PSPNet (2016):引入金字塔池化
导出时间:2025/11/23 20:31:46
用一张图来想象 PSPNet:先用大疆无人机“鸟瞰”整座城市(全局),再拉到“街区”(2×2),再看“街道网格”(3×3),最后低头看看“房间布局”(6×6)。把这四层视角的要点对齐、拼一起,再去给每一块地砖(像素)贴标签——这就是 PSPNet 的核心思路:用金字塔池化(PPM)把全局与局部上下文融进像素级预测。
1、研究背景和动机
复杂场景解析(语义分割)里有三类“老大难”问题:
- 上下文不匹配:仅看外观很像,就会把河上的“船”错当“汽车”;如果“知道这是河边场景”,错误就能少很多。PSPNet 直面这种缺全局常识的问题。
- 类别混淆:如“建筑物 vs. 摩天大楼”“田野 vs. 大地”等,外观极相似,需要更大范围的语义线索来消歧。
- 尺度极端:超大目标(占满画面)或超小目标(路牌、路灯)都容易漏检,单一感受野难以兼顾。
FCN/空洞卷积虽然扩大了感受野,但有效感受野远小于理论值,高层特征对真实全局仍不够敏感;仅用“全局平均池化”又会丢掉空间布局。于是作者提出:不是只要一个“全局向量”,而是要“多尺度分区的全局”——这就是 PPM 诞生的动机。
2、核心创新点
金字塔池化模块(PPM)
- 在最后一层高层特征图上,做四个尺度的分区池化:
1×1(全局)/ 2×2 / 3×3 / 6×6; - 每个分区池化后接
1×1卷积做降维(第 N 层通道约为原来的1/N),再双线性上采样回原尺寸,与主干特征拼接; - 这样既拿到全局语义,又保留了粗粒度的空间布局,比“只做全局平均池化”更能缓解错判与混淆。
深度监督(Auxiliary Loss)
- 在 ResNet 的
res4b22(stage4 末)分支出一个辅助分类头,训练时与主损失同时反传,常用权重 0.4; - 测试阶段丢弃辅助分支,仅保留主干。这样能让很深的网络(101/152/269)更稳地优化收敛。
实证与系统化细节
- 优化策略采用 poly 学习率(power=0.9),丰富的数据增强(随机缩放 0.5–2、镜像、旋转、部分数据集加高斯模糊)、多尺度测试等,给出可复现的训练配方。
结果速览(SOTA 时代性贡献):
- ADE20K:赢得 2016 ImageNet 场景解析挑战冠军;消融中平均池化优于最大池化,
PPM(1/2/3/6)明显优于仅全局池化。 - PASCAL VOC 2012:单模 mIoU 85.4%(MS-COCO 预训练设置),当时刷新记录。
- Cityscapes:精细+粗标注联合训练可达 80.2% mIoU。
3、模型的网络结构
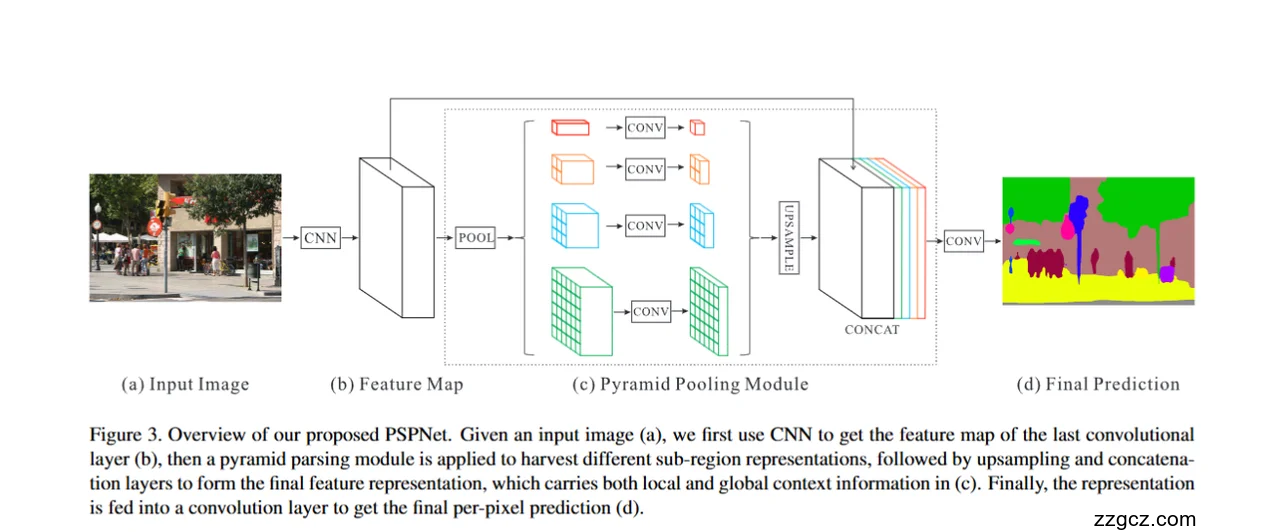
(a) 输入图像 → (b) 特征图
- 一张普通照片输入后,首先经过 CNN 主干网络(通常是 ResNet101/152 这种很深的卷积网络)。
- CNN 的作用就像是一个“信息提取器”,它把复杂的街景照片变成一个 压缩后的特征图。
- 这个特征图已经不再是彩色像素,而是“高维语义描述”——比如某些通道可能表示“这是垂直结构”,另一些表示“这是绿色区域”。
你可以理解为:从照片里“提炼出语义底稿”,但此时它的空间分辨率已经被缩小很多。
(c) 金字塔池化模块(Pyramid Pooling Module, PPM)
这是 PSPNet 的核心创新。图中间的 “POOL → CONV → UPSAMPLE → CONCAT” 就是它的全部流程。
- 多尺度池化(POOL)
- 把整张特征图切成不同格子(1×1、2×2、3×3、6×6),并在每个格子里做平均池化。
- 想象成“用不同大小的无人机视角”观察:
- 1×1:全局视角(整张图一块),只看“大环境”。
- 2×2:四分屏,看大致方位。
- 3×3:更细分的九宫格。
- 6×6:更局部的36小块。
- 卷积降维(CONV)
- 每个池化结果都经过
1×1卷积,把通道数压缩,去掉冗余信息。 - 这就像是“每个视角只保留关键信息摘要”。
- 每个池化结果都经过
- 上采样(UPSAMPLE)
- 由于池化后的特征很小,需要通过双线性插值放大回原尺寸,让它们能和主干特征对齐。
- 就像是“把小地图重新拉伸到全图大小”。
- 拼接(CONCAT)
- 把主干特征和四种尺度的“上下文特征”一起拼接,融合成一个大特征图。
- 这样既保留了局部细节(来自主干),又加上了全局上下文(来自 PPM)。
(d) 最终预测
- 拼接好的特征送入最后的卷积层,得到逐像素的预测分布。
- 这一步就像是“给图像中的每个像素都打上标签”,输出的彩色分割图就是语义分割结果。
例如:
- 黄色代表“马路”,
- 紫色代表“行人”,
- 绿色代表“树木”,
- 棕色代表“建筑物”。
总结类比
整条流程就像一个“多层次观察”的过程:
- CNN 提取底稿:相当于画出模糊草稿。
- PPM 多视角池化:像无人机飞到不同高度(1×1 全景 / 2×2 大区块 / 3×3 九宫格 / 6×6 细格),分别观察环境。
- 信息拼接:把不同高度的观察结果拼到草稿上。
- 最终预测:画师根据草稿 + 全局上下文,给每个像素上正确的颜色。
4、存在的重大缺陷
1. 速度与内存开销
- 以 ResNet-101/152/269 为干线,输出分辨率高(空洞保持 1/8),再叠 PPM,多尺度测试更“吃显存/算力”,实时性不足,移动端部署不友好。
边界细节受限
- PPM在高层做池化与拼接,强调语义一致性而非精细边界;直接双线性上采样的路径容易带来边缘发糊,对非常细碎的小目标仍可能欠敏感。
上下文是“分区池化”而非“自适应关系”
- PPM 把上下文分成固定网格聚合,空间关系是“粗分箱”级的,不建模像素对像素的长程依赖结构(后来注意力/非局部方法对此更灵活)。
强配方依赖
- 论文给出一整套训练技巧(poly LR、增强、多尺度测试等)才能跑到 SOTA,对工程化与资源有要求;在资源受限或数据分布差异较大的场景,复现曲线可能抖动更大。
5、后续基于此改进创新的模型
PSPNet 把“金字塔式上下文”刻进了分割社区的 DNA。随后很多方法要么直接复用/改造 PPM,要么替代 PPM 的上下文建模,要么在速度/边界上补齐短板。下面按主题列出代表性方向与典型模型(非完整清单):
A. 继续用/改良 PPM:作为“分割头”的标准件
- UPerNet(2018):FPN + PPM 头,成为通用语义分割头,广泛用于各类主干(含 Transformer)。
- PSANet(2018):作者后续工作之一,以点对点空间注意力替代固定池化,自适应聚合上下文。
- 多数开源框架(mmseg 等)都把 PPMHead 做成默认选项。
B. 用“可学习的多尺度”替代固定分箱
- DeepLabv3 / v3+(2017–2018):用 ASPP(空洞空间金字塔池化)在多空洞率上并行卷积,效果与 PPM 同宗同源;v3+ 再加轻量解码器提升边界。
- DANet / OCR / Non-local(2018–2020):通过自注意力或“对象级上下文”建模长程依赖,比固定池化更灵活。
C. 速度优先:轻量化与实时分割
- ICNet(2017,同一团队):多分辨率级联网络,结合金字塔思想与轻量特征,面向城市道路实时。
- BiSeNet 系列:分流结构(语义路径+细节路径),在保边界的同时提高 FPS。
D. Transformer 时代的延续
- SETR / Segmenter / SegFormer(2020–2021+):虽然主干换成 Transformer,但解码头常仍保留“金字塔式上下文模块”(PPM 或其变体)来汇集多尺度语义。
小结:PPM 作为“通用上下文聚合头”被复用;而“用可学习的注意力替代固定池化”“在边界与速度上补短板”这两条线,则分别催生了 DeepLabv3+/DANet/HRNet+OCR 与 ICNet/BiSeNet 等后继者。PSPNet 的思想已经从“一个具体模型”升级为“一个可插拔模块的范式”。(以上为对领域共识的梳理,便于你选型与延展。)