不足。 👉 比喻:拼图高手虽然能拼回画面,但有时边角的碎片拼得不够精细。
- 训练依赖大规模数据
- Transformer 本身不具备 CNN 的归纳偏置(比如平移不变性),需要非常大的数据集来学会这些特性。
- DPT 在 MiDaS 这样的大数据集上表现优异,但在小数据集(比如 KITTI)上效果未必能完全发挥。 👉 比喻:Transformer 更像“天才型学生”,需要大量见世面(数据)才能开窍,否则发挥不稳定。
- 解码器相对简单
- DPT 的解码部分主要靠 Fusion 模块逐步融合+上采样,相比一些专门设计的解码器(比如带有注意力机制、多尺度金字塔结构),表达能力有限。
- 在语义分割等需要精确边界的任务中,DPT 的结果可能没有后续方法细腻。
🔧 后续模型的创新改进方向
- 高效 Transformer 结构
- Swin Transformer:引入滑动窗口注意力机制,把全局注意力变成局部注意力 + 跨窗口通信,大幅降低计算量。
- SegFormer / BEiT / MAE:通过结构改造或自监督预训练,让 Transformer 更高效、更适合下游任务。 👉 这些模型解决了 计算效率 问题,让 Transformer 在高分辨率输入下也能跑得动。
- 更强的空间建模
- 一些后续方法把 CNN 和 Transformer 结合(Hybrid 模型),利用 CNN 保留局部空间关系,Transformer 负责全局建模。
- 例如 LeViT, CvT (Convolutional Vision Transformer),把卷积嵌入进 ViT,增强局部特征提取能力。 👉 这相当于“无人机鸟瞰 + 放大镜检查”,既看全局又不丢细节。
- 解码器增强
- 后续很多方法引入 注意力机制的解码器(比如 Transformer-based U-Net),在上采样阶段动态选择重要特征。
- 有些方法用 多尺度特征融合策略(如 Feature Pyramid Transformer),进一步提升边界和小目标预测能力。
- 小数据集适应性
- 引入 自监督预训练(如 MAE, DINO, DeiT),在大数据上先学通用特征,再迁移到小数据集任务。
- 这样能显著缓解 DPT 对大规模标注数据的依赖问题。