Mask2Former(2022):用于通用图像分割的掩码注意力掩码变换器,通用分割架构(语义!实例!全景)
导出时间:2025/11/23 20:34:50
1、研究背景与动机
(1)分割任务的多样性与割裂
论文开头指出,计算机视觉中有 语义分割、实例分割和全景分割 三种主要分割任务,它们通常被分别处理,导致方法设计复杂、难以统一 。
(2)MaskFormer 的贡献与局限
- 贡献:MaskFormer 提出了 统一的 mask classification 范式,证明了三类分割任务可以在一个框架下解决 。
- 局限:
- 它采用的 点积式掩码生成,表达能力不足。
- 掩码预测效果有限,对 小目标和细粒度边界 表现不佳 。
(3)作者的关键观察
- 为了更好地利用 mask query 与像素特征 的交互,论文提出要用 注意力机制 来直接增强这种联系。
- 相比单一的点积,masked attention 能让每个 query 聚焦于属于自己的区域,从而得到更准确的掩码 。
(4)Mask2Former 的提出
- 基于上述思考,作者提出 Mask2Former:
- 用 masked attention 取代 MaskFormer 的点积掩码生成。
- 让 mask query 直接在像素特征上施加注意力,实现更强的局部细节与全局语义建模。
- 动机:解决 MaskFormer 在边界建模、小目标分割上的不足,同时保持 统一框架 的优势 。
🔑 总结
Mask2Former 的研究动机是:
- 现有分割任务彼此割裂,缺乏统一模型。
- MaskFormer 提出统一范式,但其 掩码生成方式过于简单,导致性能瓶颈。
- 作者观察到:通过 masked attention 可以更强地建模 query 与像素特征的交互。
- 因此提出 Mask2Former,在继承 MaskFormer 统一性的基础上,解决其表达力不足的问题,实现 语义/实例/全景分割的全面提升。
2、核心创新点
1) 统一的 Mask Classification 框架延续
- 延续 MaskFormer 的思想:
- 将分割任务(语义、实例、全景)统一为 mask classification,即预测一组 (mask, 类别)。
- 不再为不同任务设计不同网络头,而是通过同一框架适配全部任务。 👉 创新点:保持了“任务统一”的优势。
2) Masked Attention 机制(核心改进)
- MaskFormer 中的掩码由 query 向量与像素嵌入做点积得到,表达能力有限。
- Mask2Former 提出 masked attention:
- 每个 query 对应一个动态的 mask,用这个 mask 作为注意力的空间权重,直接在像素特征上施加注意力。
- 这样,query 能够“聚焦”到自己相关的区域,生成更准确的掩码。 👉 创新点:显著增强了 query 与像素特征的交互,提升了小目标和边界建模能力。
3) 多尺度特征的解码器设计
- 使用 Pixel Decoder(带有多尺度特征) 作为输入,使 masked attention 可以在不同分辨率特征上交互。
- 结合 FPN-like 结构,既保留全局信息,又兼顾局部细节。 👉 创新点:在保持统一架构的同时,增强了多尺度适应性。
4) 任务无关、端到端训练
- 不需要额外的后处理(如 NMS、合并分支),输出直接是一组有标签的掩码。
- 使用 Hungarian Matching 一对一对齐预测与真实标注。 👉 创新点:端到端、任务无关,训练与推理流程简洁。
5) 在三类分割任务中均达到 SOTA
- 在 ADE20K(语义)、COCO(实例)、COCO Panoptic(全景)上,Mask2Former 都超过了当时的最佳方法。
- 说明这种改进不仅理论合理,而且在实践上效果显著。 👉 创新点:首次证明了 统一的 masked attention 框架 在三大分割任务中都能达到 SOTA。
🔑 总结
Mask2Former 的核心创新点可以概括为:
- 延续 mask classification 的统一框架。
- 提出 masked attention,提升 query–像素交互能力。
- 结合 多尺度特征,增强全局与局部建模。
- 端到端任务无关训练,无需额外后处理。
- 在语义/实例/全景三大任务上同时达到 SOTA。
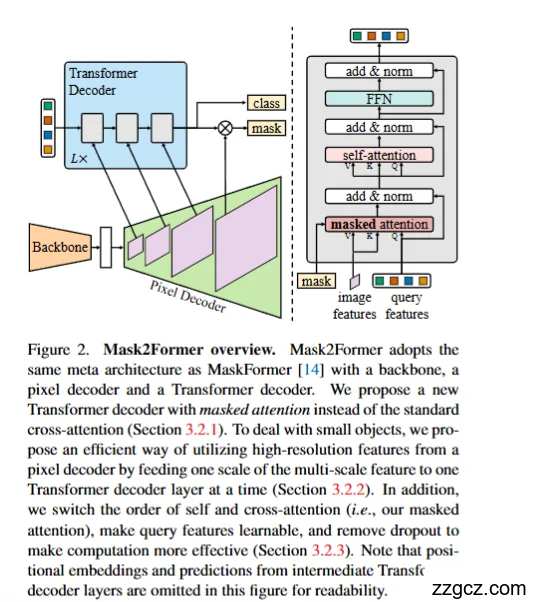
3、Mask2Former 的网络结构
整体上,Mask2Former 延续了 MaskFormer 的三大模块:
Backbone(主干网络) → Pixel Decoder(像素解码器) → Transformer Decoder(变换器解码器),
但在 Transformer Decoder 中引入 masked attention,这是最核心的升级。
A. Backbone(特征提取)
- 输入图像先经过 backbone(如 ResNet、Swin Transformer)。
- 得到多尺度特征图(例如 stride 4、8、16、32)。 👉 提供丰富的多尺度语义信息。
B. Pixel Decoder(像素解码器)
- 作用:把 backbone 的多尺度特征逐步融合,恢复更高分辨率。
- 输出:多尺度像素特征,用于后续的掩码预测。
- 与 MaskFormer 类似,但在 Mask2Former 中,这些特征会 分层送入 Transformer Decoder,以更好地利用高分辨率特征(尤其对小目标有帮助)。 👉 相当于“桥梁”,既保留全局语义,又恢复局部空间信息。
C. Transformer Decoder(核心创新)
这是 Mask2Former 的重点:它替换了 MaskFormer 的点积交互方式,引入 Masked Attention。
每个 decoder layer 包含:
- Self-Attention(自注意力)
- 在 query 之间交互信息。
- 确保不同候选 mask 互相感知,不至于预测重复区域。
- Masked Cross-Attention(掩码注意力)
- 传统 cross-attention:query 与整张特征图交互。
- Mask2Former:在 cross-attention 中引入 mask 作为权重,限制 query 只关注它负责的区域。
- 这样,每个 query “学会”专注于属于自己的图像区域,掩码边界更精准,小目标也更容易分割出来。
- Feed-Forward Network (FFN)
- 进一步非线性变换,提升表示能力。
- 残差连接 + LayerNorm
- 保持训练稳定性。
👉 关键升级点:Masked Attention
- 输入:query + 当前掩码预测(mask)。
- 输出:更聚焦于局部区域的特征更新。
- 每个解码层都会更新 query 表示和掩码预测,逐步 refine。
D. 输出层
经过多层 Transformer Decoder,得到:
- 类别预测:每个 query 对应的类别(或 no-object)。
- 掩码预测:每个 query 对应的二值掩码(通过像素特征点积 + sigmoid)。 👉 最终输出是一组 (mask, 类别) 对。
E. 任务适配
- 语义分割:多个 query 可能属于同一类别,最后把这些掩码组合在一起。
- 实例分割:每个 query 预测一个独立的实例。
- 全景分割:thing(物体)+ stuff(背景)同时预测,直接拼接即可。
🔑 一句话总结
Mask2Former 的网络结构是:
👉 Backbone 提取特征 → Pixel Decoder 恢复多尺度特征 → Transformer Decoder(带 Masked Attention)让 query 聚焦于对应区域 → 输出一组 掩码 + 类别,统一完成语义/实例/全景分割。
4、Mask2Former 的重大缺陷
- 计算与显存开销依然较大
- Masked Attention 比 MaskFormer 的点积更强大,但计算成本也更高:
- 每个 query 都要和整张图的像素特征交互(受 mask 引导)。
- 对高分辨率输入或大 batch 训练时显存压力大。
- 问题:推理速度慢,难以应用在实时场景(如自动驾驶)。
- 小目标仍然存在挑战
- 尽管引入多尺度特征和 Masked Attention 对小目标有帮助,但:
- 当目标极小或在噪声背景下,模型仍容易忽略。
- 部分原因是 query 数量固定,难以覆盖图像中所有潜在实例。
- 训练不稳定 & 超参敏感
- Hungarian Matching 仍然被保留,用于预测与真实掩码的分配。
- 但这种匹配在训练早期容易波动,导致收敛不稳定。
- 同时,Mask2Former 的效果对 学习率、mask query 数量、解码层数 都比较敏感。
- 掩码预测效率不足
- 掩码仍然通过 query 与像素嵌入点积方式得到,只是加了 Masked Attention引导:
- 本质上依然是“线性组合 + sigmoid”,表达能力有限。
- 对复杂形状(如细长边界、结构化物体)预测仍不够精细。
- 高分辨率场景的适应性差
- 在遥感、医学等需要大图像输入的场景下:
- Mask2Former 推理时必须切 patch 或缩放图像。
- 容易丢失全局一致性,显存占用过高。
- 缺乏跨模态与开放场景能力
- 与 CLIP 等视觉语言模型相比,Mask2Former 仍是 封闭类别 模型:
- 必须在训练时明确类别,无法很好地处理“零样本分割”。
- 在类别泛化(open-vocabulary segmentation)方面不足。
🔑 总结
Mask2Former 的重大缺陷主要有:
- Masked Attention 计算开销大,推理速度慢。
- 小目标和极端复杂边界仍然有性能瓶颈。
- Hungarian Matching 带来训练不稳定、超参敏感。
- 掩码预测机制仍然有限,缺乏更强表达力。
- 高分辨率场景下显存占用过高,不够友好。
- 缺乏开放词汇、跨模态能力,应用范围受限。
👉 一句话总结:
Mask2Former 在统一性和性能上远超 MaskFormer,但在效率、泛化性和复杂细节刻画方面仍有短板,这也推动了后续研究(如 MaskDINO、Open-Vocabulary Mask2Former)的发展。
5、基于 Mask2Former 的后续改进与创新模型
1) MaskDINO (CVPR 2023)
- 改进动机:Mask2Former 的分类与分割解耦不足,语义理解能力有限。
- 核心改进:
- 将 DINO 的 DETR-style 表征学习 融入 Mask2Former。
- 统一“物体检测 + 掩码预测”,提升物体级语义建模能力。
- 优势:在全景分割和检测任务上全面提升。 👉 可以看作 Mask2Former 的 检测增强版。
2) Open-Vocabulary Mask2Former (OV-Mask2Former)
- 改进动机:Mask2Former 只能处理封闭类别,缺乏泛化。
- 核心改进:
- 融合 CLIP / ALIGN 等视觉语言模型。
- 用文本描述代替固定类别标签,实现 零样本分割。
- 优势:能分割未见过的新类别,在开放场景中应用更广。
3) Efficient Mask2Former / Lite-Mask2Former
- 改进动机:Mask2Former 计算开销大,难以应用在实时场景。
- 核心改进:
- 减少 Transformer Decoder 层数。
- 轻量级 Pixel Decoder。
- 在部分方法中结合蒸馏/稀疏注意力,加速推理。
- 优势:更适合自动驾驶、移动端。
4) Med-Mask2Former(医学图像场景)
- 改进动机:Mask2Former 对高分辨率医学图像显存消耗大,边界刻画不足。
- 核心改进:
- 使用分层 patch 输入 + boundary-aware loss。
- 优化小器官、肿瘤等小目标分割。
- 优势:在 CT、MRI、病理切片分割中性能更优。
5) Mask2Former-Track / Video-Mask2Former
- 改进动机:原始模型针对静态图像,视频分割场景下缺乏时序建模。
- 核心改进:
- 引入时序注意力(temporal attention)。
- 在视频实例分割(VIS)中使用掩码跟踪机制。
- 优势:实现 视频级语义/实例/全景分割。
6) Hybrid & Extended Variants
- Mask2Former + GNN:在 query 之间引入图结构建模,加强物体关系理解。
- Mask2Former + Diffusion:结合扩散模型,提升 mask 生成的细节和鲁棒性。
- Mask2Former + Point Cloud:扩展到 3D 点云分割(如 LiDAR 感知)。
🔑 总结
基于 Mask2Former 的改进可以分为几个方向:
- 检测增强 → MaskDINO,把目标检测与分割结合。
- 开放词汇 → Open-Vocabulary Mask2Former,融合视觉语言模型,实现零样本分割。
- 轻量化 → Efficient/Lite-Mask2Former,更快更省资源。
- 领域适配 → Med-Mask2Former(医学),Point-Mask2Former(3D点云),Video-Mask2Former(视频)。
- 新技术融合 → 图神经网络、扩散模型等进一步提升表现。
👉 一句话总结:
Mask2Former 是统一分割的强基线,后续改进模型(MaskDINO、OV-Mask2Former、Med-Mask2Former 等)不断扩展它的适用性 —— 更强的语义、更快的效率、更广的任务、更开放的类别。