MaskFormer(2021):逐像素分类并非语义分割的全部,统一分割预测格式
导出时间:2025/11/23 20:34:41
1、研究背景与动机
(1)分割任务的碎片化困境
在计算机视觉中有多种分割任务:
- 语义分割(Semantic Segmentation):给每个像素打类别标签,不区分同类实例。
- 实例分割(Instance Segmentation):不仅要分出类别,还要区分同类的不同实例。
- 全景分割(Panoptic Segmentation):语义分割 + 实例分割的统一任务。
👉 但现有方法往往为不同任务设计不同的模型结构与预测方式:
- 语义分割常用 FCN + 解码器,输出每个像素的分类概率图。
- 实例分割常用 Mask R-CNN 类框架,输出 bounding box + mask。
- 全景分割则要把两者结果“拼接”,缺乏统一性。
结果是:三类分割任务彼此割裂,方法复杂,难以统一优化。
(2)像素级预测的不一致性问题
- 传统方法的输出形式大多是 逐像素分类(per-pixel classification)。
- 这种做法虽然直观,但在实例分割和全景分割中带来问题:
- 不同类别的 mask 没有统一表示,难以直接比较。
- 输出往往是密集的“概率图”,后处理复杂。
- 因此,需要一种新的 通用 mask 表达方式,既能表示类别,又能表示实例。
(3)作者的关键洞察
- 与其为不同任务设计不同输出,不如统一到一个中间表示:
- 把分割看作 预测一组 mask + 对应的类别标签。
- 每个 mask 可以是语义区域,也可以是实例区域。
- 这样一来,语义分割、实例分割、全景分割都可以看作 “mask classification” 的子任务。
(4)MaskFormer 的提出
- MaskFormer 的核心思想:
- 用 Transformer 编码器 提取图像特征。
- 用 mask 分类头 输出一组 “(mask, 类别)” 对。
- 不同的分割任务仅仅是对这些 mask 的不同解释。
- 这带来两个优点:
- 统一性:一个模型同时处理三类分割任务。
- 简洁性:避免复杂的后处理与多分支结构。
🔑 总结一句话
MaskFormer 的研究动机是:
👉 解决分割任务割裂、预测形式不统一的问题,提出一种 基于 mask 的统一表示,让语义分割、实例分割和全景分割都能在同一个框架下完成。
2、核心创新点
1) 统一的 mask 表示
- 不再像传统方法那样输出逐像素分类图,而是:
- 模型预测一组 mask(掩码)。
- 每个 mask 再对应一个 类别标签(或“无类别”)。
- 创新点:无论是语义分割、实例分割还是全景分割,都可以看作“预测一组有标签的 mask”,任务间差异被统一。
2) Mask Classification 任务形式
- 借鉴 DETR 的目标检测范式:
- 预测固定数量的候选(这里是 mask)。
- 用 集合匹配(Hungarian Matching) 将预测与真实标签对齐。
- 与目标检测类似,这种方式避免了后处理(如 NMS),输出端更简洁。
- 创新点:把 DETR 的 “object classification + box regression” 换成了 “mask classification”。
3) Pixel Decoder + Transformer Encoder
- 为了兼顾全局和局部特征,MaskFormer 使用两步特征提取:
- Pixel Decoder:对 backbone 特征进行空间增强(类似 FPN,保留高分辨率特征)。
- Transformer Encoder:建模全局关系,生成 mask query 表示。
- 创新点:既能保留像素级空间分辨率,又能建模全局上下文。
4) 任务无关的统一框架
- 在输出阶段,不再区分语义/实例/全景,而是统一为 mask 集合:
- 语义分割:多个 mask 可能共享同一类别。
- 实例分割:每个 mask 对应一个实例类别。
- 全景分割:mask 集合同时覆盖“东西(thing)”和“场景(stuff)”。
- 创新点:同一个模型参数,不需要任务专门设计。
5) 性能与简洁性的平衡
- 避免复杂的后处理(如 dense CRF、NMS、融合分支)。
- 端到端可训练,推理阶段只需输出 mask + 标签。
- 在 ADE20K(语义)、COCO(实例)、COCO Panoptic(全景) 等数据集上,性能优于或接近专门任务的 SOTA 方法。
3、模型网络结构(对应图中的三个模块)
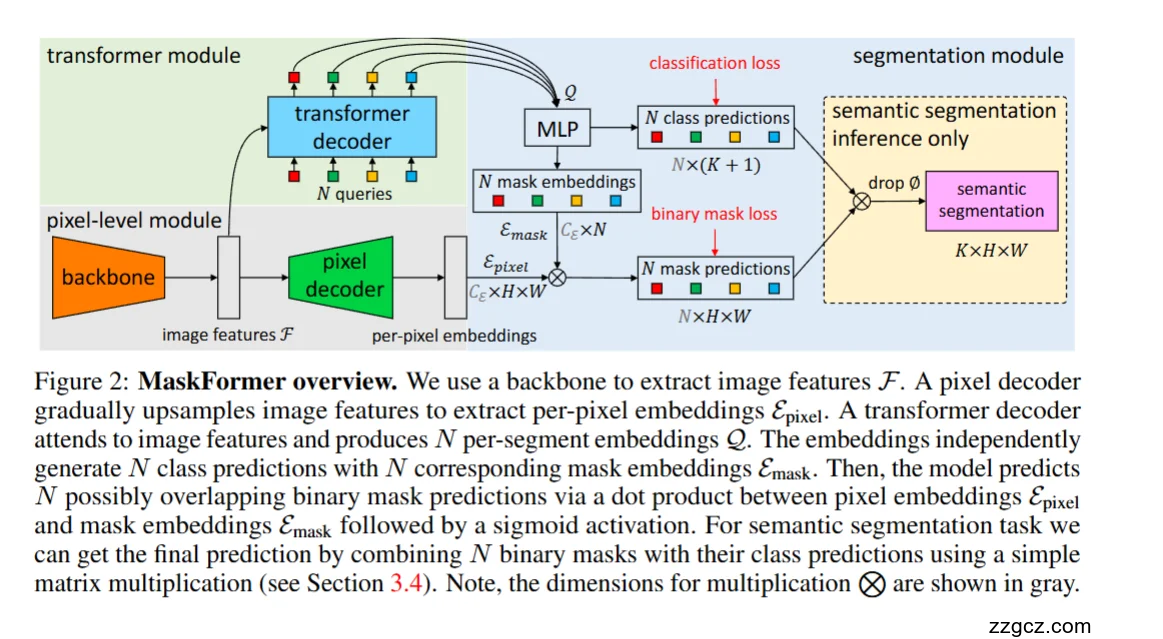
A. 像素级模块(pixel-level module)
作用:把主干特征转成高分辨率的“逐像素嵌入”,供后面生成二值掩码用。
流程:
- Backbone(ResNet/Swin 等)提取多尺度图像特征 F(通常主干步幅 S=32)。
- Pixel Decoder(轻量 FPN 变体):自顶向下逐级上采样并融合,使最终输出分辨率达到 stride 4;最后用 1×11\times11×1 卷积得到逐像素嵌入 Epixel∈RCE×H×W。 ——这一步提供了高分辨率空间信息,而复杂的跨位置上下文由 Transformer 负责,因此解码器可以做得很轻
B. Transformer 模块(transformer module)
作用:建模全局关系、产生“每个候选分割”的语义表示。
流程:
- 取主干/像素解码器输出的特征作为 key/value;
- 输入 N 个可学习查询(queries) 到 Transformer decoder,得到 N 个“分段嵌入” Q∈RCQ×N(一层或多层 decoder,默认 6 层;语义分割单层也能很好地工作)
- 用一个 MLP 将每个分段嵌入 QiQ_iQi 映射成两路:
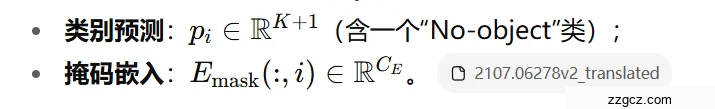
C. 分割模块(segmentation module)
作用:把“分段嵌入”变成真正的二值掩码,并(在语义分割时)合成为最终类别图。
流程:
- 掩码预测:把每个掩码嵌入与逐像素嵌入做点积并过 sigmoid,得到 N 张可能重叠的二值掩码
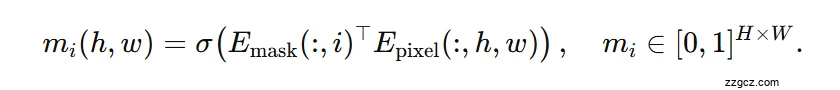
- 训练监督:
- 分类损失:对 pip_ipi 做交叉熵(含 no-object 类);
- 二值掩码损失:Focal + Dice 组合,对 mi监督;
- 一对一匹配:用 Hungarian(双向匹配) 按“分类代价 + 掩码代价”把预测集与标注片段配对(端到端、无需 NMS/框)
- 语义分割推理:把 N 张掩码 与 N 个类别分布 做一次矩阵乘法/加权和,得到每个像素对各类别的得分:
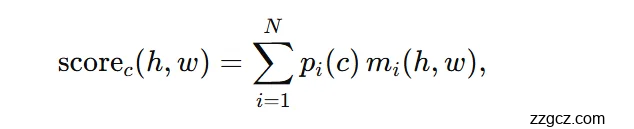
随后对类别维 argmax 得到 K×H×W 的语义预测;同时丢弃被判为 no-object 的查询。
形状与数据流(对应图中灰色尺寸标注)
- Epixe:CE×H×W
- Q:CQ×N → MLP →
- 类别矩阵:N×(K+1)
- 掩码嵌入矩阵:CE×N
- 掩码堆栈:N×H×W(可能重叠)
- 语义输出:K×H×W(只在语义分割任务上使用该汇聚)
设计要点与直觉
- “先像素、后查询”:像素解码器负责高分辨率空间表征;查询负责全局语义与区域,两者用点积自然结合为掩码
- 统一范式:同一套结构/损失即可同时做 语义分割/实例分割/全景分割(差别只在输出组装与评估),避免传统管线里“像素分类 vs. 实例掩码”的割裂
- 端到端:无框、无 NMS、用 集合匹配 消除重复预测,训练/推理简单高效
一句话回看图
左下 Backbone→Pixel Decoder 得到 Epixel;上方 Transformer Decoder 读特征并输出 N 个分段嵌入,经 MLP 分出 类别 与 掩码嵌入;右侧 点积+sigmoid 产生 N 张掩码,训练时用“分类+掩码”双损失与匈牙利匹配;语义分割推理把 N 个掩码×类别分布 做一次矩阵乘法即得到最终的 K×H×W 结果
4、MaskFormer 的重大缺陷
- 解码器计算复杂度较高
- MaskFormer 的 Transformer decoder 需要处理 N 个 query 与整张图像的特征交互。
- 在高分辨率输入和较大 NNN 时,计算和显存开销仍然很大。
- 与 SegFormer 那样的轻量解码器相比,MaskFormer 的推理速度较慢,不够适合实时场景。
- 对小目标和边界的刻画能力不足
- 掩码是通过 query 向量与逐像素嵌入点积得到的:
- 小目标或复杂边界可能需要多个 query 才能精确覆盖,但 MaskFormer 使用固定 NNN,容易遗漏。
- 结果是:在 COCO 等含有大量小物体的数据集上,小目标分割性能不够理想。
- 掩码预测的表达能力有限
- 每个掩码由一个低维向量与像素嵌入点积得到,本质是 线性组合:
- 优点是高效,但缺点是表达能力不足。
- 对复杂结构(如细长的树枝、器官血管)难以建模。
- 这也是后续 Mask2Former 引入更强 mask attention 的原因。
- 对不同任务的“统一”仍有不足
- 尽管 MaskFormer 提出统一的 mask 表示,但在 任务特定优化 上不够:
- 在语义分割上,它缺乏类似 SegFormer 那样的高效设计,速度劣势明显。
- 在实例分割上,相比 Mask R-CNN 系列,它在小目标和遮挡场景下表现欠佳。
- 换句话说,它更像是“框架层面的统一”,但实际任务效果未能全面超越专用方法。
- 匹配与训练的不稳定性
- 采用 Hungarian matching 进行一对一分配:
- 在训练早期,匹配容易不稳定,导致收敛较慢。
- 需要 carefully 设计损失函数(分类 + 掩码 Dice + Focal),否则性能下降明显。
- 高分辨率推理的适应性差
- 在遥感、大图像医学场景中:
- 像素解码器 + Transformer 的显存开销过大。
- 需要切 patch 推理,破坏了全局一致性。
🔑 总结
MaskFormer 的重大缺陷可以归纳为:
- 解码器复杂,推理效率低,不适合实时应用。
- 小目标与边界刻画能力不足。
- 掩码由线性点积生成,表达力有限。
- 统一性好,但在具体任务上性能不一定优于专用模型。
- Hungarian 匹配带来训练不稳定和计算额外开销。
- 对高分辨率图像不够友好。
👉 一句话总结:
MaskFormer 用“mask classification”实现了分割任务的统一,但在计算效率、细节精度和小目标表现上,仍存在显著短板,这也推动了 Mask2Former 等后续模型的改进。
5、基于 MaskFormer 的后续改进与创新模型
1) Mask2Former(CVPR 2022)
- 核心思想:引入 mask attention,替代了 MaskFormer 的“query 向量 + 像素点积”机制。
- 改进点:
- 每个 query 不仅产生一个嵌入,而是直接参与到像素特征的动态注意力计算。
- 显著提升了小目标与复杂边界的表达能力。
- 统一性更强:能同时处理 语义分割、实例分割、全景分割,并且性能大幅超越 MaskFormer。
- 可以认为是 MaskFormer 的 直接继任者。
2) Panoptic SegFormer (2022)
- 在 MaskFormer 思路上,进一步优化 全景分割。
- 创新:用 Transformer 同时建模 “things”(可数物体)和 “stuff”(背景区域)。
- 相比 MaskFormer,全景分割表现更好,尤其在 ADE20K、COCO Panoptic 上。
3) MedMaskFormer / MaskFormer-Medical (2022–2023)
- 针对医学图像分割(CT、MRI、病理图像)。
- 改进点:
- 更轻量的 pixel decoder(减少显存开销,适合 3D patch 输入)。
- 特定损失(Dice + Boundary loss)提升边界精度。
- 弥补了 MaskFormer 在医学小器官、小肿瘤分割上的不足。
4) Efficient MaskFormer / Lite-MaskFormer
- 动机:原版 MaskFormer 解码器计算开销大,难以实时部署。
- 改进点:
- 减少 Transformer decoder 层数。
- 使用轻量级 backbone(如 MobileNet、Swin-Tiny)。
- 在移动端或自动驾驶场景中更实用。
5) Open-Vocabulary MaskFormer
- 结合 CLIP / Vision-Language 模型,使 MaskFormer 能做 零样本分割:
- 即便目标类别没在训练集中出现,也能通过文本描述预测对应 mask。
- 解决了原始 MaskFormer 类依赖强、泛化不足的问题。
6) Hybrid Models(与 CNN/图神经网络结合)
- CNN + MaskFormer:在 pixel decoder 中加入卷积层,增强局部边界细节。
- Graph-MaskFormer:在 mask query 间引入图结构,提升物体间的关系建模。
- 这些工作增强了 MaskFormer 在细节与全局交互上的能力。
🔑 总结
基于 MaskFormer 的改进主要分为以下几类:
- 更强的解码机制
- Mask2Former:用 mask attention 取代点积,大幅提升性能。
- 任务优化
- Panoptic SegFormer:优化全景分割。
- MedMaskFormer:适配医学图像。
- 轻量化与高效化
- Efficient / Lite-MaskFormer:适合嵌入式与实时应用。
- 跨模态与开放词汇
- Open-Vocabulary MaskFormer:结合语言模型,实现零样本分割。
- 结构融合
- CNN/Graph 与 MaskFormer 结合,提升细节与关系建模能力。
👉 一句话总结:
MaskFormer 开启了“mask classification”统一分割的新时代,但后续的 Mask2Former、Panoptic SegFormer、MedMaskFormer 等模型在效率、精细度、跨模态和任务适配上不断改进,让它真正走向“更强、更广、更实用”。