Swin-UNet(2021):使用 Swin Transformer 替代卷积块,扩大感受野
导出时间:2025/11/23 20:34:30
1、研究背景与动机
- 医学图像分割的背景
医学图像分割是计算机辅助诊断、手术规划等的重要环节。经典的 U-Net(2015)因其对称的 编码器-解码器结构 和 跳跃连接,成为医学分割的标准模型。
- 优点:U-Net 善于捕捉局部空间细节,分割边界精细。
- 缺点:卷积(CNN)的感受野有限,获取 全局上下文信息 能力不足。
这就导致在一些 形态复杂、尺度差异大 的器官分割中,U-Net 容易出现边界模糊、定位不准。
- Transformer 的引入
在自然语言处理(NLP)中,Transformer 通过 自注意力机制(Self-Attention) 能捕捉 长程依赖,后续的 Vision Transformer(ViT)证明了它在图像分类中的潜力。
- 优势:能建模全局关系。
- 不足:ViT 将图像分块(patch)处理,破坏了局部连续性,而且缺乏分层特征,对小目标和边界不友好。
在医学图像分割中,仅仅依靠 Transformer 或 CNN,都有短板。于是出现了 TransUNet 这种混合结构(CNN+ViT),但它依然对 全局与局部平衡 的处理不够优雅。
- Swin Transformer 的突破
2021 年提出的 Swin Transformer(Shifted Window Transformer)针对 ViT 的缺陷进行了改进:
- 将图像划分为 局部窗口,在窗口内做自注意力,大幅降低计算复杂度;
- 通过 移位窗口机制(Shifted Window),不同窗口之间也能交互信息;
- 构建了 层级化表示(Hierarchical Representation),天然适配下采样/上采样的结构。
这意味着 Swin Transformer 既能保持 局部细节,又能逐步融合 全局上下文,很适合像 U-Net 这样的分割架构。
- Swin-UNet 的提出动机
研究者提出 Swin-UNet,即第一个 纯 Transformer 架构 的 U-Net:
- 把 U-Net 的编码-解码对称结构 与 Swin Transformer 的层级特征表示 结合;
- 不再依赖 CNN 提取特征,而是用 Swin Transformer 全程完成特征建模;
- 保留 跳跃连接,保证局部与全局信息的结合;
- 旨在解决医学分割中 全局依赖难捕捉 与 局部边界难精细化 的矛盾。
👉 总结一句话:
Swin-UNet 的动机就是用 Swin Transformer 来替代 CNN,打造一个既能看细节、又能抓全局的纯 Transformer 分割网络,继承 U-Net 的对称架构,让它更好地适应医学图像分割任务。
2、核心创新点
- 纯 Transformer 架构的 U-Net
- TransUNet 仍然依赖 CNN 做特征提取,而 Swin-UNet 完全用 Swin Transformer 替代 CNN,构建了一个端到端的纯 Transformer 模型。
- 这意味着它能充分利用 层级化的 Transformer 表示,既捕捉全局依赖,又保持 U-Net 的跳跃连接结构,避免 CNN 局部建模的限制。
创新点:第一个 纯 Transformer U-Net,摆脱对 CNN backbone 的依赖。
- 层级化表示(Hierarchical Representation)
- Swin Transformer 的结构天然支持 逐层下采样,形成 不同分辨率的特征图。
- 这种层级化特征很适合 U-Net 风格的 编码-解码对称设计,能在解码时逐步恢复空间分辨率。
创新点:Transformer 直接提供多尺度特征,使其更契合分割任务。
- 移位窗口自注意力(Shifted Window Attention)
- 传统 ViT 的自注意力复杂度是 O(N2)O(N^2)O(N2),在高分辨率医学图像上代价过高。
- Swin Transformer 使用 窗口划分(Window Attention),复杂度降为 O(M2×NM2),其中 MMM 是窗口大小。
- 通过 移位窗口机制,让不同窗口之间也能信息交互,实现 全局上下文捕捉 + 高效性 的平衡。
创新点:在保证计算可扩展的同时,不丢失跨区域依赖。
- U-Net 式的跳跃连接(Skip Connections)
- 在编码器和解码器的对称层之间,依然保留 跳跃连接,让浅层的高分辨率细节与深层的全局语义特征结合。
- 相比纯 ViT,这样能显著提升小器官、细边界的分割效果。
创新点:在 Transformer 架构下保留 U-Net 精髓,实现细粒度定位。
- Patch Merging 与 Patch Expanding
- 在编码器部分,采用 Patch Merging(合并相邻 patch)进行下采样,减少分辨率、增加通道数。
- 在解码器部分,采用 Patch Expanding(patch 展开 + 上采样)恢复分辨率。
- 这样就形成了 U 型对称结构,并避免了 CNN 中的池化操作。
创新点:用 Transformer 原生操作完成上下采样,保持端到端一致性。
- 实验性能与泛化
- 在 Synapse 多器官 CT 分割等数据集上,Swin-UNet 优于 TransUNet 和其他 CNN/混合模型。
- 同时展现出 良好的泛化性,在跨数据集测试中依然保持较高性能。
创新点:验证了纯 Transformer 架构在医学分割中的可行性和优越性。
🔑 总结
Swin-UNet 的核心创新点可以概括为:
- 纯 Transformer 的 U-Net → 无需 CNN backbone。
- 层级化 Swin Transformer 表示 → 提供天然多尺度特征。
- 移位窗口注意力 → 兼顾计算效率和全局建模。
- 跳跃连接 → 保留 U-Net 的精细边界能力。
- Patch Merging/Expanding → Transformer 原生的上下采样机制。
- 验证有效性 → 在医学图像分割任务上刷新 SOTA。
3、模型的网络结构
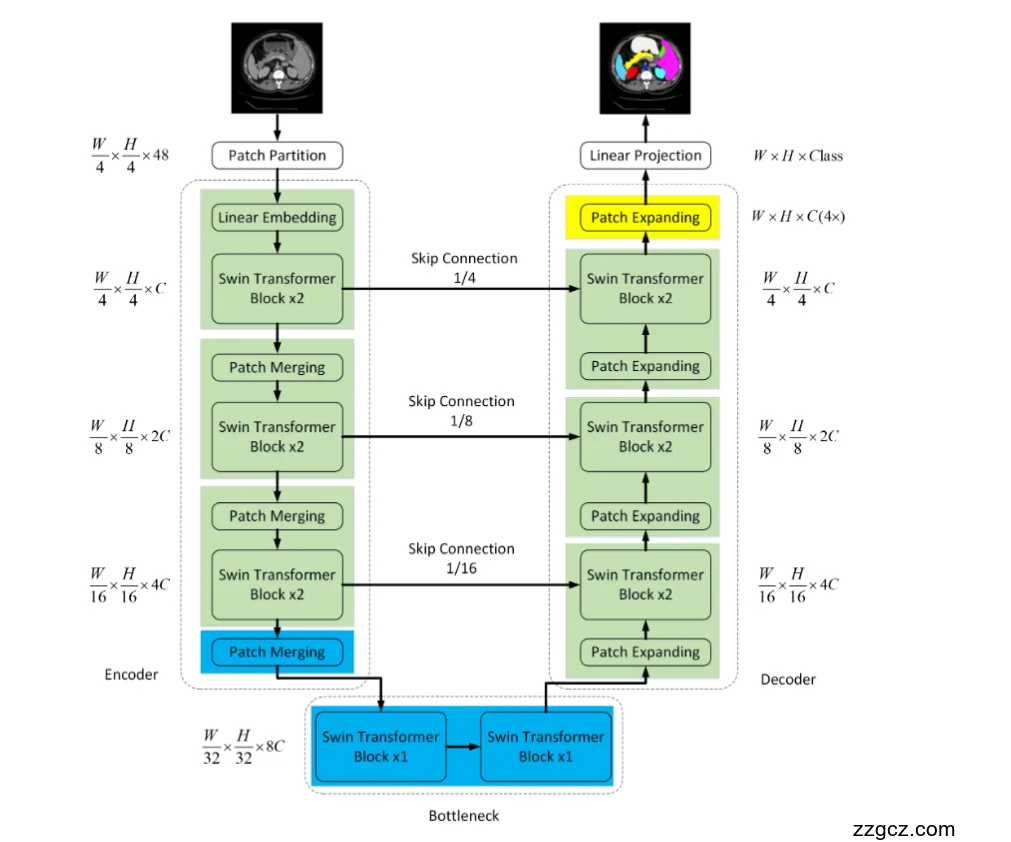
(1)整体框架
Swin-UNet 延续了 U-Net 的对称结构,分为三大部分:
- Encoder(编码器):逐层下采样,提取多尺度特征。
- Bottleneck(瓶颈层):最深层次的 Transformer 模块,捕捉全局信息。
- Decoder(解码器):逐层上采样,结合跳跃连接,恢复空间分辨率,输出分割结果。
(2)输入与 Patch Partition
- 输入图像大小:H×W。
- 首先通过 Patch Partition,把图像划分为小块(patch),得到初始的序列表示,尺寸变为 H/4×W/4×48。
- 接着经过 Linear Embedding 映射到 C 维通道。
👉 这一步相当于 CNN 的初步卷积操作,但这里是 Transformer 的 patch 化嵌入。
(3)编码器(Encoder)
编码器由 多层 Swin Transformer Block + Patch Merging 组成:
- Stage 1:
- 输入:H/4×W/4×C
- 经过 Swin Transformer Block ×2 → 局部注意力 + 移位窗口 → 融合上下文
- 输出给 Skip Connection (1/4)。
- Stage 2:
- Patch Merging 下采样 → 分辨率减半,通道数翻倍 → H/8×W/8×2C
- Swin Transformer Block ×2
- 输出给 Skip Connection (1/8)。
- Stage 3:
- 下采样 → H/16×W/16×4C
- Swin Transformer Block ×2
- 输出给 Skip Connection (1/16)。
- Stage 4:
- 下采样 → H/32×W/32×8C
- Swin Transformer Block ×1
- 进入瓶颈层。
👉 编码器逐层降低分辨率,逐层增强语义,全局依赖逐步捕捉。
(4)瓶颈层(Bottleneck)
- 在最低分辨率下,使用 Swin Transformer Block ×1,进一步建模全局关系。
- 输出特征为:H32×W32×8C\frac{H}{32} \times \frac{W}{32} \times 8C32H×32W×8C。
👉 相当于 U-Net 中“最深层”的卷积,但这里换成了 Transformer。
(5)解码器(Decoder)
解码器是编码器的对称部分,由 Patch Expanding + Swin Transformer Block 构成:
- Stage 4 → Stage 3:
- Patch Expanding 上采样一倍,得到 H/16×W/16×4C
- 与 Encoder 的 Skip Connection (1/16) 拼接。
- Swin Transformer Block ×2 融合特征。
- Stage 3 → Stage 2:
- 上采样 → H/8×W/8×2C
- 与 Skip Connection (1/8) 拼接。
- Swin Transformer Block ×2。
- Stage 2 → Stage 1:
- 上采样 → H/4×W/4×C。
- 与 Skip Connection (1/4) 拼接。
- Swin Transformer Block ×2。
- Final Output:
- Patch Expanding 恢复到原始分辨率 (H×W)。
- 经过 Linear Projection 映射到类别数,得到最终分割掩码:(H×W×Class)。
(6)输出(Segmentation Head)
- 最终输出是与输入大小相同的 语义分割图,每个像素被预测为某个类别(如不同器官)。
🔑 总结
- 编码器:Patch Partition → Linear Embedding → [Swin Transformer Block ×2 + Patch Merging] × 多层。
- 瓶颈层:最深的 Swin Transformer Block。
- 解码器:Patch Expanding + Swin Transformer Block ×2,结合跳跃连接恢复细节。
- 输出层:Linear Projection,得到像素级预测。
👉 简单来说:Swin-UNet 就是一个纯 Transformer 版本的 U-Net,利用 Swin Transformer 的层级表示、移位窗口注意力和 Patch Merging/Expanding 机制,实现全局依赖与局部细节的兼顾。
4、存在的缺陷
强依赖预训练,初始化方案可能非最优
论文明确指出基于 Transformer 的性能“极易受到预训练质量影响”,本文直接用 ImageNet 上的 Swin Transformer 权重初始化编解码器,并承认这种做法“可能并非最优”,后续需探索端到端预训练在医分中的路径
仅做 2D,未解决 3D 医学影像
作者直言:本文处理的输入是二维,而医学影像多为三维;后续将重点探索 Swin-UNet 在 3D 分割中的应用
分辨率↑ ⇒ 序列长度与计算负荷显著↑(效率受限)
在“输入尺寸消融”中,224→384 时虽然指标略有提升,但作者写明“整个网络的计算负荷显著增加”,因此实验都用 224×224 作为折中
模型规模加深带来“收益递减”甚至不增反降,但计算成本上升
“模型规模消融”给出的结论是:加大模型几乎无法提升性能,反而增加计算成本,最终采用 Tiny 级别作为主设定
网络过深存在收敛/稳定性问题
在瓶颈处作者只放了 2 个 Swin Block,理由是“Transformer 过深而无法收敛”,反映出深层 Transformer 在该任务上的优化难度
对既有方法的提升并不均衡:DSC 提升有限
在 Synapse 多器官 CT 上,论文自己强调相对 Att-UNet / TransUNet,DSC 的提升“有限”,优势主要体现在 HD(边界)显著下降(~4% 与 ~10% 的改善),显示其边界更准但整体重叠率改进不大
5、后续基于此改进创新的模型
面向 3D 医学影像的扩展
- Swin-UNETR(2022, MICCAI/3D Slicer 框架集成)
- 将 Swin Transformer 编码器 融入 3D U-Net 框架,天然处理 3D 体素输入。
- 在 BraTS 脑肿瘤分割、BTCV 多器官分割 等任务中表现优异。
- 解决了原版 Swin-UNet 只能处理 2D 切片的问题。
- Swin-Unet3D(2023)
- 把 Swin-UNet 全面拓展到 三维全 Transformer 结构。
- 使用 3D shifted window 注意力来建模体素间的全局关系。
- 更适合 心脏 MRI、肝脏 CT 等体数据。
轻量化与高效化
- LeViT-UNet(2021)
- 使用 LeViT Transformer 作为骨干,降低了计算复杂度。
- 更适合资源受限的临床环境。
- 相比 Swin-UNet,推理速度更快,参数量更小。
- Mobile-Swin-Unet / Tiny-Swin-Unet(社区变体)
- 针对移动端和嵌入式设备优化,减少显存占用。
- 目标是能在 实时医疗场景 中使用(如术中导航)。
优化深层 Transformer 的训练稳定性
- MISSFormer(2021/2023 TMI)
- 在 Swin-UNet 基础上加入 上下文桥接(context bridge),缓解深层 Transformer 的收敛难题。
- 同时加强了对 局部边界信息 的建模,弥补 Swin-UNet 在小器官边界精度不足的问题。
- UTNet(2021)
- 将 Transformer 融入 U-Net 的局部区域,采用 高效注意力机制,改善了训练稳定性和收敛速度。
提升边界和小器官分割效果
- Boundary-aware Swin-Unet(2022-2023 多篇变体)
- 在解码器中增加 边界感知模块,针对小器官(胰腺、胆囊等)和模糊边界做专门优化。
- 解决原版 Swin-UNet 在 DSC 提升有限、边界细节不够精确的问题。
多模态与跨域泛化
- Swin-MMFormer / Cross-modal Swin-Unet(2022-2023)
- 面向 CT + MRI 多模态输入的改进,增强跨域学习能力。
- 目标是缓解 数据依赖过强 的问题,在小样本或跨医院数据上仍能保持稳定性能。
🔑 总结
后续改进大致沿着以下方向展开:
- 三维扩展:Swin-UNETR、Swin-Unet3D → 解决 2D 局限,直接处理 3D 医学影像。
- 轻量化:LeViT-UNet、Tiny/Mobile-Swin-Unet → 降低计算和显存开销,更适合临床部署。
- 训练稳定性优化:MISSFormer、UTNet → 改善深层 Transformer 的收敛问题。
- 边界精度提升:Boundary-aware 变体 → 针对小器官和复杂边界的细化优化。
- 跨模态泛化:Swin-MMFormer → 提升在多模态医学数据上的鲁棒性。