VGGNet(2014):用于大规模图像识别的非常深的卷积网络
导出时间:2025/11/23 20:19:10
1、研究背景和动机
在 VGG 出现之前,图像识别就像“盲人摸象”:
- 计算机看一张图,只能凭感觉抓几个零散的“特征点”,
- 结果忽好忽坏,时灵时不灵。
大家发现,如果把“看图的流程”做得更深、更系统,准确率就能蹭蹭往上涨。于是“深一点的网络”成了当时的香饽饽,但问题是:
- 怎么深?
- 深了会不会崩?
牛津大学的 VGG 团队(Visual Geometry Group)站出来说:
“我们不想玩花活,就想回答一个朴素的问题——
如果每一层都用最简单、最统一的小积木,一直往上摞,会发生什么?”
他们把“小积木”定成:
- 统一大小(3×3)
- 统一步长(一步一格)
- 统一“粘合剂”(池化层)
就像只用一种形状的乐高方块,却硬要搭出摩天大楼。
他们想证明:
“简单 + 深度” 可能比 “复杂 + 浅层” 更给力。
2、VGG16 的创新点
- 深层网络结构(楼层更高的“特征大楼”)
- 可以把神经网络想象成一栋大楼,每一层都在提取不同层次的图像特征。
- AlexNet 就像一栋 8 层的楼,大体能看到物体的形状。
- VGG16 把楼层加高到了 16 层,每一层都更细致地加工特征,能看出更复杂、更抽象的细节。
- 小卷积核堆叠(小放大镜的组合)
- 卷积核可以理解为“放大镜”,它帮我们观察图像中的局部细节。
- 以前的模型用的是“大放大镜”(7×7 或 11×11),一次看得很多,但细节容易模糊。
- VGG16 改用多个“小放大镜”(3×3),通过连续叠加,不仅能看得一样大(保持相同的视野范围),还看得更清楚(细节更多,参数更少)。
- 统一简洁的网络设计(积木搭建思路)
- VGG16 的网络像一组“积木”,全都用 3×3 卷积和 2×2 池化堆叠而成。
- 这种统一的结构让模型像 乐高积木一样,简单、好拼,也方便别人搭建和扩展。
3、模型的网络结构
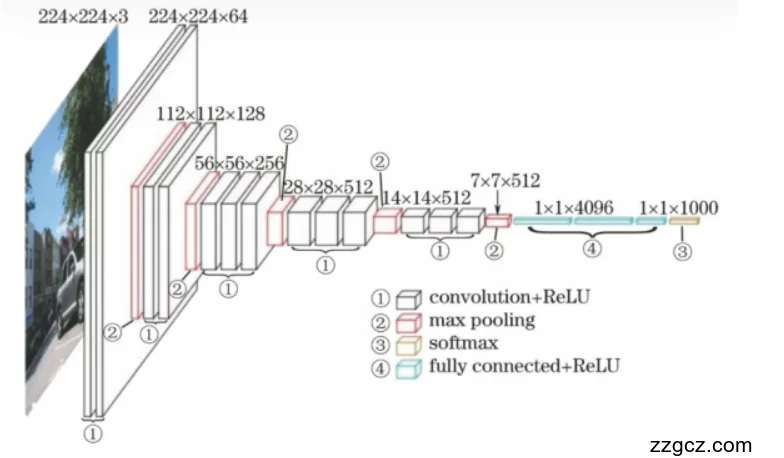
VGG16 网络结构说明
输入图像大小:224×224×3(三通道彩色图像)
- 卷积层 + ReLU 激活函数
- 使用多个 3×3 卷积核,步长为 1,填充为 1,保证图像尺寸不变。
- 每经过卷积层,通道数(深度)逐渐增加:64 → 128 → 256 → 512。
- 这些层主要负责提取图像中的局部特征,如边缘、纹理、形状等。
- 最大池化层(Max Pooling)
- 使用 2×2 的池化核,步长为 2,将特征图尺寸减半。
- 特征图的空间分辨率逐步缩小:224×224 → 112×112 → 56×56 → 28×28 → 14×14 → 7×7。
- 起到压缩数据量、保留主要特征的作用。
- 全连接层(Fully Connected + ReLU)
- 在最后的卷积输出(7×7×512)被展平成向量后,输入到三层全连接网络:
- 第一层:4096 个神经元
- 第二层:4096 个神经元
- 第三层:1000 个神经元(对应 ImageNet 的 1000 个分类类别)
- 在最后的卷积输出(7×7×512)被展平成向量后,输入到三层全连接网络:
- Softmax 分类器
- 输出每个类别的概率,取最大值对应的类别作为最终预测结果。
VGG16 层级结构一览(16 层带权重层)
- 卷积层(13 层):3×3 卷积核堆叠
- 全连接层(3 层):4096、4096、1000
- 总层数 = 16(所以称为 VGG16)
4、模型❌ 缺点
- 参数量大、存储开销高
- 模型参数约 1.38 亿,需要超过 500MB 的存储空间。
- 部署在计算资源有限的环境(如移动端、嵌入式设备)非常困难。
- 类比:就像一辆“豪车”,性能好但“油耗高”。
- 计算量大、训练耗时
- 每次前向和反向传播的计算量都很大,对 GPU/TPU 要求高。
- 训练 VGG16 需要几周时间(在早期硬件条件下),限制了快速实验和迭代。
- 梯度消失/爆炸风险
- 虽然深度增加提升了性能,但 16 层仍然可能面临梯度消失或爆炸的问题。
- 这也是后续 ResNet 引入“残差连接”来解决的关键原因。
- 性能提升有限
- 在 ImageNet 上,VGG16 的性能比 AlexNet 提升明显,但与后续的 ResNet、Inception 等相比,参数冗余且效率不高。
- 用大量参数堆出来的性能,并不是最优解。
5、基于 VGG 的改进模型
更深、更高效的网络结构
VGG16 的成功验证了“深度带来性能提升”的结论,但其庞大的参数量和计算开销限制了应用范围。未来的研究将继续探索更深层网络(如 ResNet、DenseNet),并通过结构创新来提升训练效率与模型性能。
- VGG19 —— 更深的结构探索
- 改进点:在 VGG16 的基础上增加了 3 层卷积,网络深度扩展到 19 层。
- 目标:验证进一步加深网络是否能继续提升性能。
- 效果:在 ImageNet 上精度略有提升,但代价是训练和推理更慢,参数量更大。
- 启示:单纯加深并不能解决效率和参数冗余问题,改进思路需要转向结构优化。
- Fast-VGG / VGG-Fast(轻量化改进)
- 改进点:在保持 VGG 结构的前提下,减少卷积层的通道数,降低全连接层规模。
- 目标:减少模型大小,加快训练与推理速度,便于在资源有限的环境中应用。
- 效果:在部分小规模数据集(如 CIFAR-10、CIFAR-100)上,仍能保持较高精度,但推理速度更快。
- 启示:轻量化是 VGG 的重要发展方向之一。
- VGG-SSD(Single Shot Multibox Detector, 2016)
- 改进点:将 VGG16 作为 骨干网络(backbone),在其卷积特征图上直接加入检测框预测层,实现 端到端的目标检测。
- 目标:提升目标检测的速度和准确性。
- 效果:VGG-SSD 在检测精度和实时性上取得了平衡,广泛应用于实际场景。
- 启示:VGG 提取的特征具有良好的泛化性,适合扩展到分类以外的任务。
- VGG-FCN(Fully Convolutional Network, 2015)
- 改进点:将 VGG16 的全连接层改为卷积层,得到全卷积网络(FCN)。
- 目标:用于 语义分割,实现像素级预测。
- 效果:在 PASCAL VOC 等分割任务上表现优异,成为语义分割领域的重要基线模型。
- 启示:VGG 的结构简洁性,使其成为多任务研究(检测、分割)的首选骨干。
- VGG-M / VGG-S(结构变体)
- 改进点:在 VGG 框架下尝试不同的层数、卷积核大小和步长配置。
- 目标:寻找在速度与精度之间更好的折中。
- 效果:部分变体在小数据集上速度更快,但在大规模数据集上性能不如 VGG16/19。
- 启示:VGG 框架可扩展性强,适合衍生出多种结构变体。