ShuffleNet v1(2017):一种用于移动设备的极其高效的卷积神经网络,引入高效组卷积
导出时间:2025/11/23 20:22:03
1、 ShuffleNet v1:研究背景和动机
以前的模型像是“豪华工厂”(如 AlexNet、VGG、ResNet),产能强但耗电量大(计算量);MobileNet v1 像是“省电小工厂”,提出了 深度可分离卷积,极大减少了计算量,证明了“轻量化 CNN”是可行的。
- Depthwise + Pointwise 卷积 确实减少了 FLOPs,但在实际硬件(手机 CPU/GPU)上的速度提升 没有预期的那么大。
- 因为 1×1 卷积(Pointwise Conv)仍然占据了大部分计算量(约 90%)。
- 所以研究者们意识到:如果要进一步提速,必须减少 1×1 卷积的开销。
👉 类比:
在工厂流水线里,虽然大机器已经省电了(Depthwise Conv),但最后的“拼装工序”(1×1 Conv)依旧特别耗时,成了瓶颈。
- ShuffleNet 的核心动机
- 引入 分组卷积(Group Convolution):把通道分组,减少 1×1 卷积的计算量。
- 但分组卷积带来一个问题:通道之间信息交流减少,容易“各自为战”。
- 为了解决这个问题,ShuffleNet 提出了 Channel Shuffle(通道打乱):让不同分组的特征可以重新组合,保持信息流动。
👉 类比:
- 分组卷积 = 把工人分成不同小组,各自负责一部分任务,效率更高。
- Channel Shuffle = 每隔一段时间换工人岗位,让不同小组之间的信息能互通,不至于“各说各话”。
2、1×1 分组卷积 (Group Convolution)
📌 什么是 1×1 普通卷积?
- 在 CNN 里,1×1 卷积的作用主要是:
- 通道间信息混合(把不同通道组合起来,学新的特征)。
- 升维/降维(比如减少通道数,降低计算量)。
👉 形象化理解:
假设你有一张图有 128 个通道(像 128 种不同颜色的照片层)。
普通 1×1 卷积 = 所有工人(卷积核)同时看这 128 种颜色,一起计算,综合成新结果。
➡️ 很全面,但非常耗时。
📌 什么是 1×1 分组卷积 (Group Conv)?
- 把通道分组,每组只和自己内部的卷积核运算。
- 例如:128 个通道 → 分成 4 组,每组 32 个通道。
- 每个卷积核 只看自己这组的 32 个通道,不和别组交流。
👉 类比工厂:
- 普通 1×1 卷积:一个大车间,所有工人一起干活,效率低但结果全面。
- 分组卷积:把工人分成多个小车间,每个小车间只处理自己那部分任务, → 更快更省电,但小车间之间信息互不交流。
📌 为什么要用 Group Conv?
- 省计算量:
- 普通 1×1 Conv:输入通道数 × 输出通道数。
- Group Conv:= (输入通道 ÷ G) × (输出通道 ÷ G) × G → 计算量直接除以 G。
- 举例:128 in → 128 out
- 普通 Conv = 128×128 = 16384 次计算
- G=4 分组 = 32×32×4 = 4096 次计算 ➡️ 计算量减少 4 倍!
- 适合移动端:在手机/嵌入式设备上,可以显著加速推理。
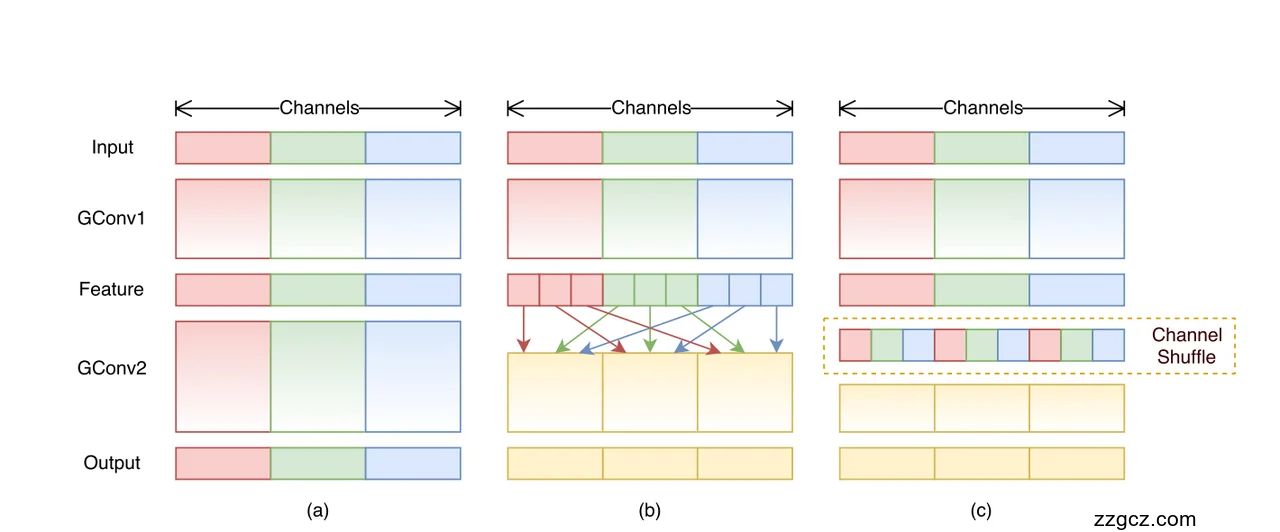
📌 (a) 普通的分组卷积 (Group Conv)
- 输入通道被分成了 3 组(红、绿、蓝块)。
- 在 GConv1 和 GConv2 里,每一组只和自己内部的通道做卷积。
- 结果:
- 节省了计算量 ✅
- 但每组之间完全独立,信息没法交流 ❌
👉 类比:就像工厂分了 3 个小车间(红/绿/蓝),每个小车间只处理自己的任务,效率高但彼此不沟通。
📌 (b) 直接把分组卷积结果堆起来
- 如果我们连续堆叠多个 Group Conv 层(比如 GConv1 → GConv2),
- 那么每个组还是只能接触自己那一组的特征。
- 结果:信息越来越“封闭”,不同组之间没学到协作,导致模型表达能力下降。
👉 类比:小车间干完一轮任务,下一轮还是原班人马继续干,一直在原地打转。
📌 (c) Channel Shuffle(通道洗牌)
- 为了解决“信息孤岛”,ShuffleNet 提出了 通道洗牌。
- 在分组卷积之后,把通道打散重排(像洗牌一样),然后再分组。
- 这样下一层的 Group Conv 就能跨组接触到不同的通道。
- 结果:既保留了分组卷积的高效性,又保证了信息流动。
👉 类比:工厂里的工人干完一轮活 → 老板让大家“换座位” → 下一轮每个小车间里的人都换了组合 → 信息可以交叉传递。
3、ShuffleNet v1 的网络结构
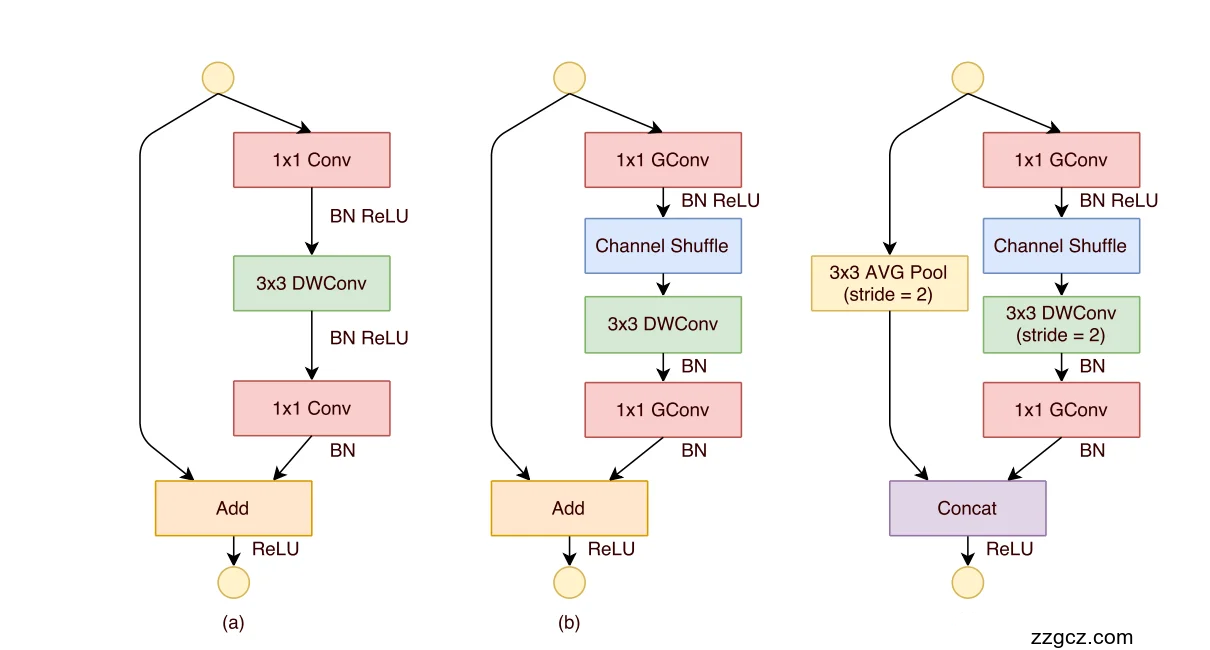
(a) 基础残差单元 (ResNet Bottleneck 风格)
- 结构:1×1 Conv → 3×3 DWConv → 1×1 Conv → 残差相加(Add)。
- 作用:
- 第一个 1×1 卷积:降维/压缩通道,减少后续计算量。
- 3×3 Depthwise Conv:逐通道卷积,主要处理空间特征,计算量小。
- 第二个 1×1 卷积:恢复通道数。
- 短路连接:输入与输出相加,形成残差结构。
👉 类比工厂:
输入零件 → 压缩成更少的零件类别 → 各类别自己加工(DWConv) → 再扩展回原大小 → 和原始零件“对比修正”后输出。
这就是 轻量级 ResNet 单元。
(b) ShuffleNet 改进单元 (stride=1)
- 变化点:
- 把 1×1 密集卷积 改成 1×1 分组卷积 (Group Conv) → 大幅降低计算量。
- 在第一个 1×1 Group Conv 之后加入 Channel Shuffle → 解决组间信息“互不交流”的问题。
- 3×3 DWConv 之后不加 ReLU → 避免信息丢失(实践发现这样更好)。
👉 类比工厂:
原来“所有工人(通道)一起干活 → 太累”。
于是改成“分组干活” → 省力,但不同小组间不交流。
所以要定期打乱分组 (Channel Shuffle) → 让信息充分交流。
最后继续逐通道加工(DWConv),再恢复通道数。
这就是 ShuffleNet 的核心创新点。
(c) ShuffleNet 下采样单元 (stride=2)
- 输入主分支:1×1 Group Conv → Channel Shuffle → 3×3 DWConv(stride=2) → 1×1 Group Conv。
- 旁路分支:3×3 AvgPool (stride=2)。
- 输出方式:两个分支结果用 Concat 拼接(不是相加)。
👉 为什么要 Concat 而不是 Add?
- 下采样后通道数需要翻倍,而相加会丢掉一半信息。
- Concat 可以 保留更多信息,同时几乎不增加额外计算量。
👉 类比工厂:
想要“减少产线长度(下采样)” →
主工厂通道:继续复杂工艺但降低分辨率;
副工厂通道:用 平均池化快速缩小尺寸;
最后把两路产出 直接合并 (concat),产能翻倍且更高效。
4、ShuffleNet v1 的最致命的缺点
🚨 最致命的缺点:分组卷积导致的信息流受限,即使有 Channel Shuffle 也无法完全解决
- 核心问题: ShuffleNet v1 的设计是用 分组卷积 (Group Conv) 来减少计算量,但分组卷积天然会让不同通道“各自为战”,信息只在小组内流动。 为了解决这个问题,作者引入了 Channel Shuffle,让不同组的特征通道交换一下。 然而,通道交换的效果有限,并不能像全连接卷积那样实现完全自由的信息交互。
- 影响:
- 在小模型(低 FLOPs)下,特征表达能力不足,精度掉得更快。
- 在大模型(高 FLOPs)下,Channel Shuffle 的优势减弱,甚至比不过 MobileNet V2。
- 在硬件部署时,shuffle 操作带来额外的内存读写开销,反而可能拖慢速度。
👉 类比:
就好比工厂里为了省成本,把工人分成小组,每个组只负责自己的一部分。虽然偶尔会“换工位”让大家交流,但交流频率不高,效率依旧受限。这样虽然省了钱,但产出的产品种类和质量受影响。
✅ 一句话总结:
ShuffleNet v1 最致命的缺点是 分组卷积严重限制了信息流通,而 Channel Shuffle 只是“补丁”,无法彻底解决问题,这也是后来 ShuffleNet v2 改进的重点方向。