SwinIR(2021)! 使用 Swin Transformer 进行图像恢复
1、研究背景与动机
1. 图像修复的目标:让“模糊变清晰”
- 图像超分辨率(Super-Resolution):把模糊的低清图变成高清图。 👉 类比:像把模糊的老照片“修复”成高清版本。
- 图像去噪(Denoising):去掉照片中的噪点。 👉 就像修掉“下雨天玻璃上的小水珠”。
- JPEG压缩伪影消除:消除压缩带来的块状瑕疵。 👉 就像清理掉“像素方块”的马赛克。
输入是“受损”的图片,输出要尽量还原“原始”的样子。
2. CNN的时代:局部高手,但“眼界太窄”
- 它能专注看清局部细节;
- 但每次只能看到一小块图像。
- 它看得太近 —— CNN 只处理局部区域,难以理解整个图像的“全局结构”;
- 它不够聪明 —— 不同区域特征差异很大,但 CNN 用相同的卷积核处理所有地方,就像“用同一把刷子画完所有细节”,结果自然不完美。
CNN 就像一个“低头苦画的小画匠”,他笔法细腻,但眼光短,画得久了容易“失真”,特别是在大尺寸图像上。
3. Transformer的崛起:从文本到图像的“全局思考者”
“既然 Transformer 在语言和图像识别中这么强,那能不能用在图像修复上?”
- ViT(Vision Transformer):用固定大小的图像块做注意力;
- IPT(Image Processing Transformer):第一个大规模图像修复Transformer模型。
- 需要巨量参数(上亿)和上百万张图像训练;
- 分块处理导致边界伪影(块与块之间不自然);
- 对高分辨率图像计算量太大。
Transformer 像一个聪明的设计师,但太“奢侈”——想画一张图,他要开几十台电脑同时算,画出来还可能“接缝不平”。
4. Swin Transformer:为视觉量身定做的“窗口化眼睛”
- 把整张图像分成“小窗口”;
- 在每个窗口内做局部注意力(高效);
- 再让窗口交错移动(shift),实现跨区域信息交流。
就像一个拼图大师,先在每个窗口内打磨细节,再移动视角去观察整个画面。既节省算力,又能看到全局。
5. SwinIR 诞生:Swin Transformer + 图像修复任务
“让图像修复模型既有 Transformer 的全局智慧,又有 CNN 的效率。”
- 设计了浅层卷积提取 + 深层 Transformer 表征;
- 用移位窗口机制解决边界伪影;
- 通过残差结构让训练稳定;
- 同时适用于多种任务(超分、去噪、压缩伪影)。
✨ 一句话总结:
SwinIR 的出现,是图像修复从“局部卷积时代”走向“全局注意力时代”的转折点。它让模型既聪明(能理解全局),又高效(能快速处理大图),成为 Transformer 在图像修复领域的“标志性起点”。
核心创新点
🧩 总览一句话:
SwinIR 的创新点不是“重造轮子”,而是“巧妙融合”。 它把 Transformer 的“远见”和 CNN 的“细腻”融合在一起,既聪明、又高效。
创新点一:从全局注意力 ➜ 窗口化注意力(Window-based Attention)
- 原始的 Transformer(比如 ViT)会让每个像素和所有其他像素都计算注意力。
- 这样复杂度是 O(N²) —— 图像一大,计算量爆炸。
- 对高分辨率图片几乎无法训练。
想象你在一个体育场里(每个像素一个人),每个人都要和场里所有人打招呼(计算注意力)——场子越大,累死谁都算不完。
- 把整张图像切分成若干 小窗口(7×7 或 8×8 块);
- 只在每个窗口内部计算注意力;
- 大幅降低计算复杂度,从 O(N²) 降为 O((M×M)×(N/M²));
- 效果几乎不变,但速度和内存占用小很多。
SwinIR 不让“全场人”互相打招呼,而是让每个窗口的“小圈子”先交流。每个小组自己开会,先搞定局部问题。
创新点二:移位窗口机制(Shifted Window)
不同窗口之间信息不交流, 像每个小组“各自为政”。
- 第一层在普通窗口内计算注意力;
- 下一层将窗口位置平移一半;
- 这样前后两层窗口会部分重叠;
- 从而实现跨窗口的信息融合。
想象你在公司开会: 第一次分部门开会(窗口内), 第二次调换座位混合开(窗口平移), 大家互相交流,消息自然传遍全公司。
既保留局部计算的高效性,又获得了全局关联性! 网络变得既“眼光宽”,又“手脚快”。
创新点三:层次化(Hierarchical)特征建模
- 低层关注细节(小尺度);
- 高层捕捉全局结构(大尺度);
- 每一层下采样,像金字塔一样逐步提取特征。
网络就像一个“放大镜金字塔”:
- 底层盯着像素细节;
- 中层看出物体形状;
- 顶层理解整个场景结构。
创新点四:残差式图像恢复架构(Residual Swin Transformer Blocks)
输入图像
↓
浅层特征提取(卷积)
↓
多个残差 Swin Transformer 模块(RSTB)
↓
特征融合 + 卷积重建
↓
输出图像
它像一条“高速公路”,每个中转站(Transformer块)都保留了主路(残差)通道,确保信息不堵车、不失真。
创新点五:任务通用性(可一键适配不同图像修复任务)
任务
| 说明
| 示例
|
超分辨率
| 提高清晰度
| 低清图 → 高清图
|
去噪
| 去掉噪点
| 摄影噪声、ISO 噪点
|
压缩伪影消除
| 修复JPEG压缩方块
| 网图还原高清
|
SwinIR 像一台“通用修图机”,插上不同“工具头”就能变身为:清晰修复器 / 去噪器 / 解码还原器。
创新点六:轻量但高性能(小体积,大智慧)
- SwinIR 的参数量比同级 CNN(如 RCAN、EDSR)还小;
- 但性能(PSNR、SSIM)反而更高;
- 说明它“算得更聪明,不靠堆参数”。
它不是“肌肉型猛男”,而是“脑子灵光的高手”——凭借窗口注意力与层次结构的组合,事半功倍。
创新点七:视觉Transformer的“稳定化”改进
- 对高频细节敏感;
- 梯度爆炸或收敛慢。
- LayerNorm + Residual + GELU 激活;
- 小窗口 attention(抑制噪声干扰);
- 层级残差结构防止特征退化。
就像给Transformer装上了“减震器”和“护栏”.保证它既能跑得快,又不会翻车。
模型的网络结构
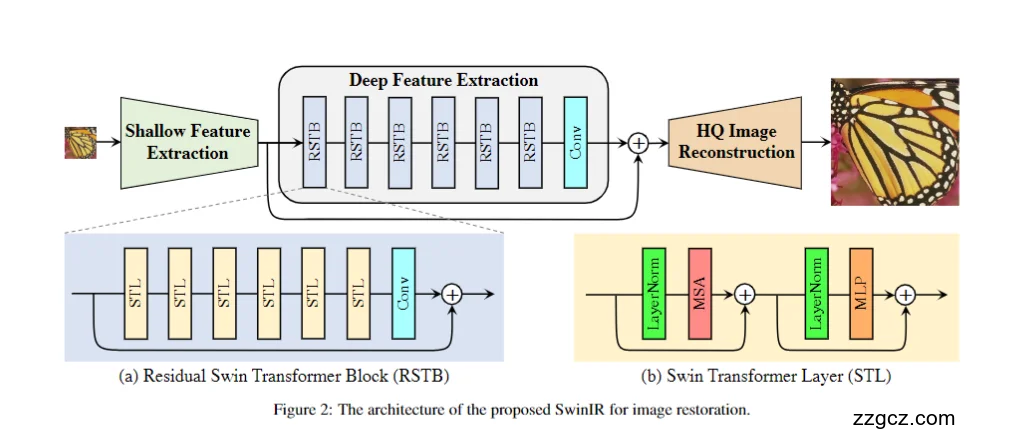
A. Shallow Feature Extraction(浅层特征提取)
- 做什么? 用一层卷积把输入图像“翻译”成基础特征图(边缘、纹理的底稿)。
- 为什么? 给后面的 Transformer 模块提供一个干净、统一的“起始语言”。 (图里左侧绿色小块就是它)
B. Deep Feature Extraction(深层特征提取)
- 核心:一串 RSTB(Residual Swin Transformer Blocks,残差式Swin块)
- 每个 RSTB 长什么样?
- 里面堆叠了若干 STL(Swin Transformer Layer),
- 末尾接一层 Conv,
- 外面再整块做残差连接(“进来是什么,出去要加回去一部分”)。 这三件套正是论文里的标准定义:“STL × n → Conv → (块级残差)”。
- 一个 STL 又包含什么?
- LayerNorm → 窗口多头自注意力(MSA) → 残差加法,
- 再 LayerNorm → MLP(前馈网络) → 残差加法。 (正如你图右下角(b)的小框所示)——这是 SwinIR 里一层的最小单元。
- 直觉版解释:
- 窗口注意力= 每个“小窗格”里先把细节讲清楚;
- 多层堆叠= 逐步从纹理到结构“层层提纯”;
- 块级残差= 给信息开“回路”,让训练稳、细节不丢。
小结:RSTB 是“精修工坊”,STL 负责看细节、Conv 负责融合、块级残差防退化,按图里的蓝色长条一路串起来就是深层主干。
C. HQ Image Reconstruction(高质量重建头)
- 做什么? 把深层特征变回图像。
- 怎么做?
- 超分辨率:接“上采样头”(常见是子像素/PixelShuffle 或卷积上采样)把分辨率抬高;
- 去噪 / 去压缩伪影:直接用卷积重建到输入同分辨率即可。
- 为什么分两类? 不同任务的输出尺寸/形式不同,所以重建头是任务相关的小改动,主干(RSTB 堆叠)通用。
D. 端到端的数据流(和你的图一一对应)
- 输入图像 → 浅层Conv 得到底层特征;
- 进入 RSTB × K:每块内部 STL×n → Conv → 残差;
- 串完所有 RSTB 后 → 重建头 输出高清图。
这条“浅层→深层→重建”的三段式,就是 SwinIR 的标准范式;论文明确“深层部分采用**残差堆叠的 Swin Transformer 块(RSTB)**做特征提取”。
E. 这套结构的工程意义
- 稳定:块级残差 + 层内残差,梯度好走、不易退化;
- 高效:窗口注意力把计算限制在小窗里,显存/计算都更省;
- 通用:只需替换最后的重建头,同一主干就能跑超分、去噪、去JPEG三大任务,论文在多项基准上验证了这一点。
一句话记忆
SwinIR = 浅层Conv打底 +(RSTB:STL×n→Conv→块级残差)×K 的深层主干 + 任务化重建头。 先把细节在“小窗”里看清楚,再层层融合、稳稳加回,最后按任务输出高清图。
模型的核心缺陷与不足
- “窗口注意力=局部为主”,全局依赖仍需多层“接力” SwinIR 的注意力先在 M×M 的局部窗口里算(W-MSA),然后靠移位窗口在相邻层做跨窗沟通。这让计算更省,但真正的“长距离交互”是逐层传播出来的,不像全局注意力一步到位;极端跨区域依赖可能需要更深堆叠才能触达。
- 对窗口大小敏感,任务不当会掉点 论文特别说明:做 JPEG 去伪影 时窗口从 8 改成 7,因为用 8(与 JPEG 的 8×8 块同频)性能会明显下降——说明窗口超参对不同退化类型比较敏感。
- 速度介于“慢的 Transformer”和“快的 CNN”之间 在 1024×1024 图上推理耗时:RCAN≈0.2s、SwinIR≈1.1s、IPT≈4.5s。SwinIR 比 IPT 快很多,但相较强 CNN 仍偏慢,部署实时性要权衡。
- 仍然“吃数据、吃大补丁”,最佳效果依赖更大训练块/更多图 作者做了消融:补丁越大、训练图片越多,PSNR 持续上升;虽不及 IPT 那样极度依赖海量数据,但要逼近上限,数据/补丁仍要加码。
- 多任务通用≠同一头能应万变,重建头仍需按任务改 主干(浅层+RSTB 堆叠)虽然通用,但重建模块要根据任务换:SR 用上采样(如子像素卷积),去噪/JPEG 用单卷积直出;也就是说,SwinIR 不是“零改动即通吃”,工程上仍需任务化配置。
- 真实场景 SR 需 GAN/感知等复合损失,训练更复杂 在真实场景超分中,作者采用 像素损失 + GAN 损失 + 感知损失 的组合来追求视觉质量,训练不如只用像素损失那么“稳和省”。
- 超参较多、实现复杂度高 一个可用配置就包含:K 个 RSTB、每个 RSTB 含 L 个 STL、窗口尺寸、通道数(常用 180)、注意力头数(常用 6) 等;这些超参对性能/显存/速度均有影响,调参成本不低。
一句话小结
**SwinIR 的优势在“效率与效果的折中”,但代价是:**注意力仍偏局部、对窗口/补丁等超参敏感,推理速度不及最强 CNN,真实场景要配合更复杂的训练策略。 把这些点记住,后续你在讲 Restormer / HAT / Swin2SR 等后续工作时,就能顺势解释它们为何继续在“更强的全局建模、更稳的训练与更高的效率”上做文章。