DDRM(2022):基于扩散模型的去噪方法
1、研究背景与动机
1️⃣ 图像修复的老问题:从“模糊照片”到“数学方程”
线性逆问题(Linear Inverse Problem)
- x:你想要的“干净原图”
- y:被模糊、降噪、压缩后的“观测图像”
- H:表示退化的操作(比如模糊、降采样、遮挡)
- z:噪声(让图像更糟的部分)
2️⃣ 两大传统思路的困境
(1)监督学习:一对一学习修复
- 需要成对训练数据(现实中几乎没有);
- 只能解决特定类型的退化问题(换个模糊核就得重新训练)。
(2)无监督/先验驱动:靠图像的“自然规律”
- 监督方法像是“定制化医生”:专治一种病,很快,但只会这一种。
- 无监督方法像是“老中医”:不挑病种,但诊断过程又慢又玄学。
3️⃣ 扩散模型的崛起:从生成到修复
“我先把一张图加噪声直到几乎全白,再一步步学会把噪声还原成图像。”
4️⃣ DDRM 的诞生:把扩散模型变成“万能修图师”
🔹 DDRM(Denoising Diffusion Restoration Model) ——一个可以用预训练的扩散模型直接解决各种图像复原问题的方法。
- 不需要针对每种任务重新训练;
- 不需要 paired 数据;
- 只用预训练好的扩散生成模型(比如DDPM);
- 通过数学上定义好的“后验采样”,在20步内就能完成去噪、去模糊、超分辨率、修复等任务。
5️⃣ 形象比喻
“请在还原过程中参考这个模糊图——别完全乱画。”
- 他既能保持生成图像的真实感(得益于扩散模型的生成能力),
- 又能复原被破坏的区域(得益于测量模型的约束)。
DDRM 诞生的动机是为了解决「无监督图像复原」的老问题: 它想要兼顾三点—— 不需要配对数据、适配任意退化模型、生成质量高还快。
2、核心创新点
1. “不重新训练,也能通吃多任务”
2. 在“频谱/SVD 空间”里做事,带来通用、可控的后验采样
3. 有理论“背书”:与 DDPM/DDIM 目标等价,可直接复用
4. 采样“快准稳”:少步数也能出好图
5. 跨任务、跨噪声强度的效果与速度优势
6. 一个统一的“通用公式”,换 HHH 就换任务
一句话总括
DDRM = 预训练扩散先验 + 退化算子SVD投影 + 快速少步采样。 它用一个统一、无需重训的后验采样公式,把多种图像复原任务一次性拿下,快且稳,还给出了理论保证与工程可复用性。
3、网络 / 算法流程结构(结合图讲解)
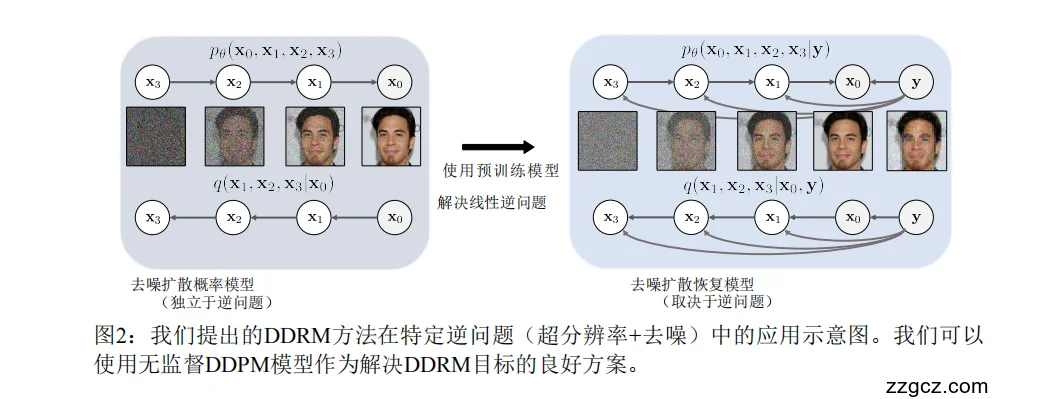
一、整体思路:让“扩散模型”变成“带参照的画家”
“从噪声里一步步学会画出一张清晰的图像”。
“在画的过程中参考一张模糊或损坏的图像 y,让画出来的图既真实又符合观测约束”。
二、左图:普通扩散模型(DDPM)
它的流程是:
- 前向扩散(q过程)
- 把真实图像 x0x_0x0 一步步加噪,得到 x1,x2,…,xT。
- 最后 xT 变成纯噪声。
- 这叫 “正向扩散”,记为:
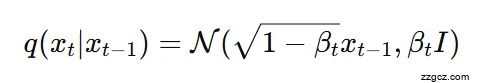
- 反向去噪(p过程)
- 模型学习如何一步步从噪声还原出清晰图:
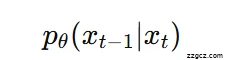
- 这就是我们训练好的 DDPM 模型。
三、右图:DDRM 的去噪扩散恢复模型(带观测约束)
🧱 Step 1:输入观测图像 y
- y 是退化后的图像(比如模糊、噪声、低分辨率)。
- 退化关系:
- y=Hx0+n
- 其中 HHH 是退化矩阵(比如模糊核、下采样矩阵)。
🔄 Step 2:SVD 分解退化矩阵 H
- DDRM 的关键数学工具是 奇异值分解 (SVD):
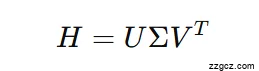
- 它能把图像空间分成两部分:
- 被观测到的部分(在 U 的子空间中);
- 未观测到的部分(在其正交补空间中)。
DDRM 在恢复时,只对“未观测部分”依赖生成模型; 对“观测到的部分”直接用 y 提供的线索。
- 图像符合观测(不偏离 y);
- 同时保留扩散模型的生成能力。
🎨 Step 3:从噪声开始反向生成(采样阶段)
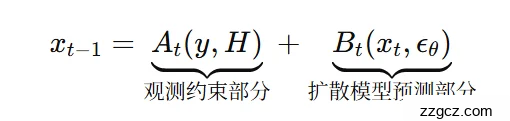
- 第一项 At(y,H):根据观测 y + 矩阵 H 调整,确保生成图符合退化约束。
- 第二项 Bt(xt,ϵθ):由预训练扩散模型预测噪声,再反向去除。
- 看参考图 y(A_t);
- 再凭自己的画功修出合理细节(B_t)。
🧮 Step 4:每一步的条件更新(Conditioned Denoising)
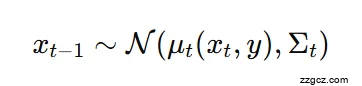
- 退化矩阵 H
- 噪声方差 σt
- 当前的观测 y
- 模型预测的干净图像分量
⚡ Step 5:快速采样与输出
- DDRM 不需要从 T=1000 步慢慢采样。
- 只需几十步(20~50)就能生成高质量结果;
- 而且每一步计算都是闭式公式(不需要梯度下降)。
四、图像生成 vs. 图像修复的区别(结合图理解)
对比项
| 普通扩散模型(左)
| DDRM(右)
|
输入
| 随机噪声
| 观测图像 y(含退化)
|
任务目标
| 从噪声生成真实图像
| 在观测约束下恢复原图
|
数学过程
| 独立的反向扩散
| 条件化的后验扩散
|
是否使用 H
| ❌ 不用
| ✅ 明确建模
|
是否需重训
| ✅ 通常需要
| ❌ 可直接用预训练模型
|
输出效果
| 真实但不对应输入
| 既真实又与输入匹配
|
五、算法流程小结(文字版)
输入: 退化图像 y, 已知退化矩阵 H, 预训练扩散模型 εθ
1️⃣ 计算 H 的 SVD 分解 (U, Σ, V)
2️⃣ 从噪声 x_T ~ N(0, I) 开始采样
3️⃣ 对每个时间步 t = T ... 1:
a. 用扩散模型预测噪声 εθ(x_t, t)
b. 根据 H 和 y 计算条件均值 μ_t(x_t, y)
c. 采样 x_{t-1} ~ N(μ_t, Σ_t)
4️⃣ 输出最终去噪图像 x_0(修复结果)
六、形象总结:一位“带着模糊照片的画家”
你可以想象:
- 普通扩散模型像个“凭感觉画图的画家”,他能画真图,但不知你要哪一张;
- DDRM 给他一张“模糊的参考照 y”,再说:“请在这张基础上画出清晰版本”;
- 他每一笔都“对照参考 + 结合经验”, 最后画出一张既符合输入结构又自然真实的修复图。
DDRM 的算法流程 = 扩散模型的反向生成 + 测量模型约束投影。 它像一个“带参照的画家”,在每一步反向去噪时都“看一眼模糊图”, 让生成既符合观测,又保持自然逼真。
4、模型的不足与缺陷
一、依赖“线性退化假设”,适用范围有限
- JPEG 压缩 → 含有非线性量化;
- 运动模糊 → 涉及复杂的相机轨迹;
- 光照/曝光过度 → 非线性饱和;
- 雾霾/水下成像 → 指数衰减模型。
DDRM 就像一位“只会修直线透视”的画师, 让他修曲线扭曲的照片,他就懵了。
二、严重依赖“已知退化矩阵 H”
- 很多场景下我们根本不知道退化核(比如相机模糊核未知);
- 有的退化操作 HHH 甚至无法明确写成矩阵形式(比如JPEG压缩、传感器失真);
- SVD 分解在大分辨率图像下计算代价高。
- 高斯去噪;
- 均匀模糊去模糊;
- 降采样超分辨率。
DDRM 就像一位修图大师,但前提是你必须告诉他“照片是怎么坏的”。不告诉他模糊的原因,他就修不动。
三、仍然“生成式推理”,速度慢于传统复原网络
- 在 GPU 上跑一张 256×256 图像仍需几秒;
- 做视频或大图像修复时代价高。
CNN 修图像“一笔到位”;DDRM 修图像要“画二十几遍”,每次都微调一点。最后画得漂亮,但耗时。
四、模型结构不可学习,难以针对性优化
- 它无法根据具体任务(比如去模糊 vs 上色)微调;
- 也无法学习更复杂的退化结构;
- 所有任务都被“硬塞”进同一个公式。
DDRM 就像一个通才型画家:画人脸很强,但让他修山水画就有点“风格不搭”。
五、对预训练扩散模型的质量高度依赖
- 训练数据有限;
- 噪声调度参数不合理;
- 没有覆盖输入退化分布;
- 模糊;
- 偏色;
- 甚至生成“错误的纹理”。
DDRM 像一个“借画功的助手”,师傅(扩散模型)画得好,它就强;师傅画得一般,它再聪明也画不出奇迹。
六、对噪声水平估计敏感
- 过度平滑(噪声估计太高);
- 残留噪点(估计太低)。
它像医生开药,药量多一点会伤身,少一点又不见效。每一步剂量都得刚刚好,容不得差。
七、理论上完美,实际中不鲁棒
- 修复结果过平滑;
- 人脸或纹理细节“假脸感”;
- 色彩偏差;
- 不同随机种子输出差异大。
DDRM 就像一个天才画家,每次都能画出一幅好图,但——不是每次都一样。
5、改进方向与启示(如何优化 DDRM 思想)
一、回顾 DDRM 的核心思路
DDRM = 预训练扩散模型 + 退化矩阵约束(SVD 投影) + 条件采样(posterior sampling)
- 仅适用于线性退化;
- 需要已知退化矩阵 H;
- 对复杂退化不适应;
- 推理仍然较慢。
二、改进方向一:从线性退化 → 通用退化(DPS、DR2、InDI)
🔹 1. Diffusion Posterior Sampling(DPS, 2022)
- 把 DDRM 的“线性假设”扩展为任意可微退化函数 f(x)f(x)f(x);
- 在采样过程中加入梯度引导(gradient guidance);
- 不再需要 HHH 的显式逆或 SVD 分解。
- 可用于任意退化(非线性也行);
- 理论框架通用;
- 无需知道具体矩阵 H。
- 仍需计算梯度(慢);
- 对损失函数与引导权重敏感。
🔹 2. DR2(Diffusion Restoration via Regularization, 2023)
- 将 DDRM 的“投影操作”换成正则约束优化问题;
- 在每步采样后通过正则项强制满足观测一致性。
DR2 把“直接投影”变成“逐步修正”,让模型在每步采样时都兼顾真实与观测。
- 更稳定;
- 可兼容多种退化形式;
- 支持盲去模糊等复杂场景。
🔹 3. InDI(Inverse Diffusion Inference, 2024)
- 把 DDRM 思想扩展到“推理时学习(Inference-Time Adaptation)”;
- 通过优化一个轻量化网络(或可调参数)适配特定退化分布;
- 实现“在线自适应”修复。
DDRM 是固定老师照书修;InDI 则是“边修边学”,能根据当前照片自动调整修复策略。
三、改进方向二:提升速度与效率(DDNM、DDNM+、ADIR)
🔹 1. DDNM(Denoising Diffusion Null-space Model, 2023)
- 发现 DDRM 的 SVD 分解其实就是在建模“退化的零空间(Null Space)”;
- 提出了更高效的“零空间投影”方法;
- 能用极少采样步数(甚至 <10 步)实现高质量修复。
DDRM 的核心其实是“在扩散过程中做约束投影”。DDNM 用更高效的线性代数形式,让这一过程更快更准。
🔹 2. DDNM+(改进版)
- 支持未知噪声水平估计;
- 加入动态加权策略;
- 更稳定,更通用;
- 被认为是 DDRM 的“工程强化版”。
🔹 3. ADIR(Adaptive Diffusion Image Restoration, 2024)
- 在推理过程中根据退化类型自适应调整扩散噪声调度表 β_t;
- 提高了不同任务(去噪/去模糊/超分)之间的兼容性。
DDRM 是“一张配方吃到底”; ADIR 能根据菜的味道(退化类型)自动调配“火候”(噪声计划)。
四、改进方向三:提升真实感与细节(RePaint、Palette)
🔹 RePaint(CVPR 2022)
- 在每步采样后随机“重采样”部分像素;
- 让模型多次修正被遮挡或失真的区域;
- 主要用于图像修补(Inpainting)。
DDRM 只能修线性退化,RePaint 开始尝试生成式的非线性修补。 把扩散模型真正变成“通用修图师”。
🔹 Palette(Google Research, 2023)
- 把修复任务统一成“条件扩散模型”;
- 在训练阶段显式加入任务条件(噪声、分辨率、缺失率等);
- 让模型在推理时自适应多种任务。
DDRM 是“事后使用预训练模型”;Palette 则是“直接训练一个多任务修复模型”。
五、改进方向四:让 DDRM 具备学习能力(Plug-and-Play + Fine-tuning)
- 在采样过程中加入轻量可学习模块(如UNet适配层、低秩LoRA层);
- 只需少量步骤调优即可适配新退化;
- 保留原扩散模型参数不变。
把“固定算法”变成“可适配算法”,既继承DDRMs数学优雅,又具备学习能力。
六、未来启示:DDRMs 思想的长期价值
启示方向
| 核心思想
| 未来趋势
|
统一性
| 将所有图像复原任务看作“扩散采样 + 约束优化”
| 更通用的统一复原框架
|
可适应性
| 在采样中动态调整噪声或约束
| 自适应任务条件控制
|
无监督性
| 不依赖成对训练样本
| 更适合真实世界部署
|
生成质量
| 保持生成模型的逼真纹理能力
| 向高感知质量方向优化
|
计算效率
| 降低采样步数、提升推理速度
| 结合快速ODE采样/蒸馏
|
多模态融合
| 融合深度、语义、语音等条件
| 从单图修复到多模态生成
|
七、形象总结:从 DDRM 到“通用修图大脑”的演化
阶段
| 代表模型
| 关键特征
|
DDRM (2022)
| 线性逆问题 + SVD
| “带公式的修图师”
|
DPS (2022)
| 梯度引导
| “懂得随任务微调的修图师”
|
DDNM (2023)
| 零空间投影
| “数学效率专家”
|
DR2 (2023)
| 正则修正
| “稳定派修复大师”
|
InDI (2024)
| 在线适配
| “自学型修图AI”
|
Palette (2023)
| 多任务条件训练
| “通用修复工厂”
|
DDRM 是“扩散 + 约束”范式的开端,它让生成模型第一次变成了真正意义上的“万能图像修复器”。 后续研究(DPS、DDNM、RePaint、InDI 等)在此基础上,让它变得更通用、更快、更稳、更聪明,正在把“扩散模型”推向 一体化视觉修复大脑 的时代。