V-Net(2016):三维医学影像分割的全卷积神经网络
导出时间:2025/11/23 20:31:17
1、摘要讲解:V-Net 模型是什么?它解决了什么问题?3D 打印机
- 背景:卷积神经网络(CNN)很厉害,但有局限
想象一下,卷积神经网络(CNN)就像一个超级聪明的“图像分析师”,它能从图片里自动找出重要的特征,比如边缘、纹理,甚至复杂的形状。近年来,CNN 在计算机视觉(比如人脸识别)和医学图像分析(比如看 CT 扫描)中表现得特别出色,堪称“业界顶尖”。
但问题来了:传统的 CNN 大多是处理二维图片的,比如照片、X 光片。而医院里常用的医学数据,比如 MRI 扫描,其实是三维的,就像一个立体的“数据立方体”。直接用二维 CNN 处理三维数据,就好比用平面地图去分析一个立体的地球,效果肯定不够好。
- V-Net 的目标:直接处理三维医学数据
V-Net 模型就像一个“升级版的 CNN”,专门为三维医学数据设计。它能一次性看懂整个三维 MRI 数据(比如前列腺的 MRI 图像),而不是把三维数据切成一片片二维图像来处理。这就像直接看一个完整的西瓜,而不是只看西瓜的切片,信息更全面,处理也更高效。
V-Net 的核心任务是“分割”,也就是在三维 MRI 图像中精准地把目标区域(比如前列腺)勾勒出来。这对医生来说非常重要,因为它能帮助他们判断器官的大小、边界,辅助诊断和治疗计划。
- 创新点 1:用 Dice 系数优化,解决数据不平衡
在医学图像中,目标区域(比如前列腺)通常只占图像的一小部分,背景区域占了绝大部分。这就像在一堆沙子里找几颗珍珠,珍珠(前景)少得可怜,沙子(背景)多得吓人。如果直接用普通的训练方法,模型可能会“偏心”,更关注背景,忽略前景。
V-Net 聪明地引入了一个叫 Dice 系数 的优化目标。Dice 系数就像一个“公平裁判”,它专门衡量模型预测的分割区域和真实区域的重叠程度,特别适合处理前景和背景数量严重不平衡的情况。有了它,V-Net 就能更精准地找到那些“珍珠”。
- 创新点 2:数据增强,解决数据少的问题
医学数据的另一个挑战是:标注好的数据(也就是医生手动标出前列腺区域的图像)非常少,因为标注很费时间和精力。V-Net 通过“数据增强”来解决这个问题。简单来说,它就像一个“图像魔法师”,对原始数据做一些随机变换,比如旋转、缩放、调整亮度等,生成更多“类似但不同”的训练数据。这就像把一张照片翻来覆去拍出不同角度的照片,让模型有更多材料来学习。
- 实验结果:又快又准
V-Net 在前列腺 MRI 数据集(PROMISE 2012 挑战数据集)上测试,表现非常优秀。它不仅能精准分割前列腺,即使面对复杂的图像(比如图像中有伪影或变形),也能应对自如。而且,它处理速度超快,相比传统方法,时间缩短到“零头”,就像从跑马拉松变成了百米冲刺。
2、Vnet的网络结构
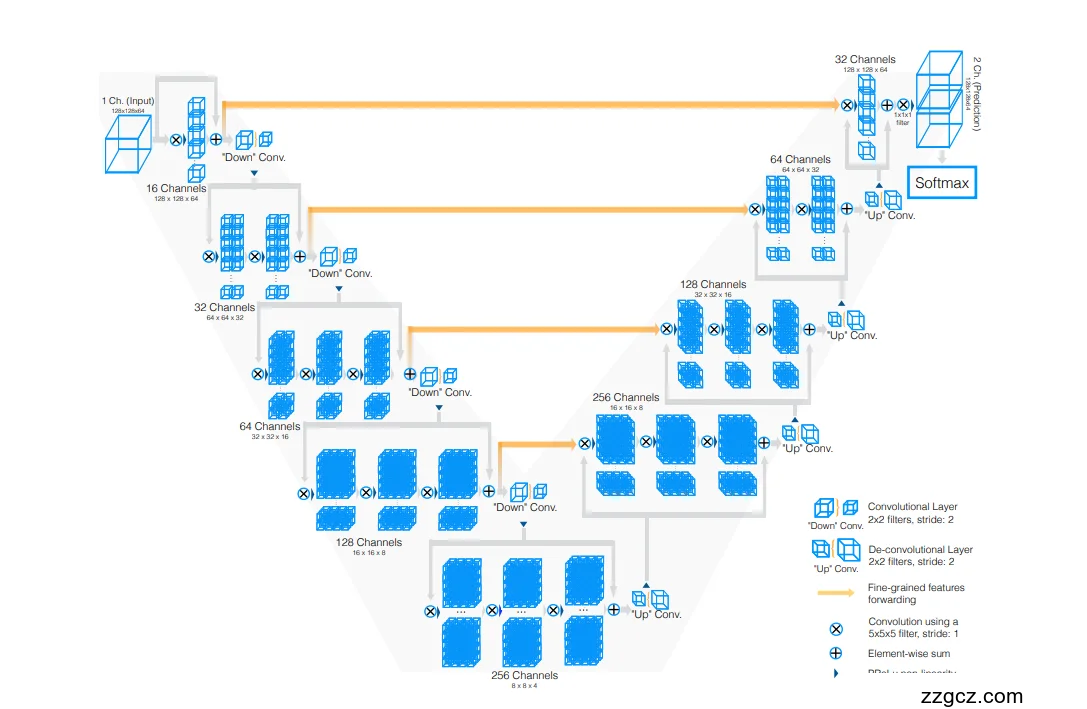
整体架构:像一个“V”字形的流水线
V-Net 的名字来源于它的形状,像一个“V”字(见文档中的图 2)。你可以想象它是一个流水线:
- 左侧(压缩路径):把输入的巨大三维图像(比如 128×128×128 的 MRI 数据)逐步“压缩”,提取关键特征,变得更小但信息更浓缩。
- 右侧(解压缩路径):把压缩后的特征再“放大”,一步步恢复到原始图像大小,同时生成分割结果(前景和背景的概率图)。
左侧压缩路径:提取特征的“压缩机”
左侧的压缩路径就像一台“特征提取机”,通过一系列卷积操作,把输入的三维图像逐步“浓缩”。它分成多个阶段(文档提到 5 个阶段),每个阶段就像一个“加工车间”:
- 卷积操作:每个阶段使用 5×5×5 的卷积核(就像一个 5×5×5 的小方块扫描仪),扫描图像,提取特征,比如边缘、纹理等。这些卷积核就像工人,专门挑出图像中有用的信息。
- 通道翻倍:每个阶段的特征通道数量会翻倍(从 32 个通道开始,逐步增加到 64、128、256)。通道多意味着提取的信息种类更多,就像从黑白照片升级到彩色照片,能捕捉更多细节。
- 分辨率减半:通过使用步长为 2 的 2×2×2 卷积核(文档中的图 3),每个阶段把图像的分辨率减半(比如从 128×128×128 变成 64×64×64)。这就像把一张高清图片缩小,减少计算量,但保留核心信息。
为什么不用池化层?
传统 CNN 常用池化层(比如最大池化)来缩小图像,但 V-Net 用卷积操作代替池化。池化就像粗暴地扔掉一些信息(只保留最大值),而卷积更“温柔”,通过学习保留更多有用信息。文档提到,这种替换还减少了内存占用,训练更高效。
残差学习:让训练更快更稳定
V-Net 在每个阶段加入了 残差学习(residual learning),这就像给工人配了个“智能助手”,让工作更高效。残差学习的原理是:
- 每个阶段的输入会经过卷积层处理(非线性变换,文档中的条件 a)。
- 处理后的结果会和原始输入“相加”(文档中的条件 b),形成一个“残差函数”。
这就像在画图时,不是直接画最终结果,而是先画个草稿,然后只修改“差的地方”。残差学习让模型更容易学到关键信息,文档里说它能让训练收敛速度提升好几倍,就像从骑自行车升级到开汽车。
右侧解压缩路径:把特征还原成分割结果
右侧的解压缩路径就像一个“还原工厂”,把左侧压缩后的小特征图逐步放大,恢复到原始图像大小(128×128×128),并生成分割结果。它的操作包括:
- 反卷积操作:用 2×2×2 的反卷积(步长为 2,文档中的图 3)把特征图放大。比如,把 16×16×16 的特征图放大到 32×32×32。反卷积就像把一个缩小的模型重新拉大。
- 通道减半:和左侧相反,右侧每个阶段的特征通道数量减半(从 256 回到 128、64、32),因为需要把信息“精炼”成最终的分割结果。
- 残差学习:右侧也用残差学习,确保信息在放大过程中不失真。
最终,网络输出一个 双通道的分割图(1×1×1 卷积核),通过 软最大化(softmax) 算法,把每个体素(3D 像素)分成前景(比如前列腺)和背景的概率。
横向连接:保留细节的“传送带”
V-Net 的一个聪明设计是 横向连接(skip connections),就像在左侧和右侧之间架了一座“信息传送桥”。具体来说:
- 左侧早期阶段提取的细粒度特征(比如边缘、纹理)会直接传到右侧对应阶段(文档中的图 2)。
- 这些特征就像“高清细节”,在压缩过程中可能会丢失,但通过横向连接可以重新利用,帮右侧生成更精准的分割结果。
这就像在还原图纸时,不仅看压缩后的草稿,还能参考原始的高清图纸,确保细节不丢。文档提到,这种连接还能加快模型的收敛速度。
3、Dice系数
在医学图像分割中,比如用 V-Net 分割前列腺 MRI,模型需要预测一个区域(比如前列腺),然后和医生手动标注的“真实区域”对比。问题是,前列腺区域(前景)通常很小,而背景(非前列腺区域)占了绝大部分,就像在一大片沙漠里找几块绿洲。如果直接用普通的准确率(比如正确预测的像素数除以总像素数),模型可能会“偷懒”,只预测背景,因为那样准确率会很高。
Dice 系数就像一个“公平的裁判”,它专门衡量预测区域和真实区域的重叠程度,特别适合处理这种“前景少、背景多”的不平衡情况。V-Net 用它作为优化目标函数,让模型更关注重叠部分,而不是被背景“蒙混过关”。

V-Net 用 Dice 系数作为损失函数(loss function),反过来优化模型。损失函数的目标是让 Dice 越大越好(因为 Dice 大意味着重叠多),所以实际优化的损失是:
Loss=1−Dice
- 训练过程:模型通过调整参数,尽量让 Loss 变小(Dice 变大),直到预测区域和真实区域重叠最多。
- 不平衡解决:因为 Dice 关注重叠比例,而不是整体像素数,它不会被背景的“庞大数量”干扰,完美适合医学图像的“少前景、多背景”场景。
比如,在前列腺 MRI 中,前景(前列腺)可能只占 1% 的体素,Dice 系数能确保模型不忽略这 1%,而是全力匹配它。