AlexNet(2012):基于深度卷积神经网络的图像分类
导出时间:2025/11/23 20:18:33
1、什么是饱和非线性模型
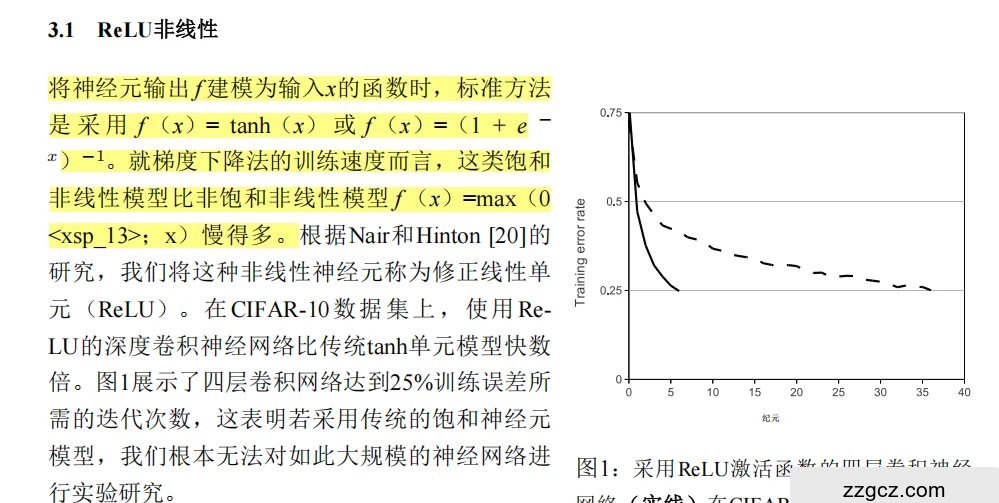
1. 饱和性(Saturation)导致梯度消失
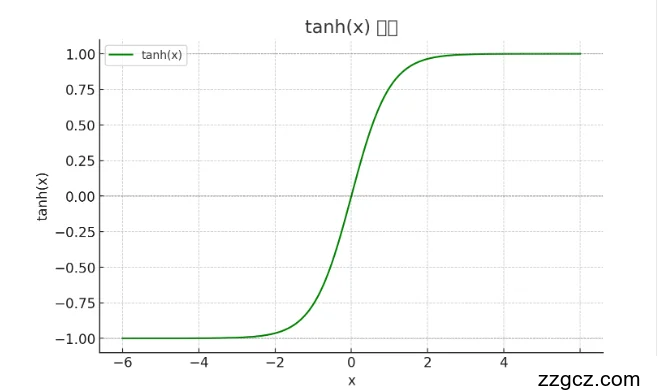
- tanh(x)
- 和 sigmoid(x) 都具有“饱和”特性:
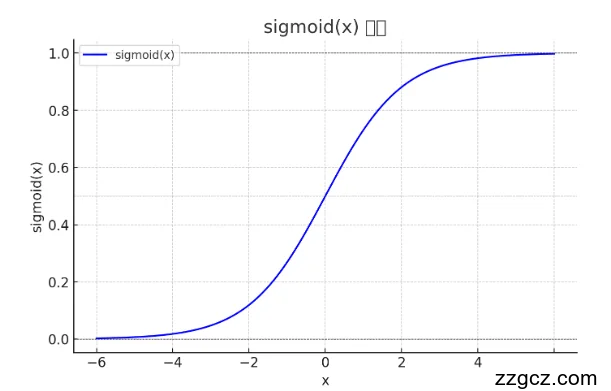
- 当输入 x 很大或很小时,函数输出会趋近于一个常数(如tanh趋近于±1,sigmoid趋近于0或1)。
- 此时,函数的导数(梯度)会趋近于零,因为曲线在饱和区的斜率几乎为零。
- 在反向传播中,梯度需要通过链式法则从后向前逐层传递。如果某一层的梯度接近零,那么前面所有层的梯度也会因连乘而迅速衰减,最终使得靠近输入层的参数几乎得不到有效更新,训练陷入停滞。
2. 非饱和函数(如ReLU)的优势
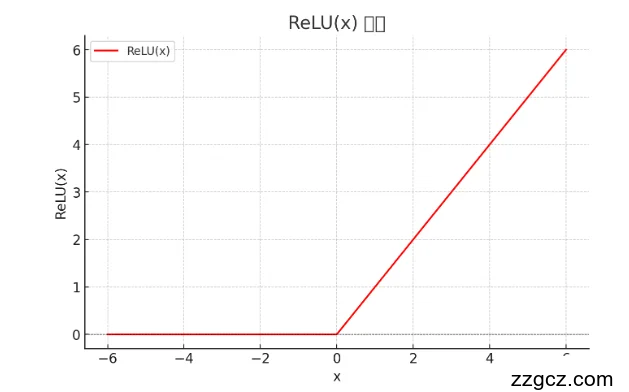
- ReLU函数 f(x)=max(0,x) 在正半轴的导数恒为1,不会因为输入增大而减小。
- 这意味着在正半轴,梯度不会衰减,能够稳定地传递到前面的层,从而加速了梯度下降的收敛。
- 此外,ReLU的计算更简单(只需比较和取最大值),也进一步提高了训练效率。
2、早期深度学习用多块 GPU 训练大模型的工程方法

当时(大约 2012 年前后)显卡显存很小,3GB 很容易被大型卷积神经网络占满。大网络需要存储权重、梯度、中间特征图等,如果显存不够,就无法一次性放下整个网络。
网络层中的神经元被一分为二,一半放在 GPU 1,一半放在 GPU 2。
不是每一层之间都进行跨 GPU 数据传输,因为通信很慢。
他们设计了一种“分层通信策略”:
- 第三层神经元要接收第二层所有神经元的数据(需要跨卡通信)。
- 第四层神经元只接收来自同一显卡的第三层神经元数据(避免跨卡传输)
- 这种方法的权衡
- 优点:减少 GPU 之间的通信量,降低瓶颈,让两块显卡的计算和通信负载更平衡。
- 缺点:因为不是所有神经元都全连接,可能在交叉验证(cross-validation)或模型泛化能力验证时带来一些挑战——结构不完全对称,可能影响性能评估。
3、整体网络架构

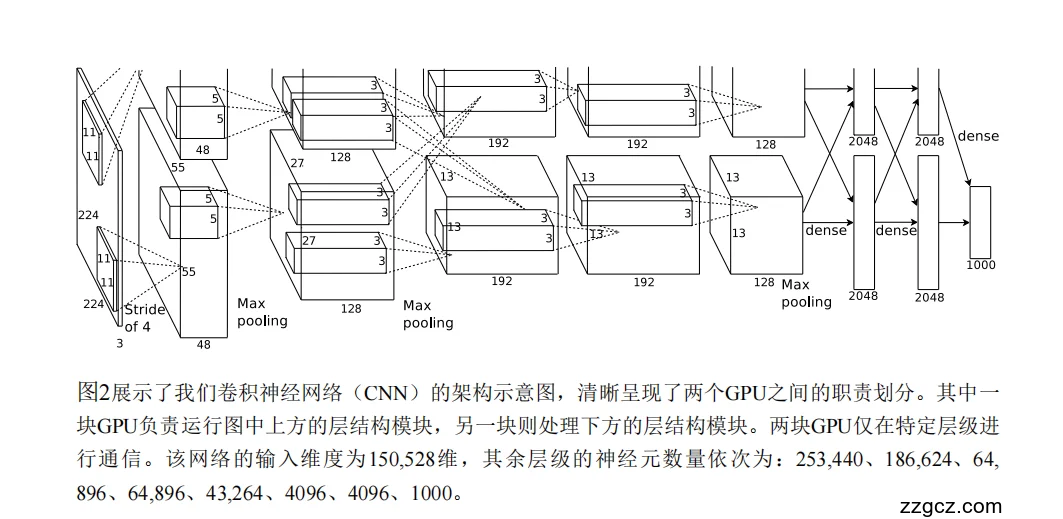
- 这台“机器”的结构
你可以把 AlexNet 想象成一条流水线,要把图片分到 1000 个分类里。
- 前面 5 道工序(Conv1~Conv5)是**“看图做特征提取”**:卷积层就是拿不同的“滤镜”去扫描图片,找颜色、边缘、形状等信息。
- 后面 3 道工序(FC6~FC8)是**“根据特征做决策”**:全连接层就像一个投票系统,把前面提取的特征综合起来决定是哪一类。
- 最后 softmax 把分数变成概率,告诉你这张图是猫的概率 80%,狗的概率 15%,其它加起来 5%。
- 为啥要两块 GPU?
想象你有一个超大的拼图(这个模型很大),一张桌子(显存)放不下,只能用两张桌子(两块 GPU)拼。
- 每张桌子各负责拼一半的拼图(GPU1 负责图里的上半部分,GPU2 负责下半部分)。
- 但有些拼图块需要跨桌子看一下(跨 GPU 通信),否则拼不出来。
- 为了不让两张桌子之间来回递东西太频繁(太慢),他们规定:
- 有些步骤(Conv2、Conv4、Conv5)只用本桌子的拼图块,互不打扰。
- 有些关键步骤(Conv3、全连接层)需要把两桌的拼图都放在一起看一眼。
- 各层干的活(用更生活化的比喻)
- Conv1(96 个大滤镜 11×11)
- 像用大号放大镜扫描图片,找出粗的边缘和大块颜色变化。
- Conv2(256 个中等滤镜 5×5)
- 用更精细的镜头看局部细节,分别在两张桌子上各干一半活。
- Conv3(384 个小滤镜 3×3)
- 第一次“合桌”开会,把两边的结果放一起再加工。
- Conv4、Conv5
- 又分桌子继续加工细节。
- 池化层(Max Pooling)
- 像把照片缩小,只保留最明显的特征。
- 全连接层(FC6~FC8)
- 全员大会,把所有特征拿出来综合判断。
- Softmax
- 最终投票,得出 1000 个类别的概率。
- 为什么这种方法很聪明
- 显存小也能训练大模型:把模型拆成两半放两块 GPU 上。
- 减少等待时间:不是每一步都跨 GPU 交流,只在必要的时候才沟通。
- 训练速度快很多:两张桌子一起干活,效率翻倍。
4、如何解决过拟合?

第一种增强:随机裁剪 + 水平翻转
- 原图先被缩放到 256×256。
- 从里面随机裁出 224×224 的小块(相当于轻微平移)。
- 对裁出的图做水平镜像翻转(左变右,右变左)。
- 训练时:
- 每次批量(batch)送进 GPU 之前,CPU 动态生成这些裁剪和翻转版本,不用提前存磁盘。
- 这样相当于 无限多 样本(虽然它们还是依赖原图),但已经大幅增加了多样性。
- 测试时:
- 用 10 张图来做投票:4 个角上的裁剪块 + 1 个中心裁剪块,再加上它们的翻转版本。
- 把 softmax 输出取平均作为最终预测。
第二种增强:PCA 颜色抖动(亮度与颜色变化)
- 对整个 ImageNet 数据集的 RGB 像素做主成分分析(PCA),找到颜色分布的 3 个主方向(p1, p2, p3)和强度(λ1, λ2, λ3)。
- 对每一张训练图片:
- 按这 3 个主颜色方向,随机加减一点颜色(强度乘上一个随机系数 αi)。
- αi 来自 均值 0、标准差 0.1 的高斯分布,所以变化幅度小但随机性足够。
- 效果:模拟现实中的光照、色温变化(比如阴天和晴天的同一物体颜色会略有不同),但物体本身还是一样的。
- 收益:top-1 错误率下降 1%+,说明泛化能力显著提升。