Mask R-CNN(2018):当时的实例分割基线
导出时间:2025/11/23 20:32:16
1、研究背景与动机
在计算机视觉里,传统有两个经典任务:
- 目标检测:找到图像里有哪些物体,用边界框圈出来(比如有几个人、几辆车)。
- 语义分割:把图像中每个像素都分配一个类别(比如这是“人”的像素,那是“车”的像素),但是无法区分不同的实例。
实例分割比这两者更难:既要知道物体的位置(检测),又要把每个物体的轮廓“抠”出来(分割),还要能区分出这是“第1个行人”,那是“第2个行人”。
研究者希望有一个通用的框架,能够同时完成检测与逐像素分割,而且训练和使用都简单高效。于是,Mask R-CNN 应运而生。
2、核心创新点
Mask R-CNN 相比 Faster R-CNN(前一代检测框架)有三大关键创新:
- 多任务输出: 在原本的分类(是什么类别)和边界框回归(位置框)之外,额外增加一个 掩码预测分支,直接生成像素级的物体轮廓。
- RoIAlign 技术: Faster R-CNN 使用 RoIPool,但它在特征图和图像像素之间有“量化误差”,会导致掩码预测不够精准。 Mask R-CNN 提出 RoIAlign,取消了粗糙的量化操作,用插值方法保持像素级对齐,使得边缘轮廓更精准。
- 解耦分类和掩码预测: 掩码预测只负责“抠出形状”,不需要在像素上竞争类别归属,类别判定交给分类分支。这样训练更稳定,结果更干净。
3、模型的网络结构
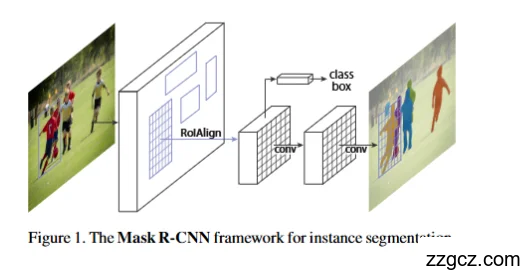
Mask R-CNN 的结构可以分为三部分:
- 骨干网络(Backbone) 常用 ResNet、ResNeXt,并结合 FPN(特征金字塔网络),提取多尺度特征图。
- 区域提议网络(RPN) 从特征图里生成候选框(RoI),预测可能有目标的位置。
- 三分支头部网络(Heads):
- 分类分支:预测物体类别。
- 边界框分支:精修候选框。
- 掩码分支:通过小型 FCN,为每个候选区域生成一个像素级掩码(例如 28×28),再映射回原图。
训练时用 多任务损失函数:分类损失 + 边界框损失 + 掩码损失。
简单比喻:
可以把 Faster R-CNN 想象成一个“物体检测器”,而 Mask R-CNN 就是在它后面接了一个“抠图工具”,能把目标抠出来。
4、存在的重大缺陷
虽然 Mask R-CNN 是里程碑模型,但也有一些不足:
- 速度偏慢: 两阶段架构 + 掩码分支,推理速度比 YOLO 等一阶段检测器慢,不适合实时应用。
- 掩码分辨率有限: 通常掩码分支只输出 28×28 的小掩码,细节边缘不够精细。
- 复杂场景仍然困难: 当目标高度重叠(比如人群、车流),掩码预测会出现错误或粘连。
- 计算资源需求大: 训练 Mask R-CNN 需要较多 GPU 内存,部署成本较高。
5、后续基于此改进创新的模型
Mask R-CNN 激发了很多后续工作:
- PANet (Path Aggregation Network) 改进特征融合路径,让信息流更高效,提升小目标分割效果。
- Cascade Mask R-CNN 多级级联预测,提高检测和分割精度,特别是在高 IoU 要求下。
- Hybrid Task Cascade (HTC) 把检测和分割任务级联在一起,互相促进,进一步提升效果。
- PointRend 改进掩码预测方式,采用逐点细化策略,使边缘分割更精细。
- YOLACT / SOLO / CondInst 新一代实时实例分割模型,放弃两阶段,直接端到端预测掩码,追求速度和精度平衡。
✅ 总结: Mask R-CNN 是实例分割的里程碑,把“检测 + 分割”优雅地统一在一个框架中。它的核心贡献是引入了 RoIAlign 和 并行掩码分支,让实例分割变得高效、通用。虽然存在速度和分辨率的瓶颈,但它为后续许多改进模型奠定了坚实的基础。