SegFormer(2021):使用Transformer进行语义分割,简单而高效的设计
导出时间:2025/11/23 20:34:35
1、研究背景与动机
- 语义分割的主流困境
- CNN-based 方法(如 DeepLab、HRNet):
- 优点:局部特征提取强、结构成熟。
- 缺点:依赖复杂的 backbone + 解码器设计,还需要额外的模块(如 ASPP、OCR 等)来弥补局部感受野不足。
- 随着模型越来越复杂,计算开销大,且在高分辨率输入下效率低。
- Transformer-based 方法(如 ViT、SETR):
- 优点:天然擅长建模 全局依赖,有助于提升分割的语义一致性。
- 缺点:
- 直接使用 Transformer 处理大图 → 计算量爆炸。
- ViT 没有多尺度结构,难以捕捉小目标或细节信息。
- 现有的 Transformer 分割模型往往还要依赖复杂的解码器补救。
- 作者的观察
- 很多分割模型 过度依赖复杂的解码器:
- 编码器提取的特征往往不够“分割友好”。
- 需要设计 ASPP、FPN、OCR 等复杂解码头,提升鲁棒性。
- 这导致分割模型不仅笨重,还缺乏通用性。
- Transformer 的出现提供了机会:
- 如果能利用 Transformer 的 全局建模能力,同时结合 卷积的高效性和局部性,是否可以做一个 结构更简洁、性能更强的分割框架?
- SegFormer 的提出
- 作者提出 SegFormer,目标是:
- 高效:避免传统 Transformer 的计算瓶颈。
- 简洁:去掉复杂的解码器,仅用一个轻量级 MLP 融合头。
- 强泛化:适应不同场景(自动驾驶、自然场景、医学图像等)。
- 统一框架:一个 backbone + 一个简洁的解码器,就能在多个任务上取得 SOTA。
- 核心动机
SegFormer 的研究动机是:解决 CNN 模型对复杂解码器的依赖,以及 Transformer 模型计算开销大、缺乏多尺度特征的问题,提出一个既高效又简洁,同时兼顾全局语义和局部细节的语义分割框架。
2、核心创新点
- 分层式 Transformer 编码器(Hierarchical Transformer Encoder)
- 提出 Mix Transformer(MiT) 作为 backbone:
- 分层结构:逐步降低分辨率、增加通道数,类似 CNN 的金字塔。
- 局部注意力:在小范围内计算自注意力,避免全局注意力的计算爆炸。
- 重叠 patch 划分:不同于 ViT 的“硬切分”,MiT 使用重叠 patch,更好地捕捉边界和细节。
- 创新点:结合 CNN 的多尺度特征提取和 Transformer 的全局建模。
- 极简解码器(Lightweight All-MLP Decoder)
- 不同于 DeepLab/HRNet/SETR 那样需要复杂的 ASPP、OCR 等解码头。
- SegFormer 的解码器只用一个 MLP 融合模块:
- 将不同层次的特征映射到相同维度。
- 上采样后直接拼接、融合,得到最终分割图。
- 创新点:去掉繁琐的解码器,提升简洁性与效率。
- 全局与局部信息的平衡
- MiT 编码器:通过 局部注意力 + 分层特征 捕捉全局依赖和细节。
- Decoder:通过 MLP 融合 直接利用多层特征,保持全局一致性,同时保留局部精度。
- 创新点:在保持高效性的前提下,兼顾小目标和大场景的分割。
- 高效性与泛化能力
- SegFormer 在设计时 不依赖卷积算子(除了 patch embedding),几乎纯 Transformer 架构。
- 但计算复杂度和参数量大幅低于 SETR、ViT-based 分割器。
- 在 ADE20K、Cityscapes、COCO-Stuff 等 benchmark 上都达到了 SOTA,同时泛化到医学和遥感数据也表现强劲。
- 创新点:首次证明了“纯 Transformer + 极简解码器”就能在分割任务中超越 CNN 与混合模型。
- 可扩展性
- 作者设计了不同大小的 MiT(B0~B5),对应轻量级到大型任务:
- B0/B1 可用于移动端/实时分割。
- B4/B5 在高精度场景表现突出。
- 创新点:同一架构适配多种硬件和应用场景,具备良好的 scalability。
🔑 总结一句话
SegFormer 的核心创新点在于:
👉 用 分层式 Mix Transformer 编码器 提取多尺度特征,配合一个 极简 MLP 解码器,实现了 高效、简洁、强大且可扩展的语义分割框架。
3、模型网络结构
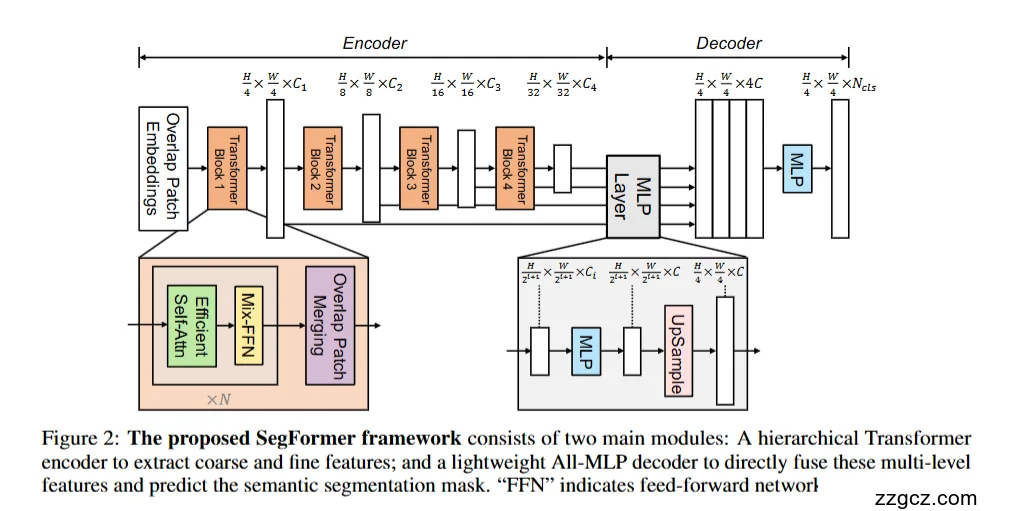
SegFormer 由 编码器(Encoder)+ 解码器(Decoder) 两部分组成,目标是:编码器提取多尺度特征,解码器极简融合,直接生成分割图。
(1)输入与 Patch Embedding
- 输入图像大小为 H×WH \times WH×W。
- 首先经过 Overlap Patch Embedding(重叠 patch 划分):
- 不像 ViT 那样硬切分,这里是带有重叠的卷积操作。
- 这样既能减少边界信息丢失,也保留局部连续性。
- 输出第一个特征图,分辨率为 H4×W4\frac{H}{4} \times \frac{W}{4}4H×4W,通道数为 C1C_1C1。
(2)编码器(Hierarchical Transformer Encoder)
SegFormer 使用 Mix Transformer(MiT) 作为编码器,它是分层结构,包含四个阶段:
- Stage 1
- 输入:H4×W4×C1\frac{H}{4} \times \frac{W}{4} \times C_14H×4W×C1。
- 包含多个 Transformer Block(注意力 + FFN)。
- 输出保持相同分辨率。
- Stage 2
- 先做 Patch Merging → 降采样为 H8×W8\frac{H}{8} \times \frac{W}{8}8H×8W,通道数增加到 C2C_2C2。
- 再经过若干 Transformer Block。
- Stage 3
- 再次 Patch Merging → 分辨率变 H16×W16\frac{H}{16} \times \frac{W}{16}16H×16W,通道数变 C3C_3C3。
- 接 Transformer Block。
- Stage 4
- 最后一次 Patch Merging → 分辨率 H32×W32\frac{H}{32} \times \frac{W}{32}32H×32W,通道数 C4C_4C4。
- 接 Transformer Block。
👉 这样得到一个 多尺度特征金字塔(4 层),既有高分辨率的细节特征,也有低分辨率的全局特征。
(3)解码器(All-MLP Decoder)
与以往复杂的解码头不同,SegFormer 的解码器 极其简洁:
- MLP 映射
- 将每一层特征(H32\frac{H}{32}32H、H16\frac{H}{16}16H、H8\frac{H}{8}8H、H4\frac{H}{4}4H)通过 MLP 投影到相同的维度 CCC。
- 上采样到统一尺度
- 把所有特征都上采样到 H4×W4\frac{H}{4} \times \frac{W}{4}4H×4W。
- 特征融合
- 把四个尺度的特征拼接/相加,得到融合特征。
- 分类头(MLP Layer)
- 再经过一个轻量级的 MLP,预测每个像素的类别。
- 输出分辨率为 H4×W4×Ncls\frac{H}{4} \times \frac{W}{4} \times N_{cls}4H×4W×Ncls。
- 最终可进一步上采样回 H×WH \times WH×W,得到分割图。
(4)核心设计理念
- 编码器:通过分层 Transformer(MiT)高效提取多尺度特征。
- 解码器:只用 MLP 做简单融合,不需要 ASPP、OCR、FPN 等复杂结构。
- 整体优势:结构简洁、高效,既保留细节又有全局感受野。
🔑 总结
SegFormer 的网络结构流程是:
- Overlap Patch Embedding → 初步特征提取。
- Hierarchical Transformer Encoder → 4 层多尺度特征金字塔。
- All-MLP Decoder → 统一映射、上采样、融合,直接输出分割结果。
一句话概括:
👉 SegFormer 通过 MiT 编码器获取多尺度特征,用一个极简 MLP 解码器直接融合,最终实现了 简洁 + 高效 + 强性能 的分割网络。
4、SegFormer 的重大缺陷
- 对局部精细边界刻画不足
- SegFormer 的解码器极其简洁(All-MLP),缺少类似 CNN 中 卷积细粒度捕捉 的机制。
- 在复杂边界、小目标或纹理细节分割上,容易出现“边缘模糊”。
- 特别是在医学图像或遥感任务中,这种缺陷更明显。
- MLP 解码器表达能力有限
- 解码器虽然轻量,但过于简单:
- 只做特征对齐和融合,没有空间建模能力。
- 缺乏对不同尺度特征的动态权重分配(不像 FPN 或 Attention-based 解码器)。
- 结果是:对 类间相似(如道路 vs 建筑) 的细微差异区分能力不足。
- 高分辨率输入的计算压力
- 虽然 SegFormer 相比 ViT 已经优化了效率,但在处理超高分辨率图像(如遥感大图、医学 3D 体数据)时:
- 分层 Transformer 编码器 的内存和计算仍然很吃紧。
- 需要缩小 patch size 或裁剪图像,可能会损失全局信息。
- 缺乏任务特定优化
- 设计上追求“通用性”,但这也导致:
- 对 实例分割/全景分割 任务,需要额外修改,无法直接套用。
- 在 医学图像分割 中,没有像 nnU-Net 那样的数据自适应机制,需要额外调优。
- 训练数据依赖较强
- SegFormer 在 ADE20K、COCO-Stuff、Cityscapes 上表现很好,但在小样本或低标注数据集上:
- Transformer 的全局建模能力需要足够训练数据支撑。
- 如果数据不足,容易出现欠拟合或泛化性能下降。
- 缺乏显式的全局—局部交互机制
- 虽然 MiT 编码器具备全局注意力,但 SegFormer 没有设计专门的 局部细节增强模块。
- 在处理大场景(如自动驾驶道路)时可能会 全局一致性好,但细节不精确。
5、基于 SegFormer 的后续改进与创新模型
- 提升边界与细节建模
- EdgeSegFormer / Boundary-aware SegFormer (2022–2023)
- 在解码器中引入 边界注意力模块,强化小目标与物体边缘的预测。
- 改进了 SegFormer 在 精细边界(如道路边界、器官轮廓) 任务中的不足。
- SegFormer-B / SegFormer-Derivatives
- 加入卷积层或轻量的 attention head,在保持简洁的同时增强局部细节建模。
- 解码器增强
- HRSegFormer (2022)
- 借鉴 HRNet 的思想,在解码器阶段保持多尺度特征并行,减少细节丢失。
- MLA-Former (Multi-Level Attention SegFormer)
- 用注意力替代简单的 MLP 融合,对不同层次特征分配动态权重,提升对 小目标和复杂场景 的表现。
- 高效化与轻量化
- MobileSegFormer / TinySegFormer
- 面向嵌入式或移动端应用(如无人机、车载设备),在保持较高精度的同时显著减少参数量和 FLOPs。
- 特别适合 实时自动驾驶感知 场景。
- EfficientSegFormer
- 通过算子优化、模型蒸馏等方式加速推理,适用于大规模遥感与医疗场景。
- 跨模态与跨任务扩展
- MedSegFormer (2022–2023)
- 将 SegFormer 应用于医学图像分割(CT/MRI)。
- 在解码器中加入领域特定的正则化与数据增强策略,提升对小器官和肿瘤的分割精度。
- Panoptic SegFormer / Mask2Former (2022)
- 扩展 SegFormer 到 全景分割(Panoptic Segmentation)。
- Mask2Former 特别提出了 统一 Transformer 解码器,同时处理语义分割、实例分割和全景分割任务,提升了通用性。
- 结合多尺度与长程依赖的新思路
- HieraSegFormer (2023)
- 融合分层 Transformer 与分层解码器,更平衡全局依赖与局部细节。
- Mask2Former / SegNeXt (2022–2023)
- 从 SegFormer 演化而来,更强调全局—局部交互:
- Mask2Former 使用统一 mask attention。
- SegNeXt 借鉴 CNN 的高效卷积结构结合 Transformer 表示。
- 从 SegFormer 演化而来,更强调全局—局部交互:
🔑 总结
SegFormer 的后续改进主要分为五类:
- 边界增强 → EdgeSegFormer、Boundary-aware SegFormer。
- 解码器升级 → HRSegFormer、MLA-Former,用 attention 替代单纯 MLP。
- 高效化轻量化 → MobileSegFormer、EfficientSegFormer,适合实时部署。
- 跨模态/跨任务 → MedSegFormer、Panoptic SegFormer、Mask2Former。
- 全局与局部融合 → HieraSegFormer、SegNeXt,更好地平衡细节与全局。
👉 一句话总结:
SegFormer 的创新带来了“简洁高效”的分割新范式,但后续研究则在“补细节、增强解码器、提升效率和泛化”方向上持续改进,逐渐演化出更强大、更通用的分割框架(如 Mask2Former、SegNeXt)。