MiDaS(2020):迈向鲁棒的单目深度估计:混合数据集实现零样本跨数据集迁移,零样本泛化能力”极强,广泛用作预训练 backbone
导出时间:2025/11/24 09:04:09
1、研究背景与动机
- 研究背景
单目深度估计(Monocular Depth Estimation, MDE)是计算机视觉中的核心任务之一,它希望仅凭一张普通的 RGB 图像,就能预测出场景的三维深度信息。
这项技术在自动驾驶、机器人、AR/VR、3D 重建等应用中都极其重要。
然而,MDE 一直面临两个核心困难:
- 数据依赖问题
- 深度学习方法需要大量带有真实深度标注的图像来训练。
- 但现实中很难在大规模、不同环境下采集精准的深度数据。
- 各类数据集(室内 NYU、室外 KITTI、合成 Sintel 等)都有自身局限和偏差,无法覆盖“真实世界”的复杂多样性
- 。
- 泛化能力不足
- 在某个数据集上训练的模型,在这个数据集上表现很好,但换到新的环境或数据集就会“失灵”。
- 根源在于:不同数据集的深度标注方式不一致(尺度不同、基准不同、传感器差异),模型学到的知识难以迁移
- 研究动机
MiDaS 的作者提出:
要想让 MDE 真正“走向真实世界”,必须解决 跨数据集泛化 的问题。
他们的思路是:
- 融合多种数据集:利用多个互补来源(室内/室外、静态/动态、合成/真实),而不是依赖单一数据集。
- 设计鲁棒损失函数:提出对尺度和位移不敏感的损失,让模型能同时学习来自不同数据集的监督信号。
- 引入新型大规模数据源:比如从 3D 电影中提取高质量立体图像对,获得前所未有的多样化深度训练数据
- 验证零样本泛化:用在训练中“完全没见过”的数据集来测试模型,以模拟真实部署场景。
👉 总结一句:
MiDaS 的研究动机是 突破数据集偏差与尺度不兼容的限制,通过混合多源数据和鲁棒训练方法,打造能在各种新环境中泛化的单目深度估计模型。
2、核心创新点
① 跨数据集混合训练 (Mixing Datasets)
- 问题:单一数据集训练 → 过拟合,难以泛化。
- 创新:首次将多个来源(NYU、KITTI、Make3D、Sintel、3D 电影等)组合在一起训练。
- 效果:模型学到更普适的深度表示,显著提升跨域泛化能力。
② 尺度与位移不变的损失函数 (Scale-and-Shift Invariant Loss)
- 问题:不同数据集的深度尺度和基准不一致,无法直接统一训练。
- 创新:提出新的训练目标,仅关注深度的相对结构而非绝对数值。
- 效果:避免尺度冲突,使模型能够同时从不同数据集受益。
③ 引入全新大规模训练数据 (3D 电影)
- 问题:现有深度数据集数量有限,场景覆盖不够。
- 创新:利用 3D 立体电影,自动提取数百万对立体图像生成深度数据。
- 效果:极大扩充了训练数据的多样性,提升模型“见多识广”的能力。
④ 零样本泛化评估 (Zero-shot Generalization)
- 问题:过去方法只在训练过的数据集上测试,无法反映真实泛化能力。
- 创新:MiDaS 在从未见过的数据集上直接测试,作为评估标准。
- 效果:证明模型能在新场景下稳健工作,更接近真实应用需求。
⑤ 灵活的网络架构设计
- 创新:使用成熟的 ResNet 作为 backbone,再加上特定解码结构。
- 意义:为后续更强大的骨干网络(如 Vision Transformer)打下基础,MiDaS 后续版本演化为 DPT 等模型。
3、模型的网络结构
总体结构:Encoder–Decoder 框架
MiDaS 的网络结构采用了经典的“编码器–解码器”模式。
- 编码器 (Encoder):负责从输入图像中提取多层次的特征。
- 解码器 (Decoder):负责把特征逐步还原成与输入分辨率一致的深度图。
这就像一个“翻译器”:
- 编码器先把图像“翻译成”高维语义特征;
- 解码器再把这些特征“翻译回”深度图。
编码器(Encoder)
- 采用 ResNet-50 / ResNet-101 / ResNeXt-101 / DenseNet-161 等主流骨干网络
- 所有编码器都在 ImageNet 上进行过预训练,以确保具备强大的特征提取能力。
- 作者还测试了 弱监督预训练(WSL)的 ResNeXt-101,这种模型在大规模弱标签数据上训练过,再在 ImageNet 上微调,表现更佳
👉 专业意义:编码器就像“大脑皮层”,选择更强大的 backbone 可以显著提高深度预测效果。
解码器(Decoder)
- 解码器部分相对轻量,主要通过逐步上采样和融合高低层特征,生成最终的深度图。
- 作者在论文中指出:不同于某些复杂的多分支设计,MiDaS 更注重训练策略和损失函数,解码器结构保持简洁。
👉 形象理解:解码器就像“放大镜”,把编码器抽象的特征逐步放大、还原成直观的深度图。
多尺度特征融合
- 在解码过程中,MiDaS 会融合来自不同层的特征(低层捕捉细节,高层捕捉全局结构)。
- 这样能同时保证局部纹理细节和整体几何一致性。
👉 比喻:就像画画时既要注意整体轮廓(远景),又要画好细节(近景)。
预训练与微调策略
- 实验发现:预训练至关重要。如果用随机初始化的 ResNet-50,性能比预训练版本低约 35%
- 因此,MiDaS 在预训练编码器基础上进行微调,并在多个混合数据集上训练。
模型变体
- 小模型:基于 ResNet-50,轻量、推理速度快,但性能也超过了许多传统方法
- 大模型:基于 ResNeXt-101(WSL),精度最高,适合作为研究或工业应用的 benchmark
📌 总结(专业+通俗)
MiDaS 的网络结构就是一个 ResNet/ResNeXt 编码器 + 简洁解码器 的框架:
- 编码器 = 强大的“特征提取大脑”;
- 解码器 = 把“抽象语义”翻译成深度图的小助手;
- 多尺度特征融合 = 同时理解“局部细节”和“全局结构”;
- 强预训练保证了模型“见多识广”,小模型快,大模型准。
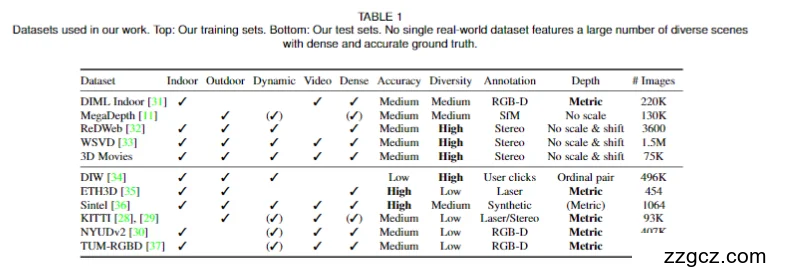
4、存在的重大缺陷
- 数据层面的不足
- 依赖多源数据,但覆盖不完整:尽管作者整合了室内、室外、合成和真实数据,还引入了 3D 电影,但现有数据仍未能覆盖多样化动态物体场景,例如人群密集、快速运动等环境。
- 公开数据集受限:所有公开数据集都存在偏差和缺失,难以全面代表真实世界的复杂性
- 深度标注仍是瓶颈:高质量大规模真实深度数据采集仍然困难,MiDaS 依然依赖间接或弱标注数据(如序数关系、视差),限制了模型的绝对深度精度
- 模型表现的缺陷
- 细节缺失与错误预测:在一些复杂纹理或绘画、素描等非真实图像上,MiDaS 的相对深度预测会出现细节缺失或局部错误(论文中的 failure cases 已展示)
- 尺度一致性不足:虽然引入了尺度与位移不变的损失,但在需要绝对尺度精度的应用(如机器人导航、3D 重建)中,MiDaS 仍然难以保证数值准确。
- 训练与推理的局限
- 对计算资源敏感:大模型(如 ResNeXt-101 WSL)虽然精度高,但训练和推理开销大,不适合轻量化应用。
- 输入分辨率限制:MiDaS 采用固定的输入尺寸(例如长轴 384 像素)进行归一化,虽然保证了跨数据集训练的一致性,但在极端宽高比场景(如 KITTI 数据集的车载视角)仍会出现输入过小、预测精度下降的问题
- 泛化与鲁棒性不足
- 对未见数据仍有限制:虽然零样本测试证明了泛化能力,但 MiDaS 在完全陌生场景(如全新领域的数据集)上仍可能出现性能下降,因为数据集偏差和模型学习到的表示之间依然存在差距
5、后续基于此改进创新的模型
🟢 1. DPT (Vision Transformer for Dense Prediction, 2021)
- 改进点:把 MiDaS 的 ResNet 编码器换成 Vision Transformer (ViT),提出 Dense Prediction Transformer (DPT)。
- 创新:利用 ViT 的全局建模能力,显著增强了深度估计的全局一致性。
- 效果:DPT 在 MiDaS 框架下达到新的 SOTA,被认为是 “MiDaS + Transformer” 的版本。
- 应用:不仅用于深度估计,还能扩展到语义分割、人体姿态估计。
🟢 2. AdaBins (Adaptive Binning for Depth Estimation, CVPR 2021)
- 改进点:解决 MiDaS 在深度范围离散化上的不足。
- 创新:提出“自适应分箱 (Adaptive Bins)”机制,让模型动态学习不同场景下的深度分布,而不是固定划分。
- 效果:在 KITTI 和 NYU 上超越 MiDaS,特别提升了绝对尺度深度预测的准确性。
🟢 3. LeReS (Learning from Relative Depth and Surface Normals, 2021)
- 改进点:针对 MiDaS 只能利用稀疏或相对标注的问题。
- 创新:结合 相对深度标注 + 法向约束,增强了几何一致性。
- 效果:在室外场景(如 MegaDepth)上泛化能力更强,细节预测优于 MiDaS。
🟢 4. ZoeDepth (2023)
- 改进点:解决 MiDaS 在绝对尺度预测上的不足。
- 创新:提出一种 “Zero-shot Metric Depth” 框架(ZoeDepth),让模型不仅能跨数据集泛化,还能预测可度量的绝对深度。
- 效果:在多个零样本测试集上表现超越 MiDaS,首次把“MiDaS 的泛化能力”与“绝对深度精度”结合。
🟢 5. Depth Anything (CVPR 2024)
- 改进点:解决 MiDaS 在数据规模和鲁棒性上的限制。
- 创新:利用 1.5M 有标注 + 62M 无标注图像的大规模预训练,采用强大的 ViT 编码器。
- 效果:在零样本和少样本深度估计上全面超越 MiDaS/DPT,成为“深度领域的 CLIP”。
- 应用:在三维重建、AR/VR、机器人导航等真实场景里表现更佳。
📌 总结
基于 MiDaS 的改进路线可以理解为 四个方向:
- 更强的编码器 → DPT (Transformer 化)
- 更聪明的深度建模 → AdaBins (自适应分箱)
- 更多几何约束 → LeReS (引入法向/相对深度)
- 更贴近真实应用 → ZoeDepth (度量深度), Depth Anything (大规模预训练)