DeepLab v3+(2018):基于空洞可分离卷积的编码器解码器在语义分割中的应用
导出时间:2025/11/23 20:33:05
1、研究背景与动机
(1)语义分割任务的核心挑战
语义分割的目标是给图像中的每一个像素分配一个语义标签(例如“人”、“车”、“道路”)。相比于分类或检测,它对细节的要求更高,不仅要识别物体,还要描绘清晰的边界。
在这一过程中,研究者遇到了两大难题:
- 多尺度上下文信息不足:物体可能大小差异极大,小猫和整栋楼都可能出现在图像中,模型必须理解全局背景与局部细节。
- 边界细节丢失:卷积网络在提取高层语义信息时,通常会通过下采样导致分辨率降低,从而丢失物体边界的清晰细节。
(2)已有方法的局限
- 空间金字塔池化(PSPNet, DeepLab 系列) 通过多尺度卷积或池化捕捉全局上下文,解决了“看得不够远”的问题,但在恢复物体边界时仍显粗糙
- 编码器-解码器结构(U-Net, SegNet) 通过对称的上采样路径逐步恢复分辨率,擅长还原清晰边界,但上下文信息不足,容易“看不清全局”。
换句话说,一个善于理解语义,但边界模糊;另一个边界清晰,但缺乏全局感知。
(3)DeepLab v3+ 的动机
研究者希望结合两类方法的优点:
- 借助 DeepLab v3 的空洞卷积 + ASPP 模块 → 捕捉丰富的多尺度语义信息;
- 引入解码器结构 → 弥补边界模糊的问题,使得分割结果更清晰;
- 进一步采用深度可分离卷积(Xception 改进版) → 在不显著增加计算量的前提下,提高模型速度和精度。
最终,DeepLab v3+ 的目标是:
👉 既能看清全局,又能抠清边界,同时保持较高的效率。
✅ 总结一句话:
DeepLab v3+ 的研究动机,就是要解决“只会理解,不会抠图”与“只会抠图,不懂语义”之间的矛盾,把上下文感知与边界细化统一到一个高效的框架中
2、核心创新点
(1)空洞卷积 + ASPP(继承与强化)
- 空洞卷积(Dilated Convolution) 通过在卷积核中引入“空洞”,在不增加参数量的情况下扩大感受野。这样模型可以同时看近处和远处,既捕捉局部细节,也获得全局上下文。
- ASPP(Atrous Spatial Pyramid Pooling) 在 DeepLab v3 中,研究者用多种不同采样率的空洞卷积并行提取特征,类似于“多副望远镜同时观察”,从而增强对多尺度目标的感知。 DeepLab v3+ 保留了 ASPP 模块,作为语义特征的核心提取器。
👉 贡献:保证了模型对大目标与小目标的兼容性。
(2)编码器-解码器结构的引入
- 问题:DeepLab v3 在全局感知上很强,但输出结果边界模糊,尤其是小目标或细长物体容易“糊掉”。
- 改进:DeepLab v3+ 增加了解码器模块,从高层语义特征逐步恢复分辨率,并与浅层的细节特征融合。
- 效果:边界预测更清晰,物体轮廓更准确。
👉 贡献:把 PSPNet/U-Net 里“细化边界”的思想,和 DeepLab 的“全局上下文”结合。
(3)深度可分离卷积(Xception Backbone 改进)
- 为了提升效率,DeepLab v3+ 在 ASPP 和解码器中大量采用 深度可分离卷积。
- 这种卷积方式把标准卷积分解为 逐通道卷积 + 逐点卷积,大幅降低计算量,同时保持精度。
- 与传统卷积相比,能在 不显著增加 FLOPs 的情况下训练更深更强的网络。
👉 贡献:在精度和效率之间取得平衡,使 DeepLab v3+ 更易落地应用。
(4)强大的可扩展性
- DeepLab v3+ 并不是一个“单一模型”,而是一套灵活的框架。
- 研究者可以自由选择不同的主干网络(如 ResNet、Xception),甚至能在后续引入 Transformer 主干。
- ASPP + 解码器的组合成为后续分割模型的重要“标准模块”。
👉 贡献:提供了一种“通用可插拔设计”,奠定了未来很多改进的基础。
✅ 一句话总结:
DeepLab v3+ 的核心创新点在于 ——
把 DeepLab v3 的多尺度上下文感知(ASPP),与 U-Net 式的边界细化(解码器),以及高效的深度可分离卷积三者融合,最终实现“既能看全局,又能抠边界”的实例分割框架
3、模型的网络结构
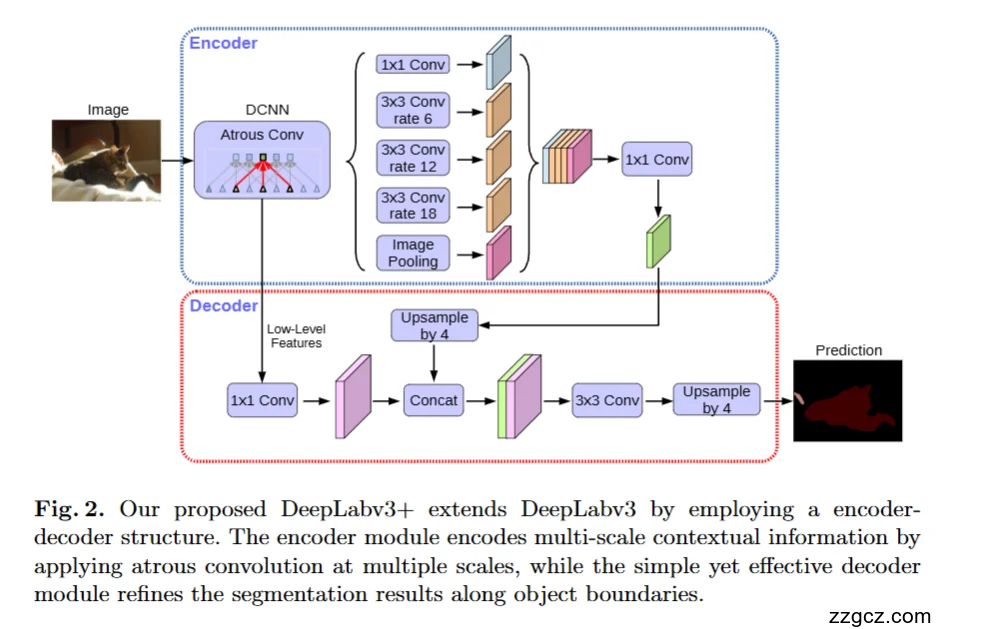
整个网络可以分为 编码器(Encoder) 和 解码器(Decoder) 两大部分:
🔵 编码器(Encoder):看懂全局语义
- DCNN 主干网络
- 输入图像先经过深层卷积神经网络(常用 ResNet、Xception),提取高层语义特征。
- 为了避免分辨率过低,主干里会用 空洞卷积(Atrous Conv) 替代部分下采样操作,保持更大特征图。
- ASPP 模块(Atrous Spatial Pyramid Pooling)
- 这是 DeepLab 的核心。
- 对高层特征图并行应用多种 不同采样率的空洞卷积:
- rate = 6 → 小感受野,看细节;
- rate = 12 → 中尺度;
- rate = 18 → 大感受野,看全局;
- 还额外加了 全局平均池化分支 → 提供整图的全局上下文。
- 这些结果拼接在一起,再通过
1×1 Conv融合,得到多尺度语义特征。
👉 总结:编码器负责“看懂是什么”,并且“既看局部又看全局”。
🔴 解码器(Decoder):还原边界细节
- 低层特征引入
- 从主干网络的浅层取出一份分辨率较高的特征(含更多边缘细节,但语义弱)。
- 用
1×1 Conv降维,避免通道数太多。
- 高低特征融合
- 将 ASPP 输出的高层语义特征 先上采样 ×4,使它和低层特征大小匹配。
- 两者进行 Concat 拼接,融合“语义信息”和“边界细节”。
- 卷积细化 & 上采样
- 拼接后的结果经过
3×3 Conv精细卷积,抑制噪声,细化边界。 - 最后再上采样 ×4,恢复到接近原图大小,输出逐像素预测结果(即分割掩码)。
- 拼接后的结果经过
👉 总结:解码器负责“把懂语义的粗糙图”加工成“边界清晰的分割图”。
⚙️ 整体流程类比
- 编码器:像一个懂得全局语义的“策展人”,能看懂整张图里有什么。
- 解码器:像一个“精修画师”,专门把轮廓线条描清楚。
- 最终两者合作 → 既知道这是只猫,也能把猫的毛边勾勒得很清楚。
✅ 一句话总结:
DeepLab v3+ 的网络结构是 “ASPP 编码器 + 轻量解码器” —— 编码器通过多尺度空洞卷积理解全局语义,解码器则补充边界细节,让分割结果既聪明又精细。
4、存在的重大缺陷
虽然 DeepLab v3+ 在语义分割任务中表现非常优秀(既能看全局,又能抠边界),但它仍存在一些明显的不足:
① 计算复杂度高,速度慢
- 空洞卷积 + ASPP 并行分支,再加解码器模块,使得计算量和显存消耗都比较大。
- 在高分辨率图像(如 Cityscapes 2048×1024)上,推理速度明显偏慢。
- 不适合移动端、实时应用(如自动驾驶、AR/VR 需要几十帧每秒)。
👉 问题本质:多尺度卷积并行计算,效率不足。
② 对边界细节仍然有限
- 虽然比 v3 改进了,但解码器仍然很“轻量”,输出分辨率只提升 4 倍。
- 对于细长物体(如电线、杆子)或小目标(如交通灯),分割边缘仍可能模糊。
- 本质上,它的边界恢复能力不如 U-Net 那种逐层解码。
👉 问题本质:边界恢复不彻底,精细结构容易丢失。
③ 上下文建模方式有限
- ASPP 虽然捕捉了多尺度信息,但它本质上是固定采样率的卷积。
- 它并不能真正建模像素之间的长程依赖关系。
- 在复杂场景(比如多个相似物体紧挨着)时,模型仍容易混淆。
👉 问题本质:依赖规则卷积,缺少全局自适应建模。
④ 工程依赖强,训练难度较高
- DeepLab v3+ 依赖较多技巧:
- 大批量训练(否则 BatchNorm 不稳定);
- 多尺度输入和测试增强;
- 精心挑选的 backbone(如 Xception)。
- 在资源有限的环境下,复现其最佳效果会比较困难。
👉 问题本质:对硬件与训练技巧要求高,不够“开箱即用”。
⑤ 仅限于语义分割,无法区分实例
- DeepLab v3+ 输出的是语义分割图:同一类别的像素会被涂成一样的颜色。
- 它无法像 Mask R-CNN 那样区分“这是第一个人,这是第二个人”。
- 在实际任务(如自动驾驶、人群检测)中,缺乏实例区分会成为瓶颈。
👉 问题本质:不具备实例感知,只能做类别级别的分割。
✅ 总结
DeepLab v3+ 的缺陷可以总结为:
“强但不快,细节有限,上下文建模固定,训练门槛高,且仅限语义级别”。
这也正是后续模型(如 HRNet、OCRNet、SegFormer、MaskFormer)改进的方向:
- 要么提升 速度与轻量化;
- 要么增强 边界和小目标分割;
- 要么引入 自注意力/Transformer 做更灵活的上下文建模;
- 要么扩展到 实例分割/全景分割。
5、后续基于此改进创新的模型
DeepLab v3+ 可以看作是“空洞卷积 + ASPP + 轻量解码器”的代表。它奠定了现代分割模型的一个重要范式,但由于其缺陷(速度慢、边界细节有限、上下文建模固定),后续大量工作在此基础上做了不同方向的改进。
(1)轻量化与实时分割
- BiSeNet 系列(2018, 2021) 双通路结构(语义路径 + 细节路径),在保持语义能力的同时提升推理速度。 针对 DeepLab v3+ 的“计算复杂度高、不适合实时”的缺陷。
- DFANet, Fast-SCNN 通过高效 backbone + 简化的多尺度结构,实现移动端或实时应用(如自动驾驶)。
👉 改进点:牺牲部分精度,换取速度和可部署性。
(2)边界与细节增强
- HRNet(2019) 通过保持高分辨率特征流(而不是像 DeepLab 那样依赖上采样)来增强边界与小目标分割效果。
- PointRend(2020) 引入逐点细化策略,把粗掩码逐步细化成高分辨率边界,克服 DeepLab v3+ 的“边界模糊”问题。
👉 改进点:解决细长物体、小目标边界模糊的问题。
(3)上下文建模的新方式(替代 ASPP)
- DANet(2018)、OCRNet(2019) 用自注意力机制(Non-local / Object-Contextual Representations)建模全局依赖,替代 ASPP 的固定卷积感受野。
- CCNet(2019)、GCNet(2019) 引入循环注意力/全局上下文模块,更灵活地整合全图信息。
👉 改进点:不再依赖“固定采样率的空洞卷积”,而是通过自注意力建模全局关系。
(4)全景分割与任务拓展
- Panoptic FPN(2019) 把 语义分割(像素级) 和 实例分割(目标级) 融合为 全景分割(Panoptic Segmentation)。 弥补 DeepLab v3+ 只能做语义分割的不足。
- MaskFormer / Mask2Former(2021, 2022) 用统一的 mask classification 思路,处理语义、实例和全景分割。 Transformer backbone 替代卷积,直接解决 DeepLab v3+ 在上下文建模上的不足。
👉 改进点:扩展到全景任务,用统一框架解决多种分割问题。
(5)Transformer 时代的延续
- SETR(2020) 首批基于 Vision Transformer 的语义分割模型,证明不依赖空洞卷积也能取得 SOTA。
- SegFormer(2021) 把轻量 Transformer backbone 与简洁解码头结合,在效率和精度之间取得很好的平衡。
- Mask2Former(2022) 完全抛弃 ASPP/卷积,采用 Transformer 统一处理语义、实例、全景三类任务。
👉 改进点:Transformer 替代 ASPP,解决长程依赖 + 灵活多任务。