Inception v2!v3(2015):重新思考计算机视觉的架构-引入多尺度创新
导出时间:2025/11/23 20:20:18
1、研究背景和动机
想象一下:
- 早期的深度学习模型,就像“老式照相机”,镜头固定,看到什么就只能照出来什么,缺乏灵活性。
- Inception v1 的出现,相当于给相机装上了多种镜头(大镜头、小镜头、长焦、广角),同一张照片可以同时从不同角度拍摄,效果更清晰、更全面。
但是,用久了之后,人们发现:
- 模型越来越大,计算量爆炸
- Inception v1 虽然聪明,但层数和分支一多,计算就变得越来越庞大,像是拿着一个巨型相机拍照,成本太高。
- 训练越来越难
- 网络一旦变深,就像叠积木一样,不仅容易“倒塌”(训练不收敛),而且调参很麻烦。
- 实际效果还没到极限
- 虽然 Inception v1 已经比同期的 AlexNet、VGG 好很多,但研究人员相信:
- 如果能让结构更合理,
- 训练更稳定,
- 计算更高效, 那么性能一定还能大幅提升。
- 虽然 Inception v1 已经比同期的 AlexNet、VGG 好很多,但研究人员相信:
于是,谷歌团队就提出了 Inception v2 和 Inception v3:
- Inception v2 → 主要针对“计算效率”和“训练稳定性”改进,让网络更快更稳。
- Inception v3 → 在 v2 的基础上,进一步精细化模块设计和正则化技巧,让准确率更高。
🌟 形象比喻
- Inception v1 就像是一台“多镜头相机”,同时拍大图、小图、细节图。
- Inception v2 就像是给相机加了“自动对焦+防抖”,让拍照更稳,速度更快。
- Inception v3 就像是相机加了“专业后期处理”,照片细节更丰富,效果更逼真。
👉 一句话总结:
Inception v2/v3 的研究动机就是:如何在保持多尺度特征提取优势的同时,让模型训练更稳定、计算更高效、性能更强大。
2、模型的创新点
(一)Inception v2 的创新点
Inception v2 主要是“在 v1 的基础上,解决效率和稳定性问题”。可以理解成:让相机更轻、更稳、更快。
1. 大卷积分解成小卷积
- 原来用 5×5 的卷积核(相当于“大镜头”),计算量很大。
- v2 把它拆成两个 3×3 卷积核串联,既省计算量,又能学到更复杂的特征。
- 比喻:原来是“一次拿一个大扫帚扫地”,现在改成“用两把小扫帚分步骤扫”,效率更高。
2. 加入 Batch Normalization (BN)
- BN 的作用是让训练更稳定,收敛更快,避免深层网络训练困难。
- 比喻:就像“在相机上加了防抖功能”,即使镜头很多,画面也不会抖得一团糟。
3. 网格缩减(Grid Reduction)
- 在需要缩小特征图的时候,不是单纯用池化(会丢失很多信息),而是设计了 卷积分支 + 池化分支并行 的结构,既能减少分辨率,又能保留更多特征。
- 比喻:像“缩小照片时,同时保留高清原图的关键部分”,画面更清晰,不会模糊掉重要细节。
(二)Inception v3 的创新点
Inception v3 则是在 v2 的基础上,更精细地优化结构,追求更高的准确率。可以理解成:在相机上加了更专业的镜头组合和后期处理功能。
更彻底的卷积分解
- 不只是把 5×5 分解成 3×3,还进一步把 3×3 分解成 1×3 和 3×1;
- 在更深层,还把 7×7 分解成 1×7 和 7×1,既保持大感受野,又节省算力。
- 比喻:原来是一块大方镜子,现在拆成细长镜子拼起来,轻便又高效。
改进的正则化(防止过拟合)
- 使用 标签平滑(Label Smoothing),让模型预测更柔和,泛化能力更强。
- 比喻:修图时不过度拉高某个颜色,而是柔和过渡,看起来更自然。
辅助分类器的改进
- 继续保留 Auxiliary Classifier,并在分支中加入 BN(批归一化);
- 不仅帮助梯度传播,还作为额外的正则化器。
- 比喻:给副相机也加上了防抖和滤镜,辅助照片更稳定可靠。
改进的训练策略
- 引入 RMSProp 优化器,更适合深度网络训练;
- 使用 梯度裁剪(Gradient Clipping),防止梯度爆炸。
- 比喻:像给相机加上“安全阀”和“自动调节光圈”,避免曝光过度或抖动太大。
3、模型的网络结构
我们先记住一个核心思想:
👉 Inception 系列就是“多镜头相机”,同时用不同大小的卷积去看图像。
(一)基本骨架
无论 v2 还是 v3,整体骨架都类似:
- 输入层(相机镜头开机,看到图像)
- 卷积层 + 池化层(先做简单的边缘、颜色检测)
- 多个 Inception 模块串联(相当于一组“镜头阵列”,不同大小的卷积并行工作)
- 全局平均池化 (GAP)(把特征“压缩成一张概要图”)
- 全连接层 / softmax 分类(输出结果,比如“猫/狗”)
(二)Inception 模块的结构
一个 Inception 模块 就像是一个“分光镜”,把输入的特征图分成几路,然后再合并:
- 1×1 卷积:快速提取局部细节,相当于“放大局部小点”。
- 3×3 卷积:捕捉中等范围特征,相当于“中号镜头”。
- 5×5 卷积:捕捉大范围特征,相当于“广角镜头”。
- 池化 + 1×1 卷积:做一个“整体模糊观察”,再用小卷积提炼,像是“缩略图”。
最后,这几路的结果再“拼接”到一起,就得到了既有细节又有全局的特征图。
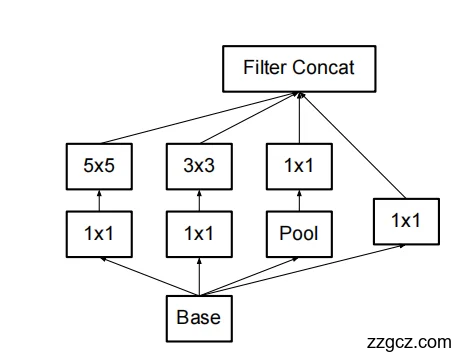
(三)v2 的结构特点
- 用 两个 3×3 代替 5×5(省算力)。
- 所有卷积层前面都加了 Batch Normalization(防抖,更稳)。
- 整体堆叠了 多个 Inception v2 模块,深度更大。
👉 可以想象:v2 的相机有“标准镜头阵列”,每个镜头都加了防抖装置,拍照更轻便更稳。
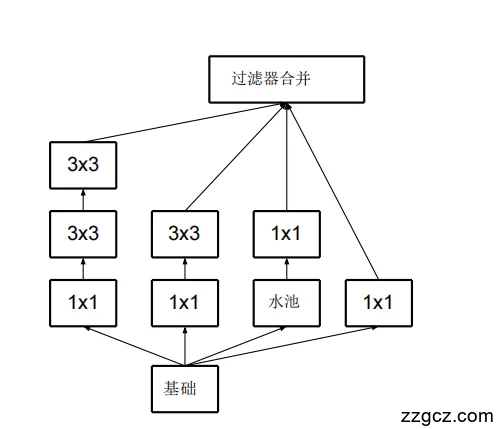
(四)v3 的结构特点
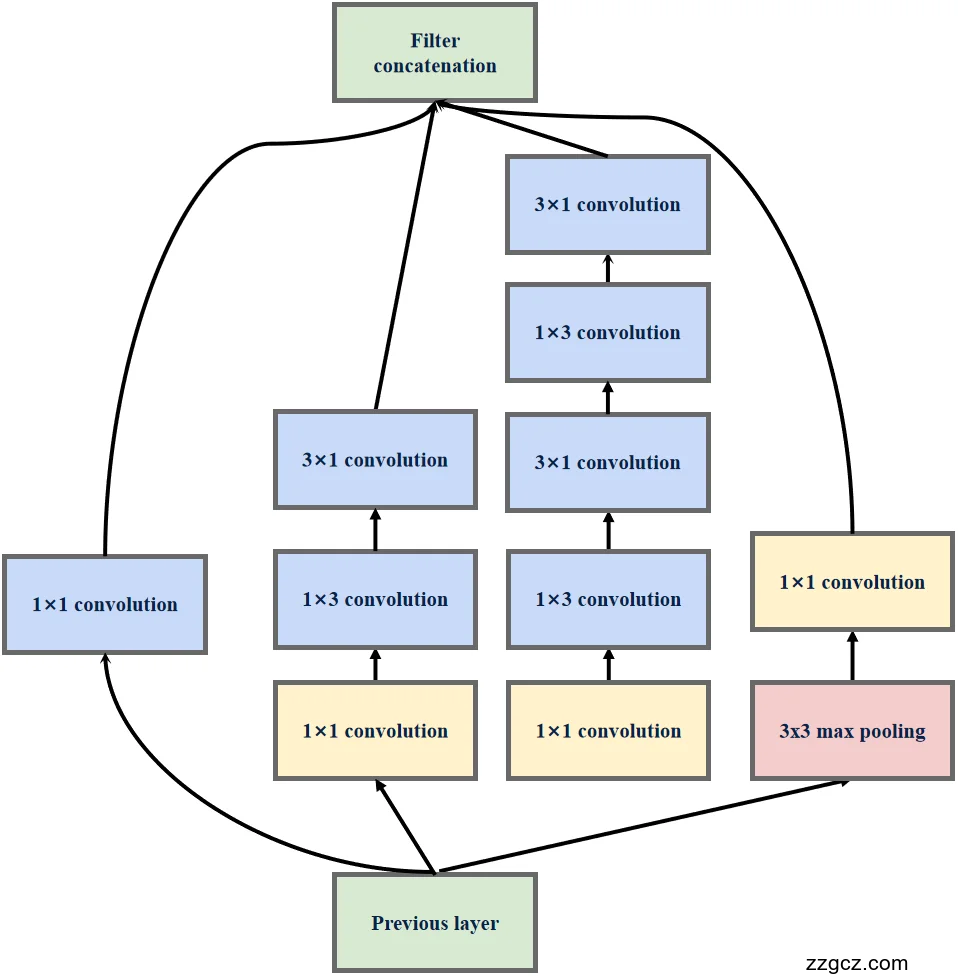
- 卷积分解更彻底:
- 把 3×3 → 1×3 + 3×1,进一步减少计算。
- 有些模块用了“非对称卷积”,让结构更灵活。
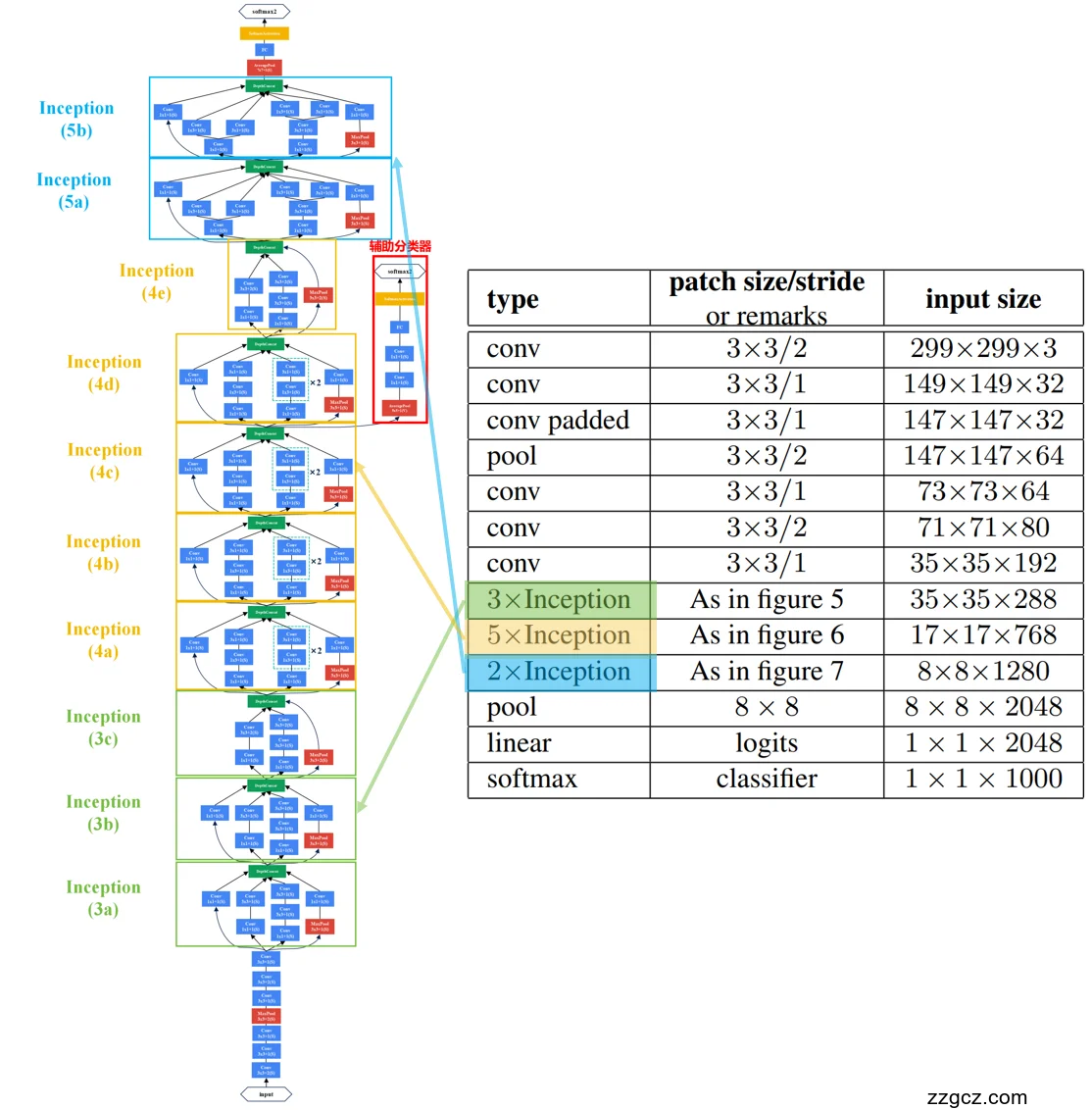
- 输入层
- 输入尺寸:299×299×3(RGB 彩色图片)。
- 之所以比 AlexNet (227×227) 或 VGG (224×224) 更大,是为了给更深的网络提供足够的空间做卷积操作。
- Stem 模块(初始卷积+池化)
- 一系列 7×7、3×3 卷积和 最大池化操作,用来快速压缩图片大小,同时提取初步特征。
- 结果:输入 299×299×3 → 35×35×192。
- 作用比喻:像相机的前置镜头,先对原始画面做基础对焦和降噪。
- Inception 模块堆叠
这是 v3 的核心部分,分为三大类模块:
(1) Inception-A 模块 (35×35)
- 共 3 个,输入大小 35×35×288。
- 特点:使用 1×1 卷积 + 3×3 卷积分解(原来 5×5 分解为两个 3×3)。
- 作用:在保持较大空间分辨率的同时,降低计算量。
- 比喻:像同时拍全景照片,但用小镜头拼起来更省力。
(2) Inception-B 模块 (17×17)
- 共 5 个,输入大小 17×17×768。
- 特点:引入 因子分解的卷积(比如 7×7 分解成 1×7 和 7×1),大幅降低计算量。
- 作用:在更小的特征图上,提取更抽象、更大感受野的特征。
- 比喻:像长焦镜头,可以捕捉远处细节。
(3) Inception-C 模块 (8×8)
- 共 2 个,输入大小 8×8×1280。
- 特点:进一步使用 1×3 和 3×1 卷积分解,并且增加更多 1×1 卷积来压缩通道数。
- 作用:在最后阶段融合多尺度特征,为分类器准备高维语义特征。
- 比喻:像微距镜头,可以捕捉极细小的特征。
- 辅助分类器(Auxiliary Classifier)
- 在 **17×17 层(Inception 4e 后)**接一个支路:卷积 + 全连接 + softmax。
- 用于辅助训练,增强梯度传播,并引入 BN 提高稳定性。
- 比喻:相当于训练过程中的“副相机”,在主相机训练时提供额外反馈,保证不跑偏。
- 最后分类部分
- 全局平均池化 (Global Average Pooling, GAP):将 8×8×2048 → 1×1×2048。
- 全连接层 (Linear logits):2048 → 1000(ImageNet 1000 类)。
- Softmax:输出每个类别的概率分布。
- 比喻:像摄影后期处理,把所有镜头拍到的图像合成为最终一张成品照片并输出分类结果。
4、模型缺点
- 网络结构过于复杂
- Inception v3 引入了多种卷积分解、不同类型的 Inception 模块(A/B/C)、辅助分类器、BN、标签平滑等设计。
- 整个网络包含 数十个子模块,结构分支非常多,实现和调试难度大。
- 影响:对工程师和研究人员来说,不如 VGG 那样直观简洁,移植和改造的成本较高。
- 比喻:就像一台专业相机,功能很多但操作复杂,不适合新手快速上手。
- 计算与显存开销仍然较大
- 尽管做了卷积分解,但 Inception v3 依然比 ResNet 等后续架构在速度和内存占用上更重。
- 特别是大输入图像(299×299)和多分支并行结构,造成训练和推理时 GPU 负担较大。
- 影响:在资源有限的移动端或嵌入式设备上难以部署。
- 模块化结构不够统一
- Inception v3 的设计仍然依赖 人工经验,模块间差异大(A/B/C 结构不同)。
- 这种“手工调参”的方式使得结构不够统一,不像 ResNet 那样简洁的“残差块”可以无限堆叠。
- 影响:后续研究难以在 v3 基础上继续做统一扩展,逐渐被 ResNet 系列取代。
- 对超参数和训练技巧依赖较强
- Inception v3 依赖 RMSProp、梯度裁剪、BN 辅助分类器、标签平滑等多种训练技巧才能稳定收敛。
- 如果训练配置稍有不当,模型性能可能明显下降。
- 比喻:像一辆高性能赛车,需要经验丰富的车手和精细调教才能发挥实力。
📌 小结
Inception v3 的缺点主要体现在:
- 设计复杂、实现困难
- 计算量大,难以在轻量场景部署
- 缺乏统一的模块化设计
- 对训练技巧依赖较强
这也是为什么在 v3 之后,研究界逐渐转向更简单、统一的 ResNet、DenseNet 等架构。
5、后续基于 inception的改进创新模型
1. Inception v4(2016)
📖 论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(arXiv:1602.07261)
- 动机:v3 依然较为复杂,于是 v4 进一步系统化 Inception 模块,让结构更清晰。
- 创新点:
- 模块化更统一:将 Inception 模块分为 Stem、Inception-A、Inception-B、Inception-C、Reduction-A、Reduction-B,更易组合和扩展。
- 网络更深:超过 40 层,能提取更丰富的特征。
- 效果:在 ImageNet 分类任务上进一步提升精度,结构比 v3 更规整。
Inception-ResNet v1/v2(2016)
📖 同一篇论文提出
- 动机:结合 Inception 的高效多尺度卷积与 ResNet 的残差连接优势。
- 创新点:
- Inception 模块 + Residual connection:在每个 Inception 模块后增加残差结构,让训练更稳定。
- 两种版本:
- Inception-ResNet-v1:比 Inception v3 稍浅。
- Inception-ResNet-v2:比 Inception v4 更深。
- 效果:训练更快,准确率更高,成为当时 ImageNet 最强的模型之一。
Efficient Inception 系列(轻量化方向)
- 后续在移动端部署时,研究者借鉴 Inception 思想提出:
- Inception-SSD(目标检测,结合 Inception 和 Single Shot MultiBox Detector)。
- MobileNet / Xception(虽然不是直接的 Inception,但继承了“分解卷积”的思路,用深度可分离卷积替代传统卷积)。
- 特点:更轻量,适合手机和嵌入式设备。