Vision Transformer (2021):一张图像胜过16×16个词:大规模图像识别的Transformer模型,Transformer首次引入视觉
导出时间:2025/11/23 20:23:46
1、研究背景和动机
在计算机视觉(CV)的发展中,卷积神经网络(CNN)一直是主角。自 AlexNet (2012) 横扫 ImageNet 开始,到 ResNet、DenseNet、EfficientNet,CNN 的改进几乎支撑了过去十年的视觉任务(分类、检测、分割等)。
🔹 Transformer 崛起与融合探索(2020–2021)
- 在自然语言处理(NLP)领域,Transformer(2017,Attention is All You Need) 完全颠覆了传统 RNN/LSTM。
- Transformer 的核心是 自注意力机制(Self-Attention),可以直接建模任意两个词之间的关系。
- 这种“看全局”的能力,让 BERT、GPT 系列在 NLP 中大获成功。
👉 于是研究者开始思考:
“既然文字可以用 Transformer,那图像能不能也用 Transformer?”
🔹ViT 的提出(2020)
- 谷歌研究院提出 Vision Transformer (ViT),第一次把 Transformer 结构原封不动地搬到图像分类任务中。
- 关键想法是:
- 把图片切成小块(patch),就像把图像当作“句子”;
- 每个小块就像“词语”;
- 用 Transformer 去建模小块之间的全局关系。
🔹 动机总结(通俗类比)
可以这样形象理解:
- CNN 就像“显微镜工人”,拿着放大镜一点点扫描图片,逐步组合成整体。
- ViT 就像“上帝视角”,直接把图片拆成拼图块,然后一眼就能捕捉所有拼图块之间的关系。
2、Vision Transformer (ViT) 的创新点
ViT 的最大贡献就是——把图像看作一句话,用 NLP 的 Transformer 来处理图像。这看起来很大胆,但效果惊人。下面分几个点来说:
(1) 图像 → 图像块(Patch) → 类似“词”
- 传统 CNN:一张图片会被卷积核滑动提取局部特征。
- ViT:直接把图片切成一块一块的小方格(比如 16×16 像素),然后把每一块拉平成一个向量,就像一句话里的一个“单词”。
- 这样,一张图就变成了由很多“词”组成的句子,Transformer 就能直接处理。
(2) 自注意力(Self-Attention)全局建模
- CNN 的卷积核是“看局部”的,要一层层叠加才能捕捉全局信息。
- ViT 通过自注意力机制,可以让每个图像块直接和所有其他块建立联系,一步就能看到全局。
就像开会时,CNN 是“逐级汇报”,每个人只能和临近的人交流;ViT 是“全员群聊”,所有人能即时沟通。
(3) 分类标记 (CLS Token)
- 在 NLP 的 BERT 里,有一个特别的
[CLS]标记用来代表整句话的含义。 - ViT 借鉴了这个方法,专门加了一个“分类 token”,经过所有 Transformer 层后,这个 token 就代表整张图片的语义,用来做分类。
👉 形象理解:
就像开会时,虽然大家都在说话(图像块),最后有一个“秘书”(CLS token)把所有人的意见整理,输出结论(猫 / 狗 / 车)。
(4) 弱归纳偏置,强依赖大数据
- CNN 天生有“归纳偏置”,比如卷积天然就擅长捕捉局部相邻像素的关系。
- ViT 完全放弃了这些人为设计的先验知识,几乎不假设图像的结构,全靠数据学。
- 这意味着在小数据集上,ViT 不如 CNN,但在大规模数据(比如 JFT-300M)上,它能学出更强大的模式,甚至超过 CNN。
👉 形象理解:
CNN 像是“有经验的老教师”,一开始就会用一些固定套路;ViT 像是“白纸的新生”,啥都不会,但只要见识足够多,就能学出比老师更灵活的思维。
(5) 简单可扩展
- ViT 的结构非常干净:图像块嵌入 + Transformer 编码器 + 分类头。几乎没什么花哨的模块。
- 好处是:NLP 里成熟的 Transformer 优化、加速技巧可以直接拿来用。
- 扩展也很方便:只要增加层数或隐藏维度,就能从 ViT-Base → ViT-Large → ViT-Huge,不需要重新设计复杂的卷积结构。
3、 基于图解的 ViT 网络结构讲解
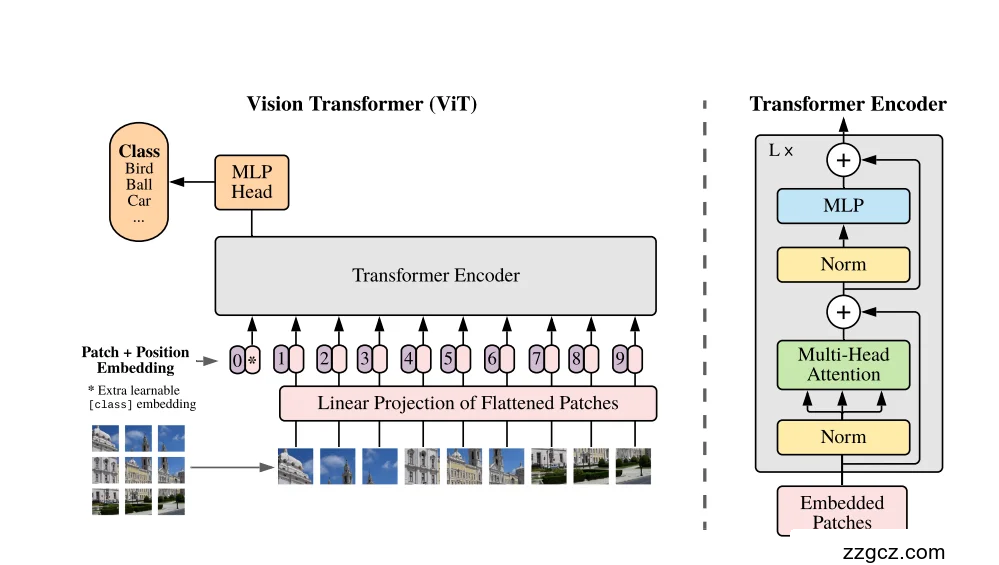
- 图像切块 → Patch + Position Embedding
- 左下角:输入一张图片(比如一栋建筑)。
- 把它切成很多 小方块(patch),每个小块就是模型的输入单元。
- 然后每个小块被“展开(flatten)”,经过线性变换投影到固定维度。
- 最后还要加上 位置编码(Position Embedding),告诉模型“这个小块在图片的哪里”。
👉 类比:把整张图片变成拼图小块,还在每个小块背面写上编号(位置标签)。
- 加入 [CLS] Token(图中的 0)*
- 在所有 patch 前面,插入一个特殊的
[CLS]向量。 - 经过整个 Transformer 处理后,这个 token 会变成“全图的摘要”。
👉 类比:像开会请了一个秘书(CLS),他从头到尾听所有人的发言,最后写总结报告。
- Transformer Encoder(中间大方块)
右边的框细化了 Encoder 内部,它由 L 层重复堆叠,每层有两部分:
- Multi-Head Attention(多头自注意力)
- 每个小块可以和所有其他小块交流,建立全局联系。
- 多头机制 = 不同的“注意力通道”,能从不同角度去看关系。 👉 类比:所有拼图块都进入群聊,每个人都能和所有人沟通。
- MLP(前馈全连接层)
- 在每次群聊之后,每个小块再单独进行一次“思考”。
- 帮助提升特征表达能力。 👉 类比:大家群聊后,各自做笔记,思考更深入。
⚙️ 这两步之间还有 Norm(规范化)和残差连接,保证训练稳定。
- 分类头 MLP Head(图上方)
- 最后,模型只取
[CLS]这个“秘书 token”,送到一个 MLP 分类头。 - 输出结果是具体的类别,比如“鸟 / 球 / 汽车 / 建筑”。
👉 类比:会议结束后,由秘书(CLS)写总结,交给老板(分类器),老板给出最终结论。
4、ViT 的致命缺陷
(1) 训练需要极其庞大的数据
- ViT 几乎没有利用 CNN 的“先验知识”(比如卷积的局部平移不变性)。
- 这意味着 ViT 在小数据集上很容易 过拟合,表现比不上 ResNet。
- 在论文中,ViT 只有在 JFT-300M 这种上亿级别数据 上训练,才真正超过 CNN。
👉 类比:
CNN 就像是“有经验的老老师”,即便学生只有 100 个人,他也能快速总结规律;
ViT 像是“白纸新生”,啥都要靠自己学,结果需要 100 万学生才能学会一样的东西。
(2) 计算和存储开销大
- 自注意力机制需要计算每个 patch 与所有其他 patch 的关系,复杂度是 O(N²)(N = patch 数量)。
- 当输入图片更大、patch 更多时,显存和计算量会急剧上升。
- 这让 ViT 在高分辨率任务(检测、分割)中,训练和推理都很昂贵。
👉 类比:
CNN 的计算像“邻居之间聊天”,高效;
ViT 是“所有人都要进大群聊”,群里人越多,聊天越慢。
5、 后续改进方向
- 数据依赖太大 → 引入训练技巧(DeiT, 2020)
- 问题:ViT 需要超大数据集(JFT-300M),在小数据集(比如 ImageNet-1k)表现不佳。
- 解决方案:DeiT(Data-efficient Image Transformer)引入了 知识蒸馏 技巧:
- 用一个 CNN(比如 ResNet-50)做“老师”,给 ViT 当“辅导班”。
- 这样 ViT 在只有 ImageNet-1k 这种中等规模数据时,也能学得很好。
👉 类比:
原版 ViT 是个“自学狂”,没有教材很难学;DeiT 给它找了个“经验丰富的家教老师”,结果学习效率大幅提升。
- 计算开销大 → 降低注意力复杂度(Swin Transformer, 2021)
- 问题:ViT 的自注意力是全局的,复杂度 O(N²),图片越大计算越夸张。
- 解决方案:Swin Transformer 提出 分层 + 窗口注意力:
- 先在局部小窗口里做自注意力(降低计算量)。
- 再通过滑动窗口(Shifted Window)逐步建立全局联系。
- 同时采用 金字塔结构,特征逐渐下采样,适合检测、分割等任务。
👉 类比:
原版 ViT = 所有人都在一个超大群里聊天(费时费力)。
Swin = 先分小组开会(窗口注意力),再小组代表开大会(层次化),既高效又全面。
- 缺乏归纳偏置 → 融合 CNN 特性(CvT, CoAtNet 等, 2021)
- 问题:ViT 完全不利用 CNN 的局部结构优势,导致小数据上泛化差。
- 解决方案:
- CvT(Convolutional ViT):在输入嵌入和注意力计算里引入卷积,增强局部建模能力。
- CoAtNet(CNN + Transformer):把 CNN 的归纳偏置和 Transformer 的全局建模结合。
- ConvNeXt:纯 CNN,但用 ViT 的设计经验做“现代化改造”,性能媲美 ViT。
👉 类比:
ViT 是“纯靠大数据训练的学霸”;这些改进让它也学点“常识”,就算没那么多训练样本,也能举一反三。
- 实用性改进 → 轻量化与高效部署(MobileViT, 2022)
- 问题:ViT 原版太大,不适合移动端或嵌入式设备。
- 解决方案:
- MobileViT:在 MobileNet 的框架下引入小型 Transformer,轻量高效。
- LeViT:混合 CNN + Transformer,专为推理速度优化。
👉 类比:
原版 ViT = 一台超大服务器。
MobileViT = 便携式“小型机”,能放进手机里运行。
✅ 总结
后续改进主要分 4 条路:
- 数据高效(DeiT) → 找老师帮忙,减少对大数据的依赖。
- 降低计算(Swin Transformer) → 用“分组开会”代替“大群聊”,大幅提高效率。
- 引入归纳偏置(CvT、CoAtNet) → 借鉴 CNN 的“常识”,增强小数据表现。
- 轻量化部署(MobileViT、LeViT) → 让 ViT 能跑在手机和嵌入式设备上。