ResNet(2015):用于图像识别的深度残差学习
导出时间:2025/11/23 20:20:35
1、研究背景和动机
(1)深度学习的趋势
- 在 2012 年 AlexNet 大获成功后,研究者发现:更深的神经网络往往能学到更复杂的特征,准确率也更高。
- 因此大家不断堆叠卷积层,从 VGG-16、VGG-19 再到 GoogLeNet(Inception v1/v2/v3),网络越来越深。
(2)遇到的问题:深度瓶颈
但是,当层数继续增加时,出现了两个严重问题:
- 梯度消失/爆炸:层数过深导致训练难以收敛。
- 退化问题:不是过拟合,而是 更深的网络反而训练误差更大(比浅层网络还差)。
- 举个例子:10 层的网络比 5 层的表现好,但如果再加到 50 层,误差反而上升。
- 说明“盲目加深”并没有带来更好效果。
(3)ResNet 的核心动机
- 关键思路:让网络更容易训练深层结构。
- 在 ResNet 之前,训练超过 30 层的网络就非常困难。ResNet 利用残差块和快捷连接,首次成功训练 超过 100 层甚至 152 层 的深度网络。影响深远:开启了“残差架构时代”,成为后续深度模型设计的基石。
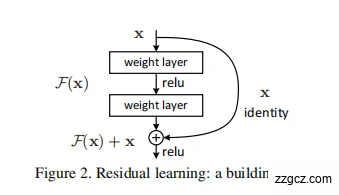
- 作者提出:与其让网络直接学习“完整的映射函数”H(x),不如只让它学习一个 残差函数 F(x) = H(x) - x。
- 这样原函数就变成 H(x) = F(x) + x,即“残差 + 输入”。
2、模型的创新点
(1)残差学习(Residual Learning)的提出
- 核心思想:网络不再直接学习目标映射 $H(x)$,而是学习一个残差函数 $F(x) = H(x) - x$。
- 最终输出是 $H(x) = F(x) + x$。
- 这样如果额外的层没学到东西($F(x)=0$),网络至少还能保留输入 $x$,性能不会变差。
比喻:
- 原来要从零开始写一篇文章($H(x)$),很难。
- 现在给你一份草稿(输入 $x$),你只需要改进里面不足的地方(残差 $F(x)$),就轻松很多。
(2)引入“快捷连接”(Shortcut Connection)
- 在每个残差块(Residual Block)中,输入 x 会通过一条“捷径”直接加到输出上。
- 这条捷径不增加额外参数,也不增加计算量。
- 它为 梯度反向传播 提供了一条快速通道,缓解了梯度消失的问题。
比喻:
- 像修高速公路时,在关键路段增加一条直达的“快速通道”,避免堵车。
- 梯度就像车流,可以畅通无阻地传递到更深层。
3、ResNet 的网络结构
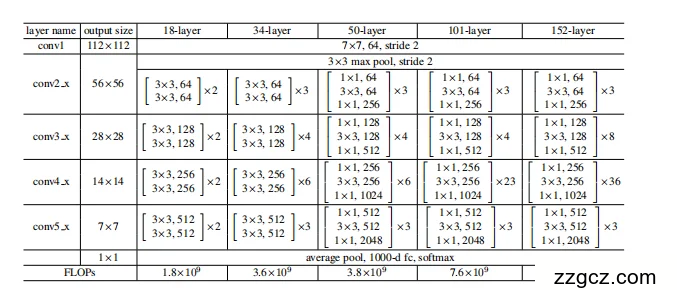
(1)整体结构
ResNet 的网络一般分为 五个阶段:
- 输入层(Input Layer)
- 输入:224 *224 的彩色图像。
- 经过:7×7 卷积(stride=2)+ BN + ReLU + 3×3 最大池化。
- 残差模块堆叠(Residual Blocks)
- ResNet-34 使用 基本残差块(Basic Block):两个 3×3 卷积。
- ResNet-50/101/152 使用 瓶颈残差块(Bottleneck Block):1×1 → 3×3 → 1×1 三层卷积。
- 不同阶段通过 下采样(stride=2) 逐步缩小特征图尺寸。
- 全局平均池化(Global Average Pooling, GAP)
- 将 7* 7特征图压缩成 1* 1,减少参数数量。
- 全连接层(FC Layer)
- 输出类别预测(如 ImageNet 的 1000 类)。
(2)残差块的结构
a) 基本残差块(Basic Block, 用于 ResNet-18/34)
输入 x → Conv(3×3) → BN → ReLU → Conv(3×3) → BN
↘———————————————(Shortcut)——————————↗
输出 y = F(x) + x
- 适合浅层网络,结构简单。
b) 瓶颈残差块(Bottleneck Block, 用于 ResNet-50/101/152)
输入 x → Conv(1×1 降维) → Conv(3×3 卷积) → Conv(1×1 升维)
↘—————————————————(Shortcut)——————————————↗
输出 y = F(x) + x
- 1×1 卷积 先降维,再升维,减少计算量。
- 适合超深网络(50 层以上)。
4、模型缺点
(1)结构复杂度高
- ResNet-50、ResNet-101、ResNet-152 等超深网络虽然效果好,但参数量大,计算开销高。
- 缺点:在嵌入式设备或实时应用中难以部署。
- 比喻:就像一支顶尖的交响乐团,虽然音效华丽,但上场人员太多,排练和演出成本极高。
(2)残差连接的“无效学习”问题
- 有些残差块可能会学不到有效的残差(接近 0),变成“恒等映射”。
- 这使得部分层“闲置”,网络的有效容量没有充分发挥。
- 比喻:就像团队里某些人只是“打酱油”,并没有真正贡献。
(3)优化并非完全解决梯度问题
- 虽然残差连接缓解了梯度消失,但在极深网络(如 >1000 层)时,训练仍然困难。
- 说明:ResNet 提出了残差思想,但不是万能药,仍需要配合 BN、合适的初始化和优化器。
(4)特征复用 vs 表达冗余
- ResNet 的 shortcut 让低层特征直接流向高层,导致特征复用明显。
- 但同时也带来特征冗余,不同层学到的表示可能过于相似,没有做到真正“高效表达”。
- 这也是后来 DenseNet(稠密连接网络)进一步改进的方向。
5、基于 ResNet 的后续改进模型
(1)Pre-activation ResNet(预激活版 ResNet, 2016)
- 改进点:把 Batch Normalization (BN) 和 ReLU 从卷积层后面移到残差块前面。
- 效果:
- 梯度在反向传播时更加顺畅,训练更稳定。
- 减少了深层网络的训练难度。
- 比喻:原来是“先做事,再调整”,现在变成“先热身,再做事”,更合理。
- 论文:Identity Mappings in Deep Residual Networks (ECCV 2016)
(2)ResNeXt(2017)
- 改进点:引入“分组卷积 + 分支结构”(cardinality,基数)。
- 思想:在保持层数和参数规模相近的情况下,增加网络的“宽度”(并行路径数)。
- 效果:比单纯加深/加宽更有效,提高了模型表达能力。
- 比喻:像是团队分工,把一个任务拆分成更多小组同时处理,效率更高。
- 论文:Aggregated Residual Transformations for Deep Neural Networks (CVPR 2017)
(3)DenseNet(2017)
- 改进点:所有层之间密集连接,每一层的输出都会传递给后续所有层。
- 关系:DenseNet 可以看作是 ResNet “特征复用思想”的极致化版本。
- 效果:减少冗余,提高参数效率,网络更轻量。
- 比喻:像微信群里,消息每个人都能看到和转发,信息共享最大化。
- 论文:Densely Connected Convolutional Networks (CVPR 2017)
(4)Wide ResNet(WRN, 2016)
- 改进点:减少网络深度,但显著增加每层通道数(宽度)。
- 效果:比原始深层 ResNet 更容易训练,性能不输甚至更优。
- 比喻:不是一味“堆高楼层数”,而是“加大楼层面积”,更稳更实用。
- 论文:Wide Residual Networks (BMVC 2016)
(5)Squeeze-and-Excitation ResNet(SENet, 2018)
- 改进点:在残差块中引入通道注意力机制(SE模块),通过“加权”强调重要特征,抑制无关特征。
- 效果:显著提升分类精度(ImageNet 2017 冠军)。
- 比喻:像摄影时自动对焦,把注意力集中在主体上。
- 论文:Squeeze-and-Excitation Networks (CVPR 2018)