Attention U-Net(2018):引入注意力门机制,胰腺影像分割必看经典
导出时间:2025/11/23 20:33:18
1、介绍
同学们,今天这节课,我们不谈艰深的公式,而是用一个“找宝藏”的比喻,把整篇论文串起来讲清楚。大家只要跟着故事走,就能明白“注意力门控(Attention Gate,AG)”到底解决了什么问题,又为什么好用。
一、故事开场:医学影像的“寻宝游戏”
想象你是一名探险家,手里有一大堆CT片子(好比一张巨大的藏宝图),任务是找到每个人的胰腺(宝藏)。
- 传统做法(手工标注):用放大镜一寸寸找,费时费力,还容易看花眼。
- 自动化做法(CNN):训练一只“电子猎犬”(CNN),让它自己去找宝藏。
早期猎犬(FCN、U-Net)已经很聪明,但遇到两个难题:
- 宝藏大小差异巨大:有的胰腺像苹果,有的像葡萄。
- 背景干扰严重:周围器官(胃、肝脏)的灰度值跟胰腺太像,猎犬容易分心。
二、级联CNN:多猎犬接力,但浪费体力
为了让猎犬更专注,前辈们设计了“级联框架”:
- 第一只猎犬(粗模型)先画个大致圈:“宝藏可能在这一块!”
- 第二只猎犬(细模型)再进圈精细搜索。
问题:每一只猎犬都要从头闻一遍味道(提取低级特征,如边缘、纹理),相当于重复劳动——计算冗余、参数爆炸。
三、注意力门控(AG):给猎犬一副“透视镜”
我们的创新很简单:给猎犬一副能自动调焦的透视镜(AG)。
- 训练阶段:透视镜和猎犬一起长大,无需额外老师(无额外监督)。
- 测试阶段:透视镜会瞬间生成“软区域建议”(类似高亮显示),告诉猎犬:“看这儿,别管背景!”
好处:
- 省体力:不再需要多只猎犬接力,一只就能搞定。
- 省资源:透视镜只是个小配件,增加的计算量微乎其微。
- 更精准:抑制无关区域(比如胃的干扰),胰腺边缘看得更清。
四、实验验证:最难的胰腺分割挑战
为了证明透视镜好用,我们选了CT胰腺分割这个“地狱级副本”:
- 难点:胰腺边界模糊,形状大小不一,连资深医生都头疼。
- 数据:TCIA胰腺CT-82(82例)+ 多类腹部CT-150(150例)。
结果:
- 在标准U-Net上加透视镜(即“注意力U-Net”)后,精度持续提升,且无需任何外部定位模型,直接达到业界顶尖水平。
- 无论训练数据多还是少,透视镜都能稳定发挥作用(小数据场景尤其惊喜)。
2、注意力U-Net的讲解
什么是注意力U-Net?
注意力U-Net是一个改进版的U-Net模型,专门用于图像分割(比如医疗影像中分离出器官或病变区域)。它像一个“聪明的小助手”,能更专注地识别图像中的重要部分,而不是平均对待所有信息。它的核心是加入了“注意力机制”,让模型更敏感地捕捉前景像素(比如我们要分割的目标区域)。
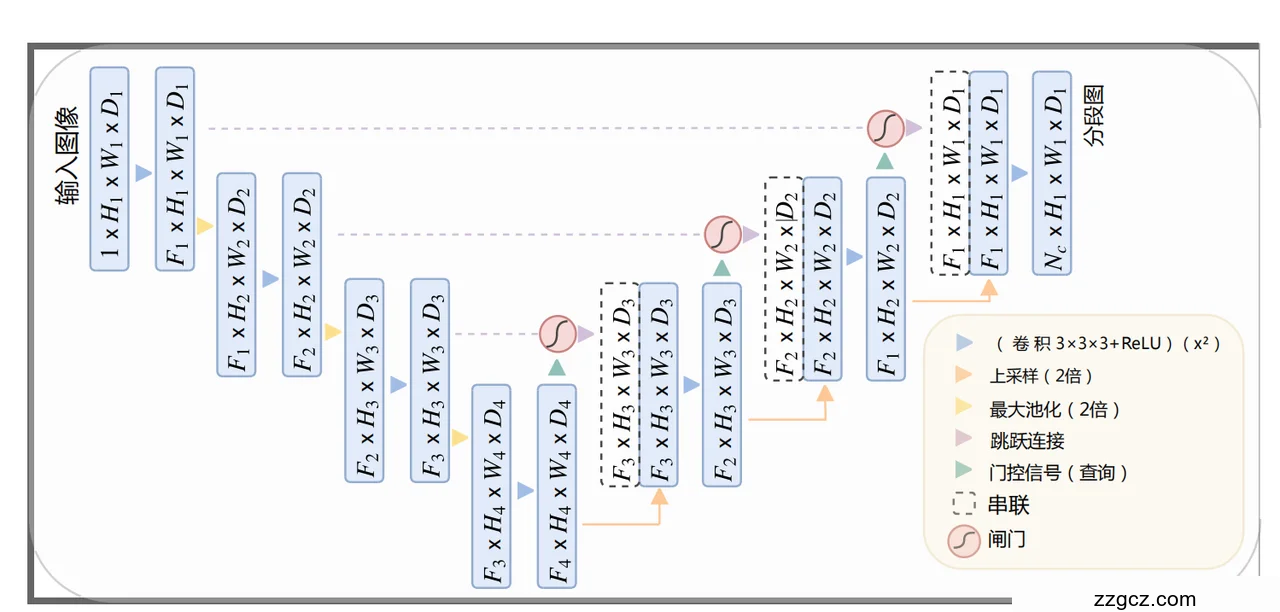
模型结构(看图1)
- 编码过程(左边部分)
- 输入图像先经过编码网络,像“过滤器”一样逐步处理。
- 每层都会用卷积(W)和激活函数(比如ReLU)处理数据,同时图像尺寸会缩小一半(比如从H1到H4,尺寸变成原来的1/8)。
- 这就像把大图逐步压缩成小图,但保留关键特征。
输入:模型接收一个输入图像,尺寸通常表示为 H×W×D H \times W \times D H×W×D(高度、宽度、深度),深度可能代表通道数(如RGB或医学影像的模态)。逐步下采样:- 图像通过卷积层(标记为 W1,W2,… )和激活函数(如ReLU)处理后,尺寸逐步减半。
- 比如,初始特征图 H1 H_1 H1 经过两次卷积和池化后变成 H2=H1/2 ,再变成 H3=H1/4 ,直到 H4=H1/8 。
- 具体操作:
- 卷积用 3×3×3 核(图1标注),提取局部特征。
- 激活函数 )引入非线性。
- 下采样通常通过最大池化或步幅卷积实现,减少计算量同时保留重要信息。
- 输出特征:每层生成特征图 xl ,维度逐渐降低,但通道数(特征深度)增加(如 F1,F2,… ),从低级纹理到高级语义信息过渡。
- 解码过程(右边部分)
- 从小图开始,逐步“放大”回原大小(上采样),并用卷积和激活函数恢复细节。
- 但光靠解码不够聪明,所以引入了“跳跃连接”。
上采样:- 从 H4 H_4 H4 开始,特征图通过上采样(比如反卷积或插值)逐步恢复到原始分辨率。
- 每层上采样后跟卷积(W3,W4,…)和激活函数,细化细节。
- 比如,H4 上采样到 H3 ,再到 H2 ,最后到 H1 。
输出:- 最终输出是分割图,尺寸与输入相同,通道数 Nc 表示类别数(比如背景+目标器官)。
- 激活函数如Sigmoid或Softmax,用于像素级分类。
挑战:单纯上采样可能丢失细节,尤其是小目标或边界信息,因此需要跳跃连接补充。 - 跳跃连接和注意力门(AGs)
- 跳跃连接像“捷径”,把编码阶段的特征(比如H4)直接传给解码阶段(比如H3),避免信息丢失。
- 但这些特征里可能有“杂音”,注意力门(AGs)就像个“筛选器”,只让重要的特征通过。
- 它利用粗糙层级(比如H4)的上下文信息,决定哪些局部区域值得关注。
跳跃连接:- 编码器每层的特征图(Hl H_l Hl)通过“捷径”直接传到解码器对应层(见图1虚线)。
- 比如,H4 H_4 H4 传到解码器的 H3 H_3 H3 层,H3 H_3 H3 传到 H2 H_2 H2 层。
- 作用:弥补上采样的信息丢失,融合低层细粒度细节(边缘、纹理)与高层粗粒度语义(整体结构)。
注意力门(AGs):- 问题:跳跃连接传来的特征可能包含噪声或无关背景信息,影响分割精度。
- 解决:注意力门在拼接前过滤特征,只保留与任务相关的信息。
- 工作原理:
- 输入:跳跃连接的特征 xl(细粒度)和解码器粗粒度特征 g(上下文信号)。
- **计算注意力系数 α:
- 使用加性注意力机制(Additive Attention): qal,tt=ψT[σ1(WxTxl+WgTg+bg)]+bψ
- Wx∈RFl×Fint 是线性变换矩阵。
- g 从粗粒度层提取,包含全局上下文。
- σ1 是ReLU,ψ 和 bψ 是额外参数。
- 注意力系数: αli=σ2(qal,tt(xli,gi;Θatt))
- σ2(x)=11+e−x 是Sigmoid函数,输出 α∈[0,1] \alpha \in [0, 1] α∈[0,1]。
- 参数 Θatt 包括 Wx,Wg,bg,bψ,通过 1×1×1卷积计算。
- 使用加性注意力机制(Additive Attention): qal,tt=ψT[σ1(WxTxl+WgTg+bg)]+bψ
- 重采样:注意力系数用三线性插值调整到与 xl 相同网格,分辨率更高。
- 输出:特征加权,x^li=xli⋅αli ,只保留重要激活。
注意力机制的特别之处
- 网格式门控:不像传统方法用全局特征,注意力U-Net用网格式门控,能更精准地关注局部区域。比如,它能挑出图像中某个小病灶,而不是整个图像平均处理。
- 软注意力:它不像硬注意力(直接忽略不重要区域),而是柔和地调整关注力度,适合医疗影像这种需要细致预测的任务。
- 无复杂技巧:它不用自适应池化等复杂方法,依然能提升性能,简单又实用。
为什么比标准U-Net好?
- 标准U-Net对前景像素(目标区域)不够敏感,容易出错。
- 注意力U-Net通过注意力门提高了对前景的敏感度,实验证明在各种数据集上精度都比U-Net高,不需要靠复杂的手动调整。
通俗比喻
想象你在找一张照片里的猫。标准U-Net像随便扫一眼全图,可能分不清猫和背景。注意力U-Net就像戴上“透视镜”,先看大图大致方向(编码),然后聚焦猫的局部细节(注意力门),最后把猫完整画出来(解码)。这样就更准了!