Depth Anything(2024):释放大规模未标注数据的力量,通用深度估计大模型
导出时间:2025/11/24 09:04:34
1、研究背景与动机
在计算机视觉与人工智能的快速发展中,基础模型(Foundation Models) 已经在图像识别、自然语言处理等任务中展现出卓越的 零样本/少样本能力。这些模型的成功关键在于:它们能依赖 大规模、多样化的数据集,覆盖广泛的真实世界分布,从而获得强大的泛化性能
然而,在 单目深度估计(Monocular Depth Estimation, MDE) 领域,情况却截然不同:
- 构建 带有精确深度标签 的大规模数据集极为困难。通常需要依赖 激光雷达、立体相机或结构光 等昂贵复杂的设备进行采集,既耗时又费力。
- 已有的数据集往往规模有限、场景单一,导致训练出的模型在遇到 未知场景或跨域任务 时,泛化能力严重不足
早期的突破性工作 MiDaS 尝试在 混合数据集 上训练模型,并通过 尺度与位移不变的损失函数 来消除不同数据集间的深度差异,提升模型在零样本场景下的表现。但由于数据覆盖范围有限,模型在复杂环境(如弱光、远距离或天气变化)下仍不够稳健
这便引出了 Depth Anything 的研究动机:
- 低成本数据扩展的需求
- 与其依赖昂贵的深度传感器,不如利用 大规模单目无标注图像,这些数据在互联网上随处可见,获取几乎零成本。
- 通过已有的预训练深度模型为其自动生成伪标签,就能大幅扩展训练数据规模,提升数据多样性和覆盖度。
- 突破泛化瓶颈
- 仅依赖有限的人工标注数据无法支撑“通用深度模型”的目标。
- 引入海量无标注图像 + 新的训练策略,可以迫使模型学习到更强的鲁棒表征,从而在未见过的场景中依然表现出色。
- 向“通用视觉感知”迈进
- 单目深度估计不仅是自动驾驶、机器人、AR/VR 的核心任务,更是很多下游模型(如图像生成、视频编辑、控制网络)的关键基础。
- 如果能像 NLP 里的 GPT 那样,训练出一个 适用于任意场景的深度基础模型,将极大推动整个视觉生态的发展。
因此,Depth Anything 的核心动机 是:
通过低成本方式引入大规模未标注单目图像,结合新型的伪标签生成与优化策略,打造一个“随处可用”的通用深度估计模型,解决长期困扰该领域的数据瓶颈和泛化不足问题
2、核心创新点
- 大规模低成本数据扩展
- 创新:首次系统性地将 海量未标注单目图像 引入 MDE 训练流程,而不是仅依赖昂贵的深度传感器数据。
- 做法:通过教师模型为 6200 万未标注图像生成伪标签,结合 150 万带标注图像进行联合训练。
- 意义:极大提升了数据的规模与多样性,为构建“通用深度模型”奠定了基础
- 新颖的联合训练策略
- 创新:不是简单地把标注与未标注数据混合训练,而是采用 两阶段的教师–学生框架。
- 第一阶段:用标注数据训练出强教师模型。
- 第二阶段:教师为未标注图像生成伪标签,学生在“更难的优化目标”下学习。
- 意义:这种训练方式能有效压榨未标注数据的信息,使模型学习到更鲁棒的表征
- 语义先验与特征对齐
- 创新:引入 DINOv2 编码器,并提出 特征对齐损失(Feature Alignment Loss),让模型在深度回归时保留来自预训练大模型的丰富语义知识。
- 意义:不需要额外的语义分割辅助任务,就能获得更强的场景理解能力,从而提升深度估计质量
- 多任务感知潜力
- 创新:Depth Anything 的编码器不仅能完成深度估计,还天然适合迁移到 分割、检测等中高层感知任务。
- 意义:表明它具备成为 视觉基础模型(Vision Foundation Model) 的潜力,而不仅仅是一个单任务深度网络
- 突破性的零样本性能
- 结果:在 KITTI、NYUv2、Sintel、DDAD、ETH3D、DIODE 等多个未见过的数据集上,Depth Anything 在 AbsRel、δ<1.25 等指标上显著超越 MiDaS v3.1(即便两者都用 ViT-L 编码器)
- 意义:证明了该方法不仅能解决训练集与测试集的差异,还真正实现了跨域零样本泛化。
📌 总结一句话
Depth Anything 的创新点在于:通过低成本扩展大规模未标注数据、引入教师–学生训练与特征对齐机制,结合强大的 ViT 编码器,打造了一个兼具深度估计性能与多任务潜力的通用基础模型。
3、模型的网络结构
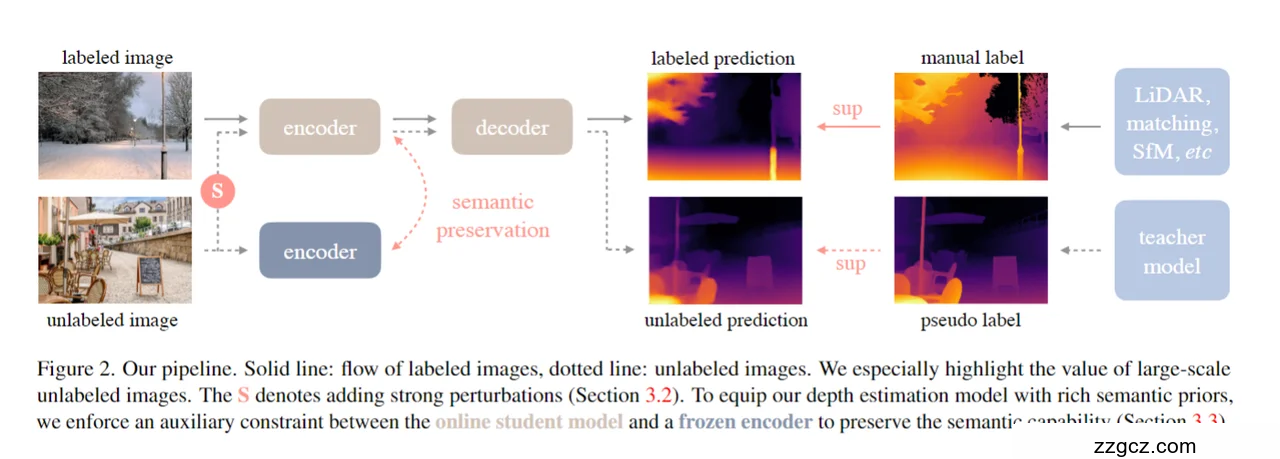
- 整体框架
Depth Anything 采用 编码器–解码器(Encoder–Decoder) 框架,输入可以是 带标签的图像 或 无标签的图像。
- 带标签图像(如 LiDAR、SfM、匹配生成的深度标签):进入主干网络,生成预测深度图,与人工标注深度图对齐训练。
- 无标签图像:通过教师模型生成伪标签(pseudo label),再与学生模型的预测结果对比训练。
这种双通道设计,使模型能够同时利用小规模高质量标注数据和大规模低成本无标注数据。
- 编码器 (Encoder)
- 编码器基于 ViT/DINOv2 Transformer,预训练于大规模图像数据,因此天然具备丰富的语义先验。
- 在训练过程中,为了保持语义特征不被深度回归任务削弱,论文引入了一个 冻结的教师编码器,与学生模型的编码器进行特征对齐(semantic preservation)。
- 直观理解:学生编码器负责“学深度”,教师编码器负责“保语义”,两者的特征通过约束保持一致。
- 解码器 (Decoder)
- 解码器接收编码器提取的多尺度特征,通过逐步上采样与融合,预测出稠密的深度图。
- 为适配强大的 ViT 编码器,解码器结构保持轻量化,以保证推理效率。
- 标注数据分支
- 输入:带人工深度标签的图像。
- 过程:图像经过编码器–解码器,输出预测深度图。
- 监督:预测与人工标签进行监督约束(sup),确保模型在有标注场景中学到高质量的深度映射。
- 无标注数据分支
- 输入:大规模无标注图像。
- 教师模型:预训练教师模型为这些图像生成伪标签。
- 学生模型:在线学生模型(online student)经过编码器–解码器,预测深度图。
- 监督:学生预测与教师伪标签对比,作为学习信号。
- 强扰动 (S):在输入或特征层加入强扰动,迫使学生模型在“困难条件”下也要保持对齐,从而提升鲁棒性。
- 语义保持机制 (Semantic Preservation)
- 问题:深度估计任务如果只关注几何信息,可能会丢失图像的语义结构(例如物体类别、边界)。
- 解决:引入冻结的教师编码器,与学生模型的特征做约束(feature alignment loss),确保学生模型在学深度的同时保留丰富的语义先验。
- 好处:增强模型对复杂场景的理解能力,使其在未见过的场景下依然稳健。
📌 总结
Depth Anything 的网络结构是一个 双分支、教师–学生协同的编码器–解码器框架:
- 标注分支:用人工深度标签进行监督。
- 无标注分支:利用教师生成伪标签,通过强扰动训练学生模型。
- 语义保持模块:学生编码器与冻结教师编码器对齐,确保模型在学几何的同时保留语义感知。
一句话概括:
Depth Anything 在 MiDaS/DPT 框架基础上,融合了“标注监督 + 伪标签蒸馏 + 语义保持”的多源训练结构,从而兼具几何准确性与泛化能力。
4、存在的重大缺陷
根据论文内容,Depth Anything 模型虽然在多种场景下表现优异,但仍存在一些重大缺陷,主要体现在以下几个方面:
- 尺度与绝对深度估计的限制 模型在相对深度估计上效果显著,但在需要精确尺度的任务(如自动驾驶、机器人导航)中,仍然缺乏鲁棒的绝对深度预测能力,需要依赖额外的微调或数据校准
- 对训练数据分布的依赖性 尽管作者强调模型在零样本场景下的泛化性,但实验结果显示,在某些特殊环境(如夜间、极端天气或低光照条件)下,深度估计仍然容易受到数据分布偏差的影响,表现不稳定
- 动态场景与遮挡问题 对于包含快速运动物体或复杂遮挡的场景,Depth Anything 的预测容易出现模糊或错误深度分布,这类问题在自动驾驶和视频场景理解中尤为突出
- 计算与存储开销 虽然提出了轻量化版本(如 ViT-S),但在完整模型(ViT-L)中,仍需要大量算力与显存资源,这对边缘设备或实时应用提出了较高的部署门槛
- 语义约束的不足 模型设计中通过冻结的 encoder 来保持语义一致性,但这种方法在高层语义理解与几何结构结合方面仍不够紧密,限制了深度估计在跨模态任务中的可扩展性
5、后续基于此改进创新的模型
🟢 Depth Anything V2 (2024)
- 想解决的问题:原版 Depth Anything 还是太依赖真实深度数据,而这些数据很难获取。
- 做法:
- 大量用 合成数据(电脑生成的场景)代替真实标注数据。
- 教师模型更强大,能生成更高质量伪标签。
- 再用 伪标注的真实图像做桥梁,让模型更好地适应真实世界。
- 效果:训练成本更低,预测更细致,在真实场景里也更靠谱。
👉 通俗理解:相当于“模拟考试”质量更高,学生在考场上也能发挥更稳。
🟢 Prior Depth Anything / Depth Anything with Any Prior (2025)
- 想解决的问题:Depth Anything 在绝对距离上还是不准,比如到底是 1 米还是 3 米,它说不清楚。
- 做法:
- 给模型加一点“度量提示”(metric prior),比如某些场景里少量的精确测量点(稀疏深度)。
- 模型先用这些提示来确定整体尺度,再推全图的深度。
- 效果:不仅能画出相对深度,还能更准确地预测实际的物理距离。
👉 通俗理解:就像画地图时,你只知道大概的形状,但加上几个路标(度量先验),就能标出真实的比例尺。
🟢 HybridDepth (2024)
- 想解决的问题:Depth Anything 只靠单张图像,有时候尺度和细节不够稳定。
- 做法:
- 加入 焦点信息(相机镜头对不同焦点的模糊/清晰变化),这种信号天然带有深度信息。
- 再结合单张图像的深度先验。
- 效果:对细节和尺度的预测更好,特别适合实际设备(相机/手机)应用。
👉 通俗理解:像拍一组虚化照片(前景清晰、背景模糊),再结合普通照片,拼出更精准的深度。
📌 总结(类比版)
- Depth Anything V1:用大量无标注图像学深度,泛化能力强。
- Depth Anything V2:模拟考试更高质量(合成数据+伪标签),真实考试表现更稳。
- Prior Depth Anything:在地图上加“比例尺”,能预测更准的真实距离。
- HybridDepth:用相机的焦点特性 + 普通图像,提升细节和尺度。