DeiT(2021):训练数据高效的图像Transformer & 通过注意力机制进行蒸馏,ViT的典型创新
导出时间:2025/11/23 20:24:03
1、研究背景
- 卷积神经网络(CNN)的统治地位 在深度学习图像任务中,卷积神经网络(CNN)一直是“王者”,比如 ResNet、EfficientNet。CNN 的优势是能很好地捕捉局部特征,但它的建模能力受限于卷积操作的局部性,很难直接捕捉全局依赖关系。
- Transformer 的跨界尝试 Transformer 在自然语言处理(NLP)中一炮而红(BERT、GPT)。后来 ViT(Vision Transformer)把这个思想引入图像领域:把图片切成一个个“小块”(patch),像处理句子里的词一样交给 Transformer。这种方法能天然捕捉全局特征,在大规模数据上性能超过 CNN。
- ViT 的瓶颈 但是,ViT 需要海量数据和超大算力才能训练好。原始的 ViT 是在 JFT-300M(3亿张图像) 这种超大私有数据集上训练的,这对大多数科研人员和普通实验室来说是不现实的。如果只用 ImageNet 1k 这样规模的数据集,ViT 的泛化能力就很差,效果远不如 CNN。
- PVT 的思路 PVT(Pyramid Vision Transformer)尝试借鉴 CNN 的“金字塔特征金字塔”设计,让 Transformer 更适合下游密集预测任务(如检测和分割)。但 PVT 主要改进了网络结构,对训练数据依赖的问题并没有彻底解决。
2、研究动机
DeiT 的出发点很直接:
👉 如何让普通研究者在有限数据(如 ImageNet 1k)和有限算力(单机多卡)条件下,也能成功训练高性能的 Transformer?
- 数据效率 不依赖超大规模数据集,只用 ImageNet 这样的公开数据集,也能训练出和 CNN 一样好,甚至更好的 Transformer。
- 训练效率 原始 ViT 要几周才能训练完,DeiT 的目标是:在单机(8 GPU)上,2~3天就能训好一个大模型。
- 知识蒸馏的新玩法 传统知识蒸馏是“教师教学生”,但主要传递输出概率。DeiT 提出了 “蒸馏标记(distillation token)”:把“老师的知识”直接作为一个新的 token 输入网络,让 Transformer 自己通过注意力机制来学习。这种方法让数据利用效率更高,特别是当“老师”是 CNN 时,学生(DeiT)能学到 CNN 的强归纳偏置,效果更好。
- 实际价值
- 让 Transformer 不再只是“大厂的奢侈品”,科研小白和普通实验室也能用。
- 证明了 Transformer 在图像任务中,不仅能超越 CNN,而且能做到 高效、实用、可迁移。
✅ 总结一句话:
DeiT 的动机就是要解决 ViT “又饿又挑食”的问题,让 Transformer 既能吃小数据,也能训得快,还能学得好,从而真正成为 CNN 的平替甚至超越者。
特点
| ViT (Vision Transformer)
| PVT (Pyramid Vision Transformer)
| DeiT (Data-efficient Image Transformer)
|
提出时间
| 2020 (Dosovitskiy)
| 2021 (Wang 等)
| 2021 (Touvron 等)
|
主要目标
| 将 NLP Transformer 直接应用到图像分类
| 改进 ViT,使其适合密集预测任务(检测、分割)
| 解决 ViT 的数据和算力依赖问题,让 Transformer 更高效可用
|
输入方式
| 将整张图像切分为固定大小的 patch(如 16×16)
| 引入 金字塔结构,分层处理特征,类似 CNN 的多尺度特征
| 输入同 ViT,但在训练方法上引入蒸馏标记和数据增强
|
关键设计
| - Class token 预测类别- 大量数据训练(JFT-300M)
| - 金字塔层次结构- 可变分辨率特征- 更适合检测/分割任务
| - 蒸馏标记(Distillation Token)- CNN 作为教师模型- 强力数据增强与优化策略
|
对数据依赖
| 极度依赖海量数据
| 比 ViT 略好,但仍需较多数据
| 数据高效,只需 ImageNet-1k 即可达到 SOTA 水平
|
计算资源需求
| 超算级别(TPU,数周训练)
| 相对较低,但仍不轻量
| 单机 8 GPU,2–3 天可完成
|
性能表现
| 大数据下能超过 CNN
| 在检测/分割等下游任务优于 ViT
| 在分类上超越 CNN(ResNet、EfficientNet),迁移性强
|
代表性实验结果
| ViT-B/16 在 ImageNet 上 ~77.9%(小数据时效果差)
| 在 COCO 检测/分割任务上显著优于 ViT
| DeiT-B 在 ImageNet 上 85.2% top-1 准确率(仅用 ImageNet 训练)
|
适用场景
| 大厂 + 大数据 + 超算
| 目标检测、分割等密集预测任务
| 科研小白、实验室环境、快速上手分类/迁移任务
|
3、DeiT 的核心创新点
1. 纯 Transformer 也能行,不靠卷积
- 以前的问题: 想让 Transformer 学会看图,需要给它看 几亿张图,像个“只会刷题的学霸”,没题就不会做。对普通实验室来说,这是根本做不到的。
- DeiT 的改进: 作者找到了一套“高效学习方法”:用数据增强、正则化、优化器调优,就像帮学生总结错题本、合理安排作息,结果只用 ImageNet 100 万张图 + 一台普通电脑,几天就能学好。
- 通俗理解: 👉 ViT 是“海量题海战术的学霸”,DeiT 是“聪明用方法的学霸”,少刷题也能拿第一。
2. 蒸馏 token:让学生多一个学习窗口
- 以前的蒸馏: 学生(Transformer)只模仿老师最后给出的答案(比如概率分布),像是背老师的作业答案。
- DeiT 的新招:
在 Transformer 里加了一个 新的学习位置——蒸馏 token。
- 类别 token = 正常学习课本知识(真实标签);
- 蒸馏 token = 专门学习老师的解题思路(教师模型的预测)。
- 通俗理解: 👉 就像学生在课堂上,一只耳朵听老师讲课(class token),另一只耳朵还戴着耳机听家教老师讲解(distill token)。这样学得更快更全面。
3. 请 CNN 当老师,比请 Transformer 当老师更靠谱
- 实验发现:
如果老师还是 Transformer,本来就缺乏“直觉”,教出来的学生进步有限。
但如果老师换成 CNN,效果更好。因为 CNN 天生有“直觉”:
- 能快速发现局部模式(比如眼睛、鼻子、边缘);
- 还能自动具备平移不变性(猫挪到左边还是猫)。
- DeiT 的妙处: 学生(Transformer)通过蒸馏 token,从 CNN 老师那“偷学”这些直觉,从而补上自己的短板。
- 通俗理解: 👉 Transformer 是“理论派学生”,CNN 是“经验派老师”。理论派跟着经验派学,就能又懂公式又会解题。
4、DeiT 的模型网络结构
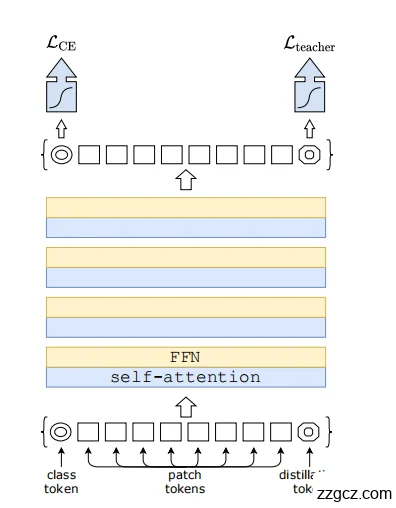
1. 输入部分
- Patch Tokens(方形小格子) 输入图像会被切分成多个小块(patch),每个小块经过线性投影后形成一个 token,整体就是一串 patch tokens。
- Class Token(左边圆形带C的标记) 这是从 ViT 继承来的特殊 token,用来收集全局信息,最终用于分类。
- Distillation Token(右边圆形带D的标记)
这是 DeiT 的创新点!
- 额外引入的一个 token,用来学习“教师模型”的知识。
- 它和 class token 一样,会和所有 patch tokens 一起进入 Transformer 编码器。
👉 输入序列 = [class token] + [patch tokens] + [distillation token]
2. Transformer 编码器堆叠
- 中间黄色/蓝色叠加的模块,表示多个 Transformer Block。
- 每个 block 包含:
- Self-Attention(自注意力):所有 token(class、patch、distill)彼此交互,互相交换信息;
- FFN(前馈网络):对每个 token 独立进行非线性映射;
- 残差连接 + LayerNorm,保证训练稳定。
- 经过多层堆叠后:
- Class token 会聚合全局图像信息;
- Distill token 会聚合教师模型传递的知识;
- Patch tokens 提供底层局部特征支持。
3. 输出部分
- Class Token → 分类头 → LCEL_{CE}LCE
- 这个输出对应真实标签(ground truth)。
- Loss 函数是 交叉熵损失(Cross Entropy, LCEL_{CE}LCE)。
- Distillation Token → 蒸馏头 → LteacherL_{teacher}Lteacher
- 这个输出对应教师模型的预测(teacher label)。
- Loss 函数是 蒸馏损失(LteacherL_{teacher}Lteacher),可以是 soft label 蒸馏或 hard label 蒸馏。
👉 训练时: 两个 loss 一起优化,学生(DeiT)既学真实标签,也学教师知识。
👉 推理时: 可以选择两个头结果平均,得到最终预测。
5、DeiT 模型的重大缺陷
虽然 DeiT 解决了 ViT 对“大数据 + 超算”的依赖,但它依然有一些核心缺陷:
1. 缺乏卷积归纳偏置
- DeiT 纯用 Transformer,没有 CNN 那种“局部性 + 平移不变性”的先验。
- 结果:
- 对小数据集或细粒度任务不够友好;
- 收敛速度慢,容易过拟合。
2. 过度依赖数据增强
- DeiT 的训练很大程度依赖 强力数据增强(RandAugment、Mixup、CutMix 等)。
- 如果换到 医学影像、遥感等小众数据集,这些增强方式未必适用,性能容易下滑。
3. 蒸馏机制的局限
- 蒸馏 token 是创新,但依赖 教师模型的质量:
- 教师如果是弱 CNN,学生(DeiT)也学不到好的归纳偏置;
- 如果任务和教师差异大,蒸馏信息可能失效甚至误导。
4. 下游任务泛化不足
- DeiT 在 分类 上很强,但在 检测、分割 等任务表现一般。
- 原因:缺少 多尺度特征建模(CNN 的金字塔特征在这类任务中很重要)。
6、 基于 DeiT 的改进模型
很多后续工作针对上述问题进行了改进:
1. 增强归纳偏置
- ConViT (2021) 在注意力中加入 卷积引导门控机制,让模型既能学全局,又保留 CNN 的局部先验。
- LeViT (2021) 结合卷积和 Transformer 的优点,结构更轻量。
2. 多尺度建模
- PVT (2021) 引入 金字塔结构,获得多尺度特征,更适合目标检测、分割。
- Swin Transformer (2021) 提出 滑动窗口注意力,既保留局部性,又逐层扩大感受野,成为检测/分割新基线。
3. 高效轻量化
- MobileViT (2022) 把 ViT 带到移动端,结合轻量卷积和 Transformer。
- EfficientFormer (2022) 优化注意力计算,专注于速度和部署。
4. 改进蒸馏与训练方式
- Self-Distillation Transformer 不依赖外部教师,靠自己不同层之间互相蒸馏;
- Intermediate Feature Distillation 不只是学教师的输出,还学中间特征,让蒸馏更稳定。
🌟 总结
DeiT 的重大缺陷主要是:
- 缺乏卷积归纳偏置;
- 对数据增强依赖过大;
- 蒸馏效果依赖教师质量;
- 泛化到下游任务不足。
后续改进方向可以归纳为四类:
👉 结构改进(ConViT, LeViT)
👉 多尺度设计(PVT, Swin)
👉 轻量高效(MobileViT, EfficientFormer)
👉 蒸馏与训练策略优化(Self-Distillation 等)