Network in Network (2014):网络中的网络
导出时间:2025/11/23 20:20:04
1、研究背景和动机
一、研究背景
想象一下,你在教小朋友认猫:
- 传统方法(普通CNN) 小朋友只会看一个特征,比如“耳朵尖尖的就是猫”。于是他拿着尺子(卷积核),量一量耳朵的形状,如果差不多就判定是猫。
- 但问题来了:
- 如果猫换了角度,耳朵看起来不一样了?
- 如果光线暗一点,看不清楚?
- 如果是卡通猫、玩偶猫呢?
- 这种“单一标准”就很容易出错。
- 现实情况 猫有各种形态:趴着、站着、卷成团;还有不同的花纹、毛色。用一个简单的尺子去判断,根本抓不住所有情况。
换句话说,传统CNN的卷积层就像是“只会用直尺量”的小孩,处理图像的方式太死板。它默认世界是“线性的”,而现实却复杂得多。
二、研究动机
研究者们想解决两个问题:
- 让“眼睛”更聪明
- 普通卷积核就像一个死板的尺子。
- NIN 的想法是:把这个尺子换成一个 小脑子(小神经网络)。
- 这样它不只是看耳朵,还能综合耳朵、胡须、眼睛的组合模式,一起判断是不是猫。
- 所以叫 网络中的网络:大网络里,每个小卷积核本身就是一个小网络。
- 让“结果”更直观,不容易过拟合
- 传统CNN最后有个“全连接层”,就像一个神秘黑箱,输入进去就吐出答案,但没人知道它到底在关注什么。
- NIN 把它换成了 全局平均池化,意思是:
- 每一张特征图直接代表某个类别,比如“猫图”、“狗图”、“车图”。
- 最后就看哪张图整体亮得最明显,就判定是哪个类别。
2、模型的创新点
1. 把“卷积核”变聪明了 —— MLPConv层
- 具体做法:把卷积核换成一个小型的神经网络(多层感知机 MLP)。
- 这样,每个卷积操作不再只是“加权求和”,而是小网络先分析,再输出结果。
- 等于说:原来“一个工人拿直尺”,现在变成了“一个工人+一个小助手团队”,能处理更复杂的情况。
👉 创新点:卷积不再只是“线性过滤器”,而是“小网络看小区域”,大大增强了局部特征的表达能力。
2. 丢掉“黑箱”,换成“平均投票” —— 全局平均池化(GAP)
- NIN 把它换成了 全局平均池化:
- 每个类别对应一张“热力图”(比如:猫图、狗图)。
- 最后直接算这张图里亮的程度(平均值),来判断图片属于哪个类别。
- 就像 “投票”:每张图自己投票,哪张图亮得最明显,就认定是那个类别。
👉 创新点:分类层变得直观透明(能解释),参数更少,不容易过拟合
3、模型的网络结构
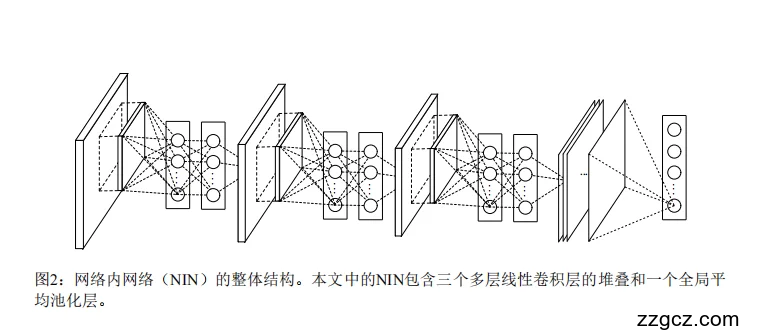
这张图展示了 NIN 的整体架构,它和传统 CNN 最大的不同点在于:卷积层不再是单一的卷积核,而是小型神经网络(MLPConv 层)。整个模型大致分为三部分:
- 多层感知机卷积层(MLPConv)
- 在普通 CNN 中,一个卷积层就是“滤波器 + 激活函数”。
- 在 NIN 里,每个卷积层被换成了 小网络:
- 输入图像的一小块区域(局部感受野),
- 会经过一个由多个全连接层组成的“小神经网络”,
- 输出一个更复杂、更灵活的特征表示。
在图中,你可以看到每一层里,不再是简单的卷积核,而是好几个小圆点连成的小网络,这就是 MLPConv。
- 堆叠多个 MLPConv 层
- NIN 网络不是只有一个这样的“聪明卷积层”,而是 连续堆叠了三个。
- 每一层都会把上一层的结果再加工,逐步提取更抽象、更高级的特征。
- 举个例子:
- 第1层:可能只是在看边缘、颜色小块;
- 第2层:会组合出一些小形状,比如眼睛、鼻子;
- 第3层:会组合成完整的物体,比如猫的脸、车的轮子。
👉 可以理解为:模型逐层把“像素”变成“零件”,再变成“部件”,最后拼成“整件物品”。
- 全局平均池化层(GAP)
- 普通 CNN 在最后通常接一个“全连接层”来做分类,这像是一个黑箱子。
- NIN 则是用 全局平均池化:
- 每个类别对应一张“特征图”(比如猫图、狗图)。
- 模型直接计算整张图的平均值,作为该类别的置信度。
- 最后再丢进 softmax,决定最终类别。
👉 这就像“投票机制”:每张特征图自己打分,哪个分数最高,就选哪个类别。
- 好处是:
- 直观:能看到模型究竟在关注哪里。
- 简洁:不需要庞大的全连接层,参数更少,更不容易过拟合。
- 整体结构总结
用一句话来概括图里的网络:
输入图像 → 三层 MLPConv(聪明卷积层) → 全局平均池化(投票) → Softmax 分类结果
或者更形象一点:
👉 NIN 就像一个工厂
- 前三层是“流水线工人 + 小助手团队”,一步步把零散像素加工成更高级的特征;
- 最后一层是“评审团”,直接投票决定这张图属于哪个类别。
4、模型❌ 缺点
1. 计算开销更大
- 普通卷积层只做“简单的加法和乘法”。
- NIN 的卷积层里嵌套了小网络(MLPConv),等于每次卷积都要跑一个小神经网络。
- 这会带来更高的计算量,训练时间更长,对硬件要求更高。
2. 结构比较复杂,不太直观
- 普通 CNN 的卷积层、池化层,思路清晰,容易理解。
- NIN 的 MLPConv 把“小网络嵌套进大网络”,对新手来说不太直观。
- 如果要调试和优化模型,难度会比传统 CNN 更大。
👉 比喻:
- 普通 CNN:像乐高积木,简单、容易堆。
- NIN:乐高套娃,每个积木里还有小积木,结构更复杂。
3. 在大数据集上的优势不明显
- NIN 在 CIFAR-10、CIFAR-100 这些小型图像数据集上效果很好。
- 但在更大、更复杂的数据集(比如 ImageNet)上,它的优势并没有完全体现出来,很快就被后来更强的模型(Inception、ResNet)超越了。
- 原因在于:NIN 的思路很好,但还不足以解决更大规模的学习难题。
4. 缺少通用性
- NIN 最初是为分类任务设计的(图片归类)。
- 它没有像后来的网络那样,在检测、分割、生成等任务上被广泛使用。
- 这限制了它的应用范围。
5、基于 NIN的改进创新
1. Convolution in Convolution (CiC)
- 论文名:Convolution in Convolution for Network in Network
- 作者:Yanwei Pang, Manli Sun, Xiaoheng Jiang, Xuelong Li
- 发表于:2016 年 (arXiv)
- 创新:将 NIN 中的“密集型 MLPConv”改为“稀疏 MLPConv”,在通道维度或通道–空间维度采用稀疏连接。采用未共享卷积与共享卷积相结合以减少参数,在 CIFAR-10/CIFAR-100 上获得了改进性能
- https://arxiv.org/pdf/1603.06759
2. DrNIN(Deep Residual Network in Network)
- 论文名:Deep Residual Network in Network (DrNIN)
- 作者:H. Alaeddine 等
- 发表时间:2020 年,已在 PMC 中开放获取
- 创新:结合残差连接(Residual Learning)与 NIN 思路,将 MLPConv 扩展为残差结构(DrMLPConv),改善网络深度可训练性,缓解梯度消失问题,在 CIFAR-10 上表现更好
- https://www.ijcaonline.org/archives/volume186/number75/kouka-2025-ijca-924633.pdf?utm_source=chatgpt.com
3. Densely Connected NIN (DcNIN)
- 论文名:Densely Connected Network in Network (DcNIN)
- 作者:Neji Kouka 等
- 发表时间:2025 年 (International Journal of Computer Applications)
- 创新:将 NIN 中的 MLPConv 层设计成“密集连接结构”(类似 DenseNet),即每一层 MLPConv 都与结构中其他层之间全连接,以增强特征复用与梯度流动
- https://pmc.ncbi.nlm.nih.gov/articles/PMC7925065/?utm_source=chatgpt.com