SqueezeNet(2016):在参数数量减少50倍、模型大小不到0.5MB的情况下,达到与AlexNet相当的精度
导出时间:2025/11/23 20:21:24
1、研究背景和动机
(1)背景:深度学习模型越来越“大”
- 在 AlexNet、VGG、GoogLeNet 之后,深度卷积神经网络(CNN)在图像分类上性能越来越强,但同时 模型参数量急剧膨胀。
- VGG-16 参数量高达 138M,存储需要 500MB+。
- 这对计算资源有限的设备(如手机、嵌入式设备、无人机)来说,几乎不可用。
(2)现实需求:小而强的模型
- 随着深度学习走向 移动端和物联网(IoT),迫切需要:
- 更小的模型(存储占用少,便于部署和传输);
- 计算更快(适合低功耗设备的实时推理);
- 精度不下降(在 ImageNet 等大规模任务上保持接近 AlexNet/VGG 的准确率)。
(3)动机:设计一个“小体积但高精度”的模型
- 论文作者的目标是:
- 在 ImageNet 分类任务 上,达到 与 AlexNet 相同的准确率;
- 但模型体积 小 50 倍以上,参数显著减少;
- 让模型可以轻松部署在嵌入式设备、移动端,甚至通过网络快速传输。
2、SqueezeNet 的创新点
SqueezeNet 的目标是 极大减少参数量,同时保持 AlexNet 级别的精度。它的核心设计理念有三个。
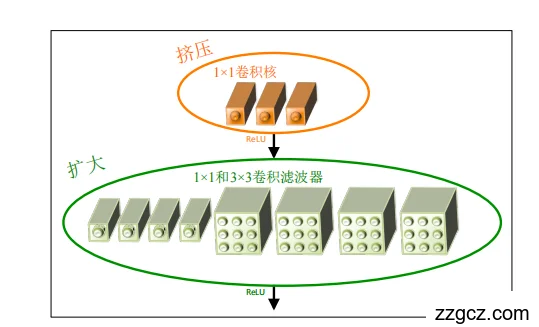
(1)Fire 模块:Squeeze + Expand
- 结构设计:
- Squeeze(压缩层):用 1×1 卷积 代替一部分传统的大卷积,减少输入通道数。
- Expand(扩展层):再用 1×1 + 3×3 卷积 混合生成输出特征。
- 效果:
- 大量减少参数量(因为 1×1 卷积计算量远小于 3×3)。
- 保证特征表达能力不下降。
👉 比喻:
就像“先把水管收窄(Squeeze),减少水量,再分流成多个小管(Expand),扩展出不同方向的水流”。
(2)减少 3×3 卷积核的使用
- 在传统 CNN(如 VGG)中,3×3 卷积核数量很多,计算量和参数量都很大。
- SqueezeNet 的做法:
- 尽可能用 1×1 卷积 替代 3×3;
- 即使用 3×3 卷积时,也减少其数量。
- 效果:大幅降低模型参数。
(3)延后下采样(Late Downsampling)
- 传统 CNN(如 AlexNet)在前几层就会用池化层大幅缩小特征图尺寸。
- SqueezeNet 选择 把下采样推迟到网络更深的层:
- 在前期保留更大、更细致的特征图;
- 有助于后续卷积提取更多细节特征,提高准确率。
👉 比喻:
就像拍照时,先保留高清原图,后面再缩小,而不是一开始就压缩成小图。
3、SqueezeNet 的网络结构
SqueezeNet 的核心是 Fire 模块,整个网络就是由 卷积层 + Fire 模块 + 池化层 组合而成。
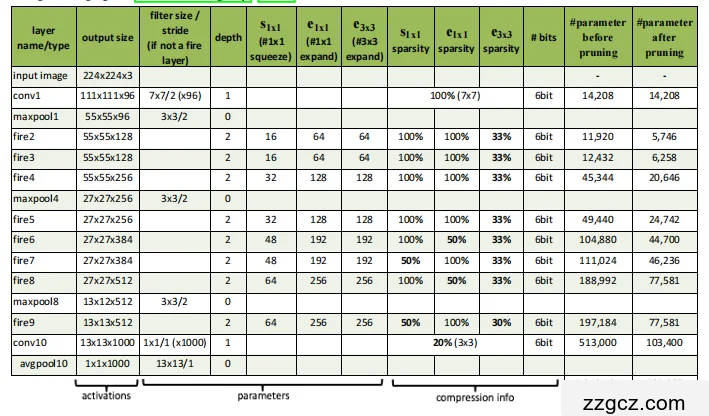
(1)输入层
- 输入:224 × 224 × 3 的彩色图像(与 AlexNet 相同)。
(2)初始卷积层(Conv1)
- 一个 7×7 卷积层,步幅 2,输出 96 个通道。
- 后接 最大池化层 (MaxPool),步幅 2。
- 作用:快速缩小特征图尺寸,提取初步特征。
(3)Fire 模块堆叠
Fire 模块是 Squeeze(压缩)+ Expand(扩展) 的组合:
- Squeeze 层:1×1 卷积 → 压缩通道数。
- Expand 层:同时使用 1×1 和 3×3 卷积,再拼接输出。
👉 Fire 模块的设计目标:减少参数,同时保持特征丰富性。
网络中一共堆叠了 8 个 Fire 模块:
- Fire2, Fire3
- Fire4 + 最大池化
- Fire5, Fire6, Fire7
- Fire8, Fire9
(4)卷积与输出层
- 在 Fire9 之后,加一个 卷积层(Conv10),输出与类别数一致(ImageNet 是 1000 类 → Conv10 有 1000 个通道)。
- 使用 全局平均池化 (Global Average Pooling) 代替全连接层。
- 最后接 Softmax 进行分类。
(5)下采样策略
- SqueezeNet 的关键点:延后下采样。
- 最大池化只在 Conv1 后、Fire4 后和 Fire8 后进行。
- 这样保证大部分中间层的特征图更大,更容易提取细节特征。
4、SqueezeNet 的模型缺点
(1)计算速度不一定最优
- 参数量小 ≠ 一定推理更快。
- 原因:
- 大量使用 1×1 卷积,虽然参数少,但在实际硬件(尤其是 GPU/嵌入式设备)上,1×1 卷积的内存访问开销较大。
- 在某些平台上,SqueezeNet 的速度并不一定比 ResNet-18 更快。
👉 换句话说:它更像是“存储友好”而非“运算极快”。
(2)模型设计缺乏灵活性
- Fire 模块的结构固定:Squeeze → Expand(1×1 + 3×3)。
- 灵活性和扩展性不如 ResNet(残差单元可以无限堆叠)、DenseNet(层间密集连接)。
- 这使得它在迁移学习或扩展到更复杂任务(检测、分割)时,表现不如主流网络灵活。
5、基于 SqueezeNet 的后续改进模型
SqueezeNet 的核心贡献是提出了 Fire 模块 和 极小参数量的 CNN 设计思想。在它的基础上,后续研究提出了一系列改进模型,主要目标是:进一步加快速度、提升精度、增强在移动端/嵌入式设备上的适用性。
(1)SqueezeNext(2018)
- 核心思想:在 Fire 模块基础上,进一步优化网络拓扑。
- 改进点:
- 使用更细粒度的卷积分解(类似 Inception 的因子分解)。
- 改善残差连接,提升训练稳定性。
- 更强的正则化手段。
- 效果:
- 更快(适配 ARM CPU/GPU),在移动端比 SqueezeNet 更实用。
- 精度也有提升。
(2)ShuffleNet(2017, 由 SqueezeNet 启发)
- 灵感来源:SqueezeNet 强调 轻量化卷积核设计。
- 创新点:
- 使用 Group Convolution + Channel Shuffle,在降低计算量的同时保持信息流动。
- 可以看作是 SqueezeNet 思路的“进化版”。
- 效果:在移动端设备上显著优于 SqueezeNet。
(3)MobileNet 系列(2017 起)
- 关系:虽然不是直接“Fire 模块”的改进,但 与 SqueezeNet 一样追求轻量化。
- 创新点:
- Depthwise Separable Convolution(深度可分离卷积)。
- 与 Fire 模块有相似的设计理念:减少计算量 + 保持特征表达能力。
- 效果:MobileNet 成为轻量级 CNN 的主流,逐渐取代了 SqueezeNet。
(4)Tiny-YOLO / MobileNet-SSD 等轻量检测网络
- 在目标检测中,SqueezeNet 的 小参数量 特性被用于 YOLO、SSD 等模型的轻量化变种。
- 这些模型通过在骨干网络中替换为 SqueezeNet,达成 低存储、低延迟 的目标。