MobileNet v2(2019):逆向残差和线性瓶颈,倒残差结构
导出时间:2025/11/23 20:22:26
1、 研究背景和动机
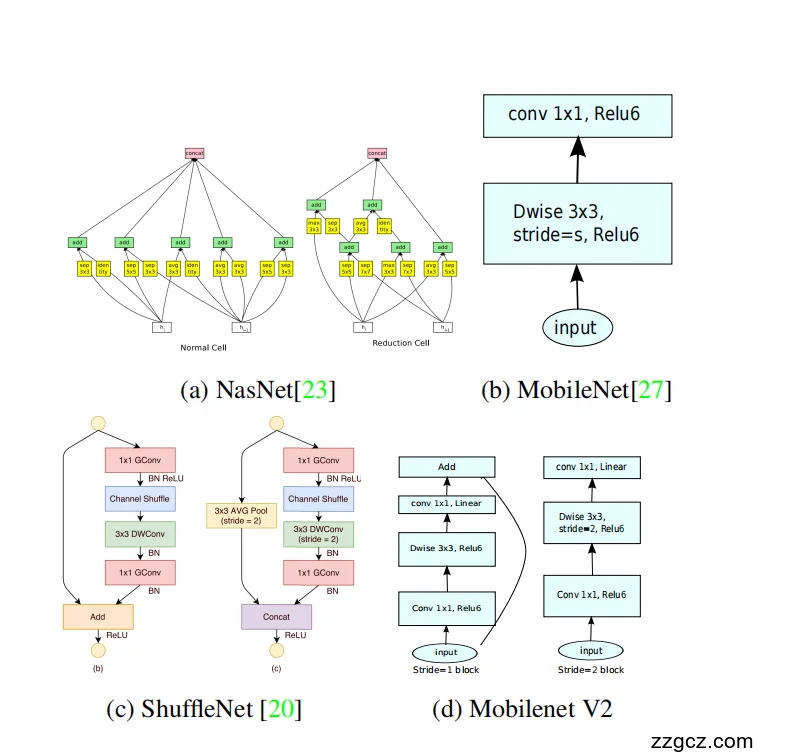
- 背景:轻量化卷积网络的持续发展
深度学习模型越来越大,效果越来越好(比如 ResNet、Inception),但是:
- 在移动端/嵌入式设备:算力有限,内存小,模型必须小巧、速度快。
- 挑战:如何在“小模型”里还能保留“大模型”的表达能力?
于是出现了三条主要探索路线:
📍 (a) NASNet(2017)
- 思路:让 AI 自己搜索网络结构(Neural Architecture Search,NAS)。
- 特点:结构复杂,像一个“超级工厂”,分很多工位(normal cell、reduction cell)。
- 问题:虽然效果好,但太大太复杂,不适合移动端。
📍 (b) MobileNet v1(2017)
- 思路:用 Depthwise + Pointwise 卷积 分解普通卷积,极大减少计算量。
- 类比:把一个大工厂切分成流水线(深度可分离卷积),每个人只做一件事。
- 问题:虽然很快,但表达能力不足,信息损失严重,精度比 ResNet/Inception 低。
📍 (c) ShuffleNet v1(2017)
- 思路:发现 1×1 卷积计算量大,于是用 分组卷积(Group Conv)+ 通道打乱(Channel Shuffle) 进一步加速。
- 类比:分工更细,每个小组只负责部分任务,再通过“洗牌”打乱重组,保证信息流动。
- 问题:信息流还是不够顺畅,而且结构更复杂,难以进一步扩展。
👉 但是,这些方法虽然“轻”,但在精度和表达能力上还是存在 明显瓶颈
- 动机:如何在“轻量化”和“表达能力”之间找到平衡?
MobileNet v2 提出了两个关键思路:
- Inverted Residual(倒残差结构)
- 传统残差网络 (ResNet) 是 先压缩通道,再扩展;
- MobileNet v2 反过来,先扩展再压缩,把信息保存在高维空间里处理,避免信息在低维里丢失。 👉 类比:好比你要在 A4 纸上写很多字,先把纸展开成更大的白板写完,再缩小成总结笔记,这样信息不容易丢。
- Linear Bottleneck(线性瓶颈)
- 传统卷积层末尾常用 ReLU 激活,但在低维特征上加 ReLU 会“砍掉”很多信息。
- MobileNet v2 在瓶颈层取消 ReLU,只保留线性映射,保证信息完整传递。 👉 类比:好比你在压缩文件的时候,不做无损压缩,而是直接删掉一部分 → 信息丢失。MobileNet v2 用“线性瓶颈”避免了这种丢失。
2、MobileNet v2 的模型网络结构
2.1、线性瓶颈到底解决了什么?

图1展示了嵌入高维空间的低维流形经过ReLU变换后的 典型示例
1)先看图里在讲什么
图中的蓝色螺旋是一条 低维流形(本质上是 2D 的“曲线/面”),先被嵌入到更高维空间(dim=2/3/5/15/30),经过一次线性变换 + ReLU,再投影回 2D。
你会看到:
- 当嵌入维度 很低(dim=2,3) 时,ReLU 会把流形的一些区域压扁/粘在一起(不同点被映射成同一点),信息“塌缩”最明显。
- 当嵌入维度 较高(dim≥15) 时,虽然形状变得更复杂(非凸),但整体结构还在,信息不至于被“压没”。
直观结论:在低维空间里对特征再做 ReLU,极容易造成信息不可逆丢失;而在高维空间里做 ReLU,余地更大,不容易把结构“压塌”。
2)回到 MobileNet v2 的倒残差块
倒残差块做的事是:
先扩展通道(高维) → 再用 DWConv 提取空间特征 → 最后压回低维(瓶颈)。
激活函数的安排刚好与图里的观察一致:
- 扩展层(1×1 conv,升维):用 ReLU6(在高维里非线性更“安全”)。
- DWConv(3×3):用 ReLU6(仍在高维里做非线性)。
- 投影层(1×1 conv,降到低维瓶颈):不用 ReLU,线性输出(这一步在低维,避免信息被 ReLU 压塌)。
- 残差连接:当输入输出维度相同且 stride=1 时,把输入直接加回来,进一步保护信息路径。
小结:非线性放在高维,低维只做线性传递——这就是“线性瓶颈”。
3)为什么低维用 ReLU 危险?(再形象一点)
- 想象你把一张彩色图(RGB)压成少量“要点通道”(低维瓶颈)。每个通道都很宝贵。
- 在低维上用 ReLU 就像“把所有小于 0 的值一刀切成 0”,等于直接把一部分细节删掉;而且 ReLU 的导数在负半轴为 0,梯度也传不回去。
- 高维里通道多、冗余度高,ReLU“切掉”的部分更容易被其它通道弥补;低维里“每一口粮都很重要”,一刀切就可能不可逆地丢掉判别信息。
- 图里的螺旋就是这种“塌缩”的直观演示:低维 + ReLU → 点与点黏在一起。
2.2、倒残差结构
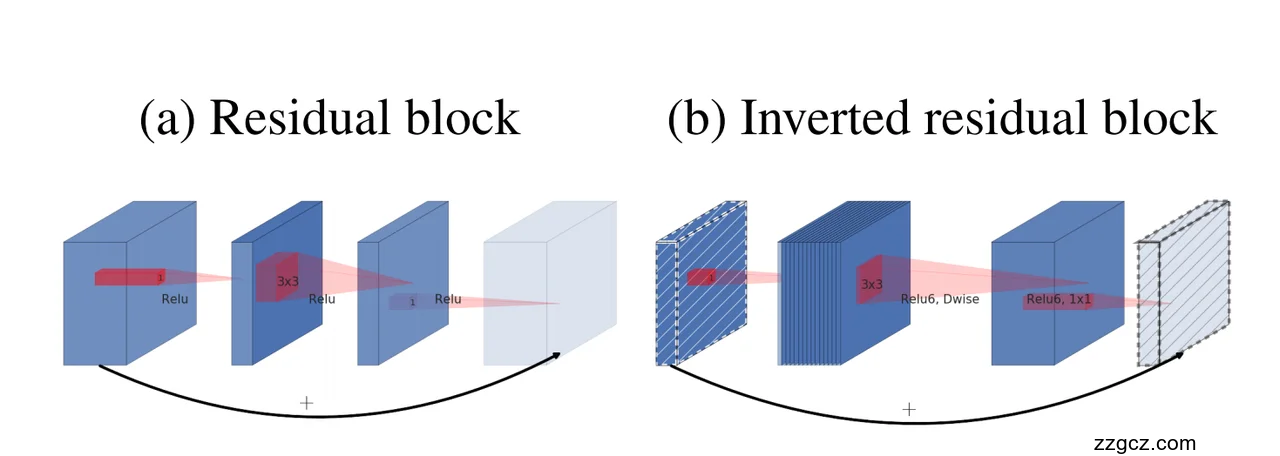
1)回顾传统残差块 (a)
在 ResNet 的瓶颈残差块中,结构是 两头大,中间小:
- 输入通道多 → 压缩(1×1 Conv 降维) → 中间 3×3 Conv 处理 → 再扩展(1×1 Conv 升维) → 输出通道多。
- 这样做的主要目的是 减少中间 3×3 卷积的计算量,因为 3×3 是最耗时的部分。
- 在每个卷积层后面加上 ReLU 激活,增加非线性。
👉 缺点:
- 当压缩到低维度后继续加 ReLU,容易带来 信息丢失(前面 Linear Bottleneck 已经解释过),残差结构虽然缓解梯度消失,但信息仍然可能丢掉。
2)倒残差块 (b)
MobileNet v2 提出的 Inverted Residual Block,名字就说明了:
它反转了传统瓶颈残差块的设计思路。
- 两头小,中间大: 输入低维 → 1×1 Conv 升维(扩展通道) → 3×3 Depthwise Conv 提取空间特征 → 1×1 Conv 降维(线性瓶颈输出) → 输出低维。
- 关键点 1:中间扩展 → 高维加 ReLU 在高维通道空间里加 ReLU,即使丢掉一部分信息,其他通道还能补偿(信息冗余更大)。
- 关键点 2:两头小 → 低维不加 ReLU(线性瓶颈) 在输入和输出的低维空间,直接保持线性传递,不做 ReLU,以防止低维特征“塌缩”,避免信息不可逆丢失。
- 关键点 3:计算量仍然很小 因为 3×3 卷积换成了 Depthwise Separable Convolution(逐通道卷积),计算复杂度大幅下降,即使扩展到高维,计算成本也能接受。
3)为什么叫“倒残差”?
对比一下:
- ResNet 残差块:输入 → 压缩 → 中间小维度处理 → 再扩展 → 输出大维度。
- MobileNet v2 倒残差块:输入小维度 → 扩展 → 中间大维度处理 → 压缩 → 输出小维度。
所以称之为 Inverted Residual(反向的残差块)。
残差连接依然存在,当输入输出维度一致时,信息可以直接跳过卷积层(保证梯度流畅、信息保护)。
4)你的图里可以直观看出:
- (a) Residual block:小 → 大(3×3)→ 小,ReLU 在低维也用了。
- (b) Inverted residual block:大部分 ReLU 放在 扩展的高维度(中间),两头的小维度只做线性映射,信息传递更安全。
5)一句话总结
倒残差结构就是:
把“卷积运算放在大空间里做”,而“信息传递放在小空间里走”,并且小空间保持线性,不加 ReLU。
3、基于 MobileNet v2 的改进模型
- MobileNet v3(2019)
- 改进点:结合 NAS(神经架构搜索) + SE 注意力机制 + 新激活函数 h-swish。
- 优势:比 v2 更快更准,在移动端推理效率大幅提升。
- 📌 是 v2 的官方升级版,谷歌团队提出。很多论文在轻量化对比时都会拿 v3 做 baseline。
- EfficientNet 系列(2019)
- 改进点:基于 MobileNet v2 的 MBConv(倒残差模块),通过 复合缩放策略(宽度+深度+分辨率) 提升性能。在 ImageNet 上创造了 SOTA 记录。
- 优势:EfficientNet-B0 到 B7,以及后续的 EfficientNetV2 都是热门 baseline。
- 📌 属于 MobileNet v2 模块的 “升级加强版”。几乎所有和轻量化 / 高效 CNN 相关的论文都会引用 EfficientNet。
- FBNet(2019)
- 改进点:基于 MobileNet v2 的结构,使用 NAS 搜索更符合硬件特性的网络。
- 优势:比手工设计更高效,适配移动设备。
- ProxylessNAS(2019)
- 改进点:改进 NAS,直接在目标硬件(如手机 GPU)上搜索 MobileNet v2 风格的结构。
- 优势:比 v2 更加“硬件友好”。
- MnasNet(2019)
- 改进点:谷歌提出,结合 MobileNet v2 模块 + 强化学习搜索。
- 优势:在 ImageNet 上精度与速度平衡更好。
- MixNet(2019)
- 改进点:基于 MobileNet v2 的卷积分支,提出 多尺度深度可分离卷积(Mixed Depthwise Convolution)。
- 优势:提升不同尺度特征的表达能力。
- MobileNeXt(2020)
- 改进点:分析了 MobileNet v2 倒残差的不足,提出 Sandglass block(沙漏块) 替代。
- 优势:比 v2 更稳健,在小模型下表现更好。