SAM (Segment Anything Model)(2023):万物皆可分割
导出时间:2025/11/23 20:34:57
1、研究背景与动机
(1)分割在视觉中的重要性
- 图像分割是计算机视觉的基础任务,广泛应用于 医学影像、自动驾驶、视频理解、AR/VR 等领域。
- 以往的分割模型(如 Mask R-CNN、SegFormer、Mask2Former)虽然在特定任务中表现优异,但都有 局限性:
- 需要针对具体任务设计网络结构。
- 依赖昂贵的逐像素标注。
- 泛化性差,难以迁移到未见过的数据分布。
(2)大规模基础模型的趋势
- 在 NLP 领域,大模型(如 BERT、GPT 系列)显示了 预训练 + 下游任务微调 的强大迁移能力。
- 在视觉中,CLIP、DINO 等也展示了类似的 可泛化表征。
- 但是,在 图像分割 领域,还没有出现能像 GPT 在语言中那样,具备“即拿即用 (promptable)”能力的基础模型。
(3)分割的挑战与痛点
- 昂贵的标注成本:像素级掩码的人工标注耗时长、成本高。
- 任务多样性:不同应用场景有不同的分割需求(语义、实例、交互式分割等)。
- 缺乏统一模型:现有分割模型往往只能解决单一任务,缺少“一次训练,多场景适用”的能力。
(4)SAM 的提出
论文提出 Segment Anything Model (SAM),目标是:
- 构建一个 通用的、大规模预训练分割模型。
- 通过 prompt(提示)机制 来灵活适配不同任务(例如:点击一个点 → 分割物体;画个框 → 分割区域)。
- 借助 大规模数据集 SA-1B(超过 10 亿掩码,1100 万张图像) 进行训练,确保模型具备极强的泛化能力。
(5)核心动机
- 借鉴 NLP 中的“基础模型”思路,打造 视觉分割的基础模型。
- 让模型不仅能解决现有分割任务,还能像 GPT 一样,通过简单提示完成“即插即用”的新任务。
- 减少昂贵的标注依赖,让分割模型更容易推广到各个实际应用场景。
🔑 总结
SAM 的研究动机是:
👉 传统分割方法依赖高成本标注,泛化性不足,难以统一不同任务。
👉 借鉴 NLP 和视觉大模型的成功经验,SAM 旨在打造一个 通用、可提示 (promptable)、大规模预训练 的分割基础模型,使得“分割任何东西”成为可能。
2、核心创新点
1) Promptable Segmentation(可提示分割)
- SAM 把分割任务转化为 prompt → mask 的映射:
- 输入提示(点、框、文本、粗 mask) → 输出目标区域的掩码。
- 创新意义:
- 模型不再是“固定任务”,而是一个“交互式工具”。
- 类似 NLP 中的 prompt learning,使分割模型具备“即拿即用”的能力。
2) 分割基础模型 (Segmentation Foundation Model)
- SAM 是首个提出 分割基础模型 概念的工作:
- 在超大规模数据集上预训练(SA-1B,10 亿掩码)。
- 预训练后不需要针对下游任务微调,就能在新场景中泛化。
- 创新意义:把 NLP 的“基础模型”范式成功迁移到分割领域。
3) 大规模数据集 SA-1B
- SAM 团队构建了 迄今为止最大规模的分割数据集:
- 超过 11 亿掩码,覆盖 1100 万张图像。
- 标注方式结合自动和人工交互,大幅降低了像素级标注成本。
- 创新意义:解决了分割数据标注昂贵的核心痛点,为模型提供强泛化能力。
4) 高效的三部分架构
- SAM 提出了一种 灵活且高效的三部分结构:
- Image Encoder(图像编码器):强大的视觉 backbone(ViT-Huge),提取图像 embedding。
- Prompt Encoder(提示编码器):把点、框、文本等输入转化为统一 embedding。
- Mask Decoder(掩码解码器):融合图像与提示 embedding,快速预测目标掩码。
- 创新意义:设计通用接口,支持多种提示形式输入。
5) 实时交互能力
- 解码器轻量化设计,每次只需几十毫秒即可输出分割结果。
- 用户可快速修改或叠加新的提示,模型立即更新分割结果。
- 创新意义:使得 SAM 不只是研究模型,而是一个可用的 交互式分割工具。
6) 强大的零样本泛化能力
- SAM 在未见过的数据分布和任务上也能直接工作:
- 例如医学图像、卫星遥感、艺术作品。
- 创新意义:首次让分割模型具备了“zero-shot”的通用性,像 GPT 在语言中那样迁移到新任务。
🔑 总结
SAM 的核心创新点可以归纳为:
- 提出 Promptable Segmentation,让分割任务变得灵活。
- 开创 分割基础模型 思路,借鉴 NLP 基础模型成功经验。
- 构建 超大规模数据集 SA-1B,极大缓解标注瓶颈。
- 设计 三部分通用架构(图像编码器 + 提示编码器 + 掩码解码器)。
- 实现 实时交互,具备可用性。
- 拥有 零样本泛化 能力,适应不同任务与领域。
3、SAM 的网络结构
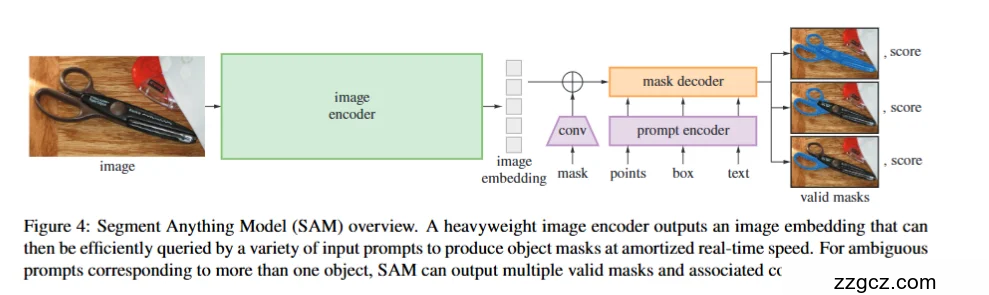
SAM 的设计非常简洁清晰,分为 三大核心模块:
图像编码器 (Image Encoder) → 提示编码器 (Prompt Encoder) → 掩码解码器 (Mask Decoder)。
A. Image Encoder(图像编码器)
- 输入:整张图像。
- 主干:使用 Vision Transformer (ViT-Huge),在大规模数据集 SA-1B 上预训练。
- 输出:高维的 图像 embedding,包含全局语义和局部细节。 👉 可以理解为“把图片压缩成一个强大的语义表示库”。
B. Prompt Encoder(提示编码器)
SAM 的核心创新之一就是“可提示分割”。
- 输入提示可以有多种形式:
- 点 (point):用户点击一个点,表示感兴趣区域。
- 框 (box):用户框出一个区域。
- 文本 (text):自然语言描述(实验性支持)。
- 粗 mask:已有的掩码进一步 refine。
- 处理方式:
- 点和框 → 编码成二维位置 embedding。
- 文本 → 使用文本编码器转换为语义 embedding。
- 输出:和图像 embedding 对齐的提示 embedding。 👉 可以理解为“把用户的意图翻译成模型能懂的语言”。
C. Mask Decoder(掩码解码器)
- 输入:图像 embedding + 提示 embedding。
- 机制:
- 使用 轻量级 Transformer 解码器,快速融合两者信息。
- 对提示的区域进行掩码预测。
- 输出:
- 多个候选掩码(valid masks)。
- 每个掩码附带一个 置信分数。
- 特点:
- 如果提示有歧义(例如一个框里有多个物体),SAM 会输出多个掩码供用户选择。 👉 可以理解为“结合用户提示,在图像语义空间里取出对应的区域”。
D. 整体流程总结
- 图像编码器:把整张图像转换成强大的 embedding 表示。
- 提示编码器:把用户输入(点/框/文本)转成对应的 embedding。
- 掩码解码器:融合两者,输出候选掩码 + 置信度。
- 交互式修正:用户可再次输入新的提示,模型实时更新掩码。
🔑 一句话总结
SAM 的网络结构 = 大规模 ViT 图像编码器 + 通用 Prompt 编码器 + 轻量解码器。
👉 它通过 “图像 embedding 作为知识库 + prompt 作为查询” 的方式,实现了真正的 promptable segmentation(可提示分割)。
4、SAM 的重大缺陷
1) 对高分辨率和小目标不友好
- 问题:SAM 使用 ViT-Huge 作为 backbone,输入图像通常要被压缩成较低分辨率 embedding。
- 影响:
- 小目标(如显微镜下的细胞、遥感中的小建筑物)往往丢失细节,分割效果差。
- 边界复杂的目标(细长结构、毛发、血管)刻画不精细。
2) 推理计算开销大
- 问题:
- 图像编码器非常庞大(ViT-Huge,6 亿+ 参数)。
- 在高分辨率输入或大规模应用场景(自动驾驶、医学成像)时,推理速度和显存占用过高。
- 影响:难以在 移动端 / 实时应用 中部署。
3) 标注偏差与数据覆盖问题
- 数据集 SA-1B 虽然规模空前,但标注是通过 半自动交互 完成的:
- 一些掩码质量不高,存在噪声。
- 数据主要来自自然图像(网页爬取),在医学、工业、遥感等专业领域覆盖不足。
- 影响:模型对专业场景泛化性有限。
4) 多物体歧义处理有限
- 当用户的提示(如框住一个区域)对应多个物体时:
- SAM 会输出多个候选掩码和置信度。
- 需要用户手动选择正确结果。
- 问题:缺乏自动 disambiguation(消歧)的机制。
5) 无法端到端执行复杂任务
- SAM 的目标是 “Segment Anything”,但它本质上仍是 前景提取模型:
- 不能直接执行语义分割(所有类别像素标注)。
- 不能自动完成实例分割或全景分割,需要额外任务逻辑。
- 结论:更像是一个 强大的交互式工具,而非任务完成型模型。
6) 跨模态能力有限
- 虽然支持文本 prompt,但并没有深度结合 CLIP/语言模型:
- 文本提示能力非常初级,语义理解有限。
- 在 open-vocabulary segmentation(开放词汇分割)上表现不足。
7) 对下游任务适配性不足
- SAM 在 zero-shot 分割任务上泛化性强,但在 下游专门任务(医学分割、遥感分析) 上:
- 直接迁移效果有限,需要结合微调或 LoRA 适配。
- 说明它的“万能性”存在边界。
👉 一句话总结:
SAM 是第一个通用分割基础模型,但它更像“交互式工具”,在效率、小目标、跨领域和跨模态上仍有显著不足。
5、基于 SAM 的改进与创新模型
SAM 引发了巨大的研究热潮,短时间内出现了大量改进版本,针对它在 小目标、推理速度、专业领域、边界质量、跨模态 等问题做了创新。
1) 轻量化与高效化
🔹 MobileSAM(2023)
- 改进动机:原始 SAM 的 ViT-Huge 太重,推理慢。
- 核心思路:将 ViT-Huge 替换为轻量级 ViT-Tiny,并结合蒸馏训练。
- 结果:在保持接近精度的同时,推理速度提升 60 倍,更适合移动端和实时应用。
🔹 FastSAM(2023)
- 改进动机:提高推理速度,适应低算力环境。
- 核心思路:简化解码器结构,直接预测目标区域,减少候选 mask 数量。
- 结果:大幅提升推理速度,但精度略有下降。
2) 边界与小目标优化
🔹 HQ-SAM(High-Quality SAM,2023)
- 改进动机:SAM 在边界复杂和小目标上分割精度差。
- 核心思路:增加 边界感知模块 和 高分辨率特征引导,提升 mask 细节质量。
- 结果:在医学、自然图像小物体任务上表现更好。
🔹 TinySAM
- 面向小目标场景的轻量化优化版,重点解决 SAM 在 显微镜图像、小物体检测 的不足。
3) 跨领域适配
🔹 MedSAM(2023)
- 改进动机:SAM 在医学影像(CT/MRI/病理切片)泛化性有限。
- 核心思路:用大规模医学分割数据微调 SAM,使其更好适配医学器官和病灶分割。
- 结果:大幅提升在医学下游任务中的表现。
🔹 SAM-Med3D / 3DSAM
- 扩展 SAM 到 3D 医学影像,解决 CT/MRI 中体素级分割的挑战。
🔹 RS-SAM(Remote Sensing SAM)
- 针对遥感图像,优化大尺度地物分割。
4) 跨模态扩展
🔹 Semantic-SAM(2023)
- 改进动机:原始 SAM 的 prompt 主要是点/框,文本理解有限。
- 核心思路:结合 CLIP 等多模态模型,增强 文本提示能力,实现更好的 open-vocabulary segmentation。
- 结果:支持“通过一句话分割目标”的能力。
🔹 SAM-CLIP / Language-SAM
- 深度结合视觉-语言预训练模型,使 SAM 能更强地支持 跨模态分割任务。
5) 任务特化型改进
- SAM-Adapter / SAM-LoRA:通过参数高效微调(Adapter/LoRA)快速适配下游任务。
- Video-SAM:扩展到视频分割,引入时序建模。
- SAM-Track:结合目标跟踪,实现跨帧一致的掩码输出。
- Open-Vocabulary SAM:结合大语言模型(LLM),支持零样本分割任务。
🔑 总结
基于 SAM 的改进模型主要分为五大类:
- 轻量化 → MobileSAM、FastSAM(高效推理、实时部署)。
- 细节优化 → HQ-SAM、TinySAM(提升边界和小目标分割)。
- 领域适配 → MedSAM、RS-SAM、SAM-Med3D(医学、遥感、3D)。
- 跨模态 → Semantic-SAM、Language-SAM(结合 CLIP/LLM,实现文本提示)。
- 任务扩展 → Video-SAM、SAM-Adapter、Open-Vocabulary SAM(视频、参数高效微调、零样本分割)。