ShuffleNet v2(2018):高效CNN架构设计的实用指南,改进轻量化结构
导出时间:2025/11/23 20:22:39
1、 研究背景和动机
(1)从 ShuffleNet v1 出发
- ShuffleNet v1 的亮点在于:
- 使用 分组卷积(Group Convolution) 来降低计算量。
- 再通过 Channel Shuffle(通道洗牌)来保证不同组之间的信息交流。
- 这让模型在移动端(手机、嵌入式设备)上变得更轻、更快。
- 但实践中发现:即便 FLOPs(理论计算量)大幅下降,实际运行速度并没有按预期快。
👉 就像工厂老板在账面上看到“工作量减少了 50%”,但工人们搬货、沟通、排队的时间并没有减少多少,工厂还是慢吞吞的。
(2)实际问题:FLOPs ≠ 实际速度
研究人员发现,FLOPs(浮点运算次数)只是理想的理论指标,但在真实硬件(CPU、GPU、手机芯片)中,速度还受到以下因素影响:
- 内存访问成本(MAC,Memory Access Cost)
- 计算可能很快,但“搬数据”非常耗时。
- 就像工人机器效率高,但材料堆得远,来回搬运耗掉了大部分时间。
- 并行度限制
- 分组卷积虽然减少了计算量,但限制了硬件并行优化。
- 就像把工人分成很多小组,每组只管自己的一点任务,结果流水线效率不高。
- 算子操作数量
- 网络里操作过于碎片化(太多小操作),调度和切换开销变大。
- 就像流水线上工人太多工序,来回切换、对接比实际生产更耗时。
(3)ShuffleNet v2 的动机
ShuffleNet v2 的目标是解决“理论 FLOPs 很低,但实际速度并不快”的矛盾,让网络在真实硬件里真正做到“又轻又快”。
2、 创新点
(1)提出 高效网络设计的四条黄金准则
这是 ShuffleNet v2 最大的贡献,四条黄金准则(通道均衡 / 少碎片 / 少元素级操作 / 降内存访问)
- 同等通道分配更高效
- 如果输入和输出通道数差太多,内存搬运成本会变高。
- 👉 就像流水线前面 10 个工人,后面只留 2 个工人,前面产能爆棚,后面却堵住了。
- 因此建议保持输入输出通道数接近。
- 减少碎片化操作
- 太多小操作(小卷积、小分组)导致硬件调度复杂。
- 👉 就像工厂里工序太零散,工人们一直在“交接”,反而效率低。
- 元素级操作也有开销
- 像逐元素加法、通道拼接,看似简单,但在硬件上也要花时间。
- 👉 就像流水线上不停地“零件对齐、拧螺丝”,小事堆起来就是大开销。
- 内存访问成本要最小化
- 读写数据很慢,尽量减少搬运次数。
- 👉 就像工厂里搬运工太忙,运输反而成了最大瓶颈。
(2)提出 Channel Split + Shuffle 单元
ShuffleNet v2 在 ShuffleNet v1 的基础上,进一步改进了基本单元:
- 通道分裂 (Channel Split)
- 把输入特征分成两路:一路走轻量化卷积,另一路直接跳过(identity shortcut)。
- 👉 就像工厂里一半原料直接走“快速通道”,另一半进入机器加工,这样省时省力。
- 减少 1×1 分组卷积
- v1 用大量 group conv,导致并行受限。
- v2 改为普通 1×1 卷积 + 分裂机制,速度更快。
- 👉 就像工厂老板发现“把工人硬分组”反而效率低,于是直接让部分工人自由协作。
- Channel Shuffle(通道洗牌)
- 在卷积之后,把不同通道重新混合,保证信息互相交流。
- 👉 就像工厂里不同车间的产品需要重新分类、打乱,避免“一直在小圈子里内循环”。
✅ 一句话总结创新点: ShuffleNet v2 的创新点在于提出了高效网络设计的四条准则,并用 Channel Split + Channel Shuffle 构建了极简而高效的单元,解决了 v1 理论 FLOPs 小但实际速度不快的问题。
3、Shuffle 单元
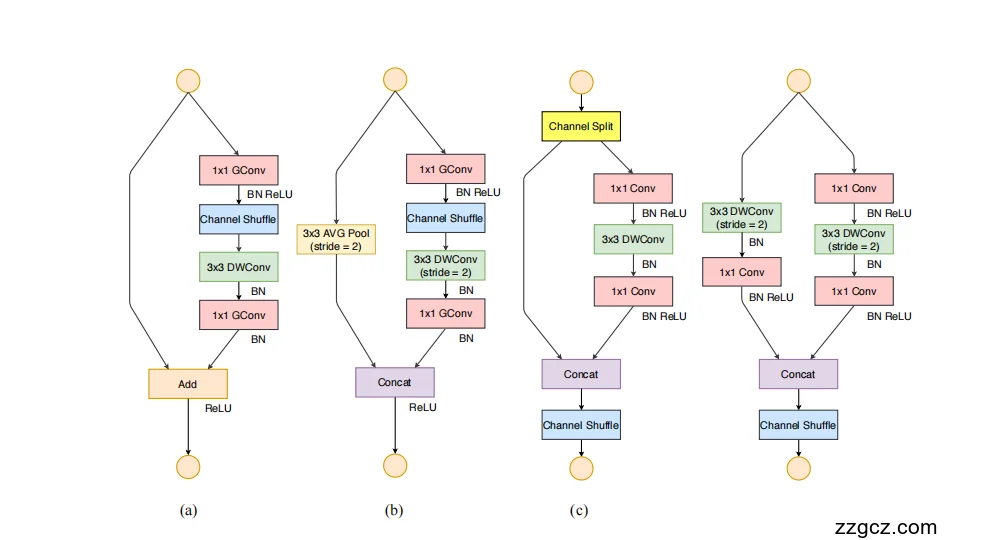
(a) v1:Shuffle 单元(stride = 1)
主支路
- 1×1 GConv(分组 1×1 卷积)→ BN + ReLU
- 目的:1×1 卷积最耗时,用“分组”来削减计算量。
- Channel Shuffle
- 目的:分组后各组“互不来往”,洗牌把通道打乱重分组,保证跨组信息流动。
- 3×3 DWConv(逐通道卷积,stride=1)→ BN
- 目的:低成本提取空间信息。
- 1×1 GConv(分组 1×1)→ BN
- 目的:融合通道、恢复维度。
捷径支路:恒等映射(什么都不做)。
融合:两路 Add 相加 → ReLU。
要点:v1 依赖“分组 1×1 + 洗牌”来降算力,但元素级 Add 本身也要花时间,且分组会限制并行度。
(b) v1:下采样单元(stride = 2)
主支路
- 与 (a) 类似,但 3×3 DWConv 用 stride=2 做下采样,输出分辨率减半。
旁路
- 3×3 AvgPool(stride=2) 直接把输入下采样。
融合:两路 Concat 拼接 → ReLU。
为什么不相加而是拼接? 下采样后通道数需要扩,拼接能“扩通道 + 保信息”,且比相加更省开销。
(c) v2:Shuffle 单元(stride = 1)
这是 v2 的核心改造——Channel Split + 普通 1×1(不再用分组 1×1)。
顶层操作:Channel Split(通道分裂)
- 把输入通道 一分为二:
- 分支 A(直通道):Identity,不做卷积,零开销;保证信息与梯度的“高速通道”。
- 分支 B(加工道):
- 1×1 Conv → BN + ReLU(注意:不分组,并行友好)
- 3×3 DWConv(stride=1) → BN(DWConv 后不再堆 ReLU,减少元素级操作)
- 1×1 Conv → BN + ReLU
融合:把 A、B Concat 拼接 → Channel Shuffle(放在单元末尾执行一次)。
为什么这样更快?
- 一半通道直通,少算一半 1×1,MAC 也少一半;
- 普通 1×1 比“分组 1×1”更符合硬件并行;
- 只洗牌一次,减少碎片化与数据搬运;
- 不做 Add,避开元素级相加的内存读写成本。 这正贯彻了 v2 的四条黄金准则(通道均衡 / 少碎片 / 少元素级操作 / 降内存访问)。
(d) v2:下采样单元(stride = 2)
下采样时不能再“直通”,于是 v2 用 两条对称的卷积分支(都降分辨率),最后再拼起来:
分支 A
- 1×1 Conv → BN + ReLU
- 3×3 DWConv(stride=2) → BN
- 1×1 Conv → BN + ReLU
分支 B
- 3×3 DWConv(stride=2) → BN
- 1×1 Conv → BN + ReLU
融合:两路 Concat 拼接 → Channel Shuffle。
为什么这么设计?
- 两个分支都做 stride=2,尺寸一致、通道均衡,硬件更好并行;
- 全程 不使用分组 1×1,减少并行受限;
- 拼接而非相加,继续避免元素级操作的额外开销;
- 末尾再 一次洗牌,保证两路信息充分混合。
4、模型网络结构
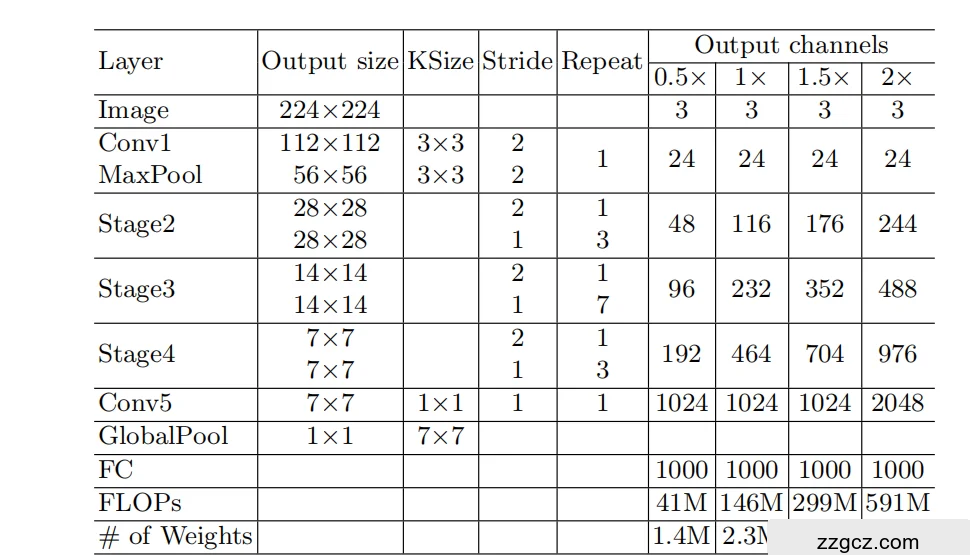
ShuffleNet v2 的网络可以分为三大部分:
① 输入阶段(Stem 部分)
- 用一个 3×3 卷积(stride=2) 把输入图像缩小一半。
- 接一个 最大池化(max pooling, stride=2),进一步缩小。
- 👉 类比:像工厂原料进厂前,先粗加工(卷积),再过一次分拣机器(池化),把原料体积缩小,便于后续流水线处理。
② 主体阶段(Stage 2、3、4)
这是 ShuffleNet v2 的核心,由 多个 Shuffle 单元(Shuffle Unit) 堆叠而成:
a. 普通 Shuffle 单元(stride=1)
- 输入通道先分成两部分(channel split):
- 一半走“快捷通道”(identity shortcut,啥也不做)。
- 另一半走“加工通道”:
- 1×1 卷积(Pointwise conv,降低/调整通道数)
- 3×3 depthwise 卷积(DWConv,低成本空间特征提取)
- 1×1 卷积(Pointwise conv,再融合特征)
- 最后把两部分合并。
- Channel Shuffle(通道洗牌):把通道打乱重排,让不同组之间的信息互相交流。
- 👉 类比:一半工人直接“直通车”到终点,另一半工人进机器加工。最后把两拨工人重新混合分组,避免一直在老伙伴圈子里。
b. 下采样 Shuffle 单元(stride=2)
- 这里的目标是 缩小特征图的空间分辨率,同时保持信息流动。
- 设计上有两路:
- 左路:
- 3×3 depthwise 卷积(stride=2,缩小空间大小)
- 1×1 卷积(调整通道数)
- 右路:
- 直接用 3×3 平均池化(stride=2),不做卷积。
- 左路:
- 最后把两路 拼接(concat) 在一起。
- 👉 类比:流水线需要“缩减产能”,一部分原料进机器精加工(DWConv),另一部分直接走“旁路平均压缩机”,最后再合并成一条线。
③ 输出阶段(尾部)
- 最后用 1×1 卷积 把通道数扩展到目标大小。
- 再用 全局平均池化(global average pooling) 把空间特征汇总成一个向量。
- 接 全连接层(FC),输出分类结果。
- 👉 类比:所有流水线出来的产品,最后放进“总仓库”(池化),再经过一次总检(FC),决定属于哪个类别(分类标签)。
🔑 总结(网络设计思路)
- 开头: 缩小图片 → 减少计算压力。
- 中间: 堆叠 Shuffle 单元 → 高效提取特征。
- 下采样单元: 控制分辨率下降的同时,保持信息流。
- 结尾: 全局汇总 → 分类。
5、ShuffleNet v2 的致命缺陷
最大问题:空间信息表达不足
ShuffleNet v2 设计得极度轻量、高速,但它的结构有个很明显短板:
几乎只关注“通道的流动/拼接/混合”,但在提取空间特征时依然依赖标准的 DWConv。
为什么这是致命的?
- 深度可分离卷积(DWConv)虽然计算量少,但它看每个通道只能“看自己一个像素点的邻居”,对跨通道整体空间结构依赖弱。
- 简单来说就是说:ShuffleNet v2 在“哪里有特征”很弱,尤其是对于图像中的复杂结构(比如弯曲边缘、细长形状、小目标)它捕捉能力差。
形象比喻
想象有一个工厂流水线上的视觉检测系统,负责检查产品(图像)上的瑕疵:
- 系统分成多个相机通道,每个只关注自己的一小块产品。
- 通道之间有“分裂→拼接→打乱”的结构,信息交流很好,但每个相机只拍自己的一小块。
- 如果瑕疵在多个区域联合出现(如小指尖纹理、缝隙),系统可能根本看不到。
- 也就是说“看局部很行,看全局结构弱” 是它致命的短板。
6、未来发展方向
- 加入空间注意力机制
- CBAM、CoordAtt(坐标注意力) 等模块能补空间建模能力,为每个通道“指出该关注哪里”。
- 未来方向:在 ShuffleNet v2 基础上,融合空间注意力,让模型既能通道混合,也能关注有效区域。
- 引入更大的卷积封闭结构
- 嵌入 扩张卷积(dilated conv) 或 局部多尺度卷积,增强单通道内的空间感受力。
- 未来方向:在 Shuffle 单元里加入简单多尺度卷积模块,让每个通道“稍微看得远一点”。
- 自动结构搜索(NAS)
- 使用 基于硬件速度的 NAS(如 FBNet、ProxylessNAS) 自动探索能够提升空间特征的轻量结构。
- 未来方向:ShuffleNet v2 基础上让 NAS 搜索出能兼顾空间表达和速度的模块。
- 跨通道空间协同
- 在拼接后加入 通道间偏移、融合卷积(如 GhostNet 局部通道整合策略)来缓解空间信息分散的问题。
- 未来方向:改进拼接后的融合策略,让混合的特征能有更强空间建模能力。
模型名称
| 改进方向
| 说明
|
GhostNet
| 引入 Ghost 模块(通道内生成 redundant 特征)
| 在 ShuffleNet v2 基础上加强通道融合与空间感受力
|
FBNet / ProxylessNAS
| 基于 v2 结构进行硬件意识的自动结构优化
| 更适配移动硬件的空间+通道混合结构
|
ShuffleNASNet
| 用 NAS 重新搜索 Shuffle 单元结构
| 自动探索空间特征表达更好且快速的轻网络
|
ShuffleNet + CoordAtt / CBAM
| 插入空间注意力模块
| 让模型在拼接通道前后增强对“在哪”有敏感度
|