Xception(2017):深度可分离卷积
导出时间:2025/11/23 20:21:38
研究背景与动机
(1)研究背景
在深度学习的发展过程中,图像识别的“明星模型”不断迭代:
- VGG16/19(2014):结构简单,但参数量巨大,计算成本高。
- Inception 系列(GoogLeNet, Inception V2/V3):通过“多分支卷积”同时捕捉不同尺度的特征,效率比 VGG 更高。
但是——Inception 模块虽然聪明,却也变得复杂:
- 要设计不同大小的卷积分支;
- 要人为调节参数,让每个分支合理分工;
- 网络结构越来越像“手工拼接的乐高积木”,缺乏简洁性。
在这样的背景下,研究者开始思考:
👉 有没有一种更简单、更通用的方法,可以替代 Inception 模块,又能保持甚至提升性能?
(2)研究动机
Xception 的提出,正是为了回答这个问题。它的名字来自 “Extreme Inception”,意思是“极端化的 Inception”。
研究者的核心思路是:
- Inception 的本质:把通道相关性(不同颜色通道之间的关系)和空间相关性(像素在平面上的关系)分开处理。
- 极端化的想法:既然可以部分分开,为什么不完全分开?
于是就有了 深度可分离卷积(Depthwise Separable Convolution):
- 先用 Depthwise 卷积:每个通道自己做卷积,相当于每个颜色通道各自戴上“单独的眼镜”观察图像。
- 再用 Pointwise 卷积(1×1 卷积):把这些通道的信息重新组合,相当于“把不同眼镜看到的内容整合起来”。
这样做的好处是:
- 结构比 Inception 简单得多(不需要手工设计多分支);
- 参数和计算量减少了,但特征表达力更强;
- 更容易扩展,适合在大数据集上训练。
(3)通俗类比
你可以把几种模型想象成“摄影师拍照”:
- VGG:用一台很大的相机,一次性拍下所有细节(笨重,费电)。
- Inception:带上不同焦距的镜头(广角、中景、特写),同时拍几张,再拼在一起(效果好,但操作麻烦)。
- Xception:干脆让每个颜色通道各自配一副“单独的镜头”,先独立拍,再合成一张清晰的照片(简单高效,还能拍得更细)。
✨ 一句话总结:
Xception 的动机是:把 Inception 的思想推向极致——完全分离通道信息和空间信息,用更简单的结构获得更强的性能。
模型结构
(1)核心思想:深度可分离卷积
Xception 的核心就是 深度可分离卷积(Depthwise Separable Convolution),它把卷积拆成了两个步骤:
- Depthwise 卷积(逐通道卷积)
- 相当于“每个通道(红、绿、蓝…)自己处理自己,不和别人交流”。
- 类比:好比有 3 个摄影师,分别只拍红光、绿光和蓝光的照片,各拍各的,不互相干扰。
- Pointwise 卷积(逐点卷积 / 1×1 卷积)
在 Depthwise 卷积 里,每个通道各自处理,结果是:
- 红色通道输出“红光特征图”;
- 绿色通道输出“绿光特征图”;
- 蓝色通道输出“蓝光特征图”。
👉 但是这样做有个问题:通道之间完全独立,互相不交流。- 就像三位摄影师分别拍了红光、绿光、蓝光的照片,但此时还没有合成完整的彩色照片。
- 如果只停在这一步,我们没法获得一个真正综合的图像理解。
于是,Pointwise 卷积登场了。它的任务就是: 把不同通道的特征重新组合,融合成新的特征表示。- Pointwise 卷积就是 1×1 卷积。
- 它的卷积核大小是 1×1,但会作用在所有通道上。
- 这意味着:
- 它不会在空间上(高和宽)移动范围,而是专门在 通道维度上做混合。
- 相当于“把所有通道的像素点在一个位置上的信息加权整合”。
举个例子:- 输入是 3 个通道(R、G、B),输出需要 5 个通道;
- 那么 Pointwise 卷积就会用 5 个 1×1×3 的卷积核,分别学习“如何把 RGB 混合成新通道”。
(2)整体架构
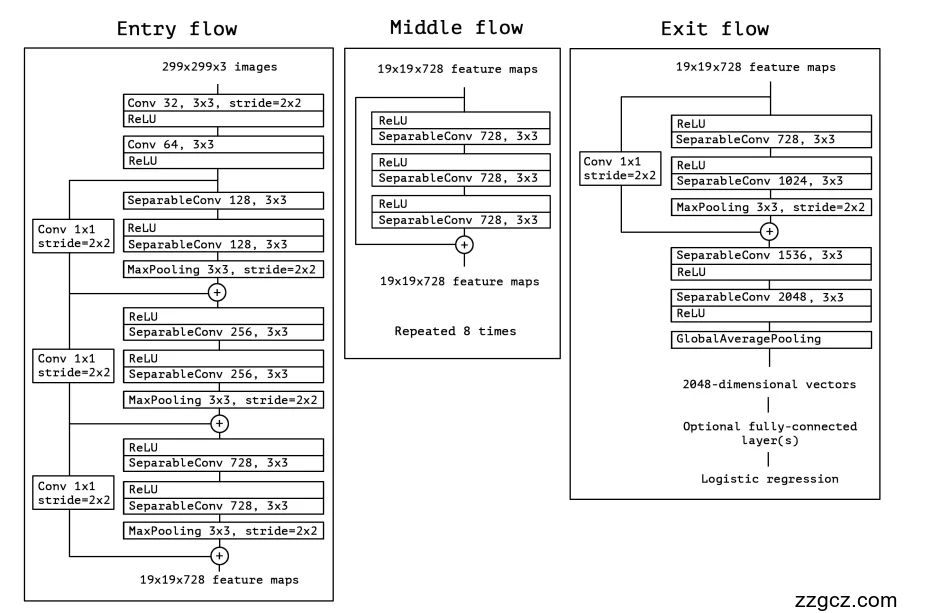
1)入口流(Entry Flow)=“入厂安检 + 预处理”
目的:把大图像先缩小到合适尺寸,同时抽取第一批有用的边缘/纹理特征,为后续重加工做准备。
按图分步看(以 299×299×3 输入为例):
- Conv 32, 3×3, stride=2 → ReLU 第一次快速“下采样”,像安检门先把人流分批放行。
- Conv 64, 3×3 → ReLU 再做一次基础特征扫描(边缘、角点)。
- 残差块 ×3(通道从 128→256→728,且每个残差块都做下采样)
每个残差块的主支路:
ReLU → SeparableConv K, 3×3 → ReLU → SeparableConv K, 3×3 → MaxPooling 3×3, stride=2跳支路:Conv 1×1, stride=2(做尺寸对齐) 然后相加(残差连接)。 作用:一边提炼特征、一边减半空间尺寸(如 299→149→…→19),把“原料”压缩成规格统一的中间品,方便进主车间。
设计要点:入口流里已经开始使用深度可分离卷积(SeparableConv),且卷积/可分离卷积后都接 BatchNorm(图中未画出),保证训练稳定;残差连接在除首末以外的模块广泛使用。
类比:像安检 + 初筛:先快速分流(stride=2),再把重要信息(边缘/纹理)贴上标签(通道数升高),为后续流水线做准备。
2)中间流(Middle Flow)=“主体流水线车间”
目的:在**固定的特征图尺寸(约 19×19)**上,把通道维度的表征打磨到位。
结构:同一个模块重复 8 次(输出通道保持 728),每个模块都是**“深度可分离卷积 ×3 + 残差恒等映射”**:
ReLU → SepConv 728 → ReLU → SepConv 728 → ReLU → SepConv 728 → 残差相加(恒等映射)
- 为什么重复 8 次? 把“同一套高效工序”反复跑,让特征从粗到细、层层打磨;因为有残差,信息能畅通回流,避免“越堆越训不动”。
- 为什么用深度可分离卷积? 先逐通道提空间特征(Depthwise),再用 1×1 混合通道(Pointwise),既省算力又有表达力——等价于把 Inception 的“多分支”思想极端简化为单一路径(论文把它称作“Extreme Inception”,即 Xception)。
类比:一个稳定可靠的自动化产线:每件半成品(特征)依次通过同样的 3 台机器(3 个可分离卷积),做精加工;残差是旁路输送带,保证加工不过度、信息不丢。
模块“重复 8 次”的事实与“三段式(入口/中间/出口)”来源于论文图 5。
3)出口流(Exit Flow)=“质检 + 打包出厂”
目的:在不再扩大特征图尺寸的前提下,拉高通道维度,做最后一次信息汇总,然后把空间维度压成向量去分类。
按图分步看:
- 过渡残差块(stride=2 下采样)
主支路:
ReLU → SepConv 728 → ReLU → SepConv 1024 → MaxPool 3×3, stride=2跳支路:Conv 1×1, stride=2→ 相加。 作用:把 19×19×728 的“中间品”升级到更高通道数(1024),同时再压一次空间尺寸,进入“终检工位”。 - 终检精加工
SepConv 1536, 3×3 → ReLU → SepConv 2048, 3×3 → ReLU作用:在通道维度做更强的非线性组合,形成最有判别力的语义特征。 - Global Average Pooling(全局平均池化) 把 H×W×C 压成 1×1×C(即一个 C 维向量),相当于对每个通道做“全局投票”,得到2048 维特征向量。
- (可选)全连接层 → Logistic/Softmax 分类器 论文实现是接逻辑回归层(Softmax),也可以在这之前插若干 FC。
类比:终检与打包:
- SepConv 1536/2048 = 更严格的质检与组合;
- GAP = 把每个“特征通道”的全局表现记为一票;
- Softmax = 打上“类别标签”,出厂。
3、模型缺点
缺点
| 详细解释
| 类比说明
|
1. 训练难度较高
| Xception 使用了大量深度可分离卷积和残差结构,虽然参数少,但梯度传播路径变复杂,容易对学习率、初始化敏感,需要好的训练技巧(如 BN、合适的优化器)。
| 就像一台自动化流水线设备很高效,但按钮特别多,没经验的工人一上来很容易“调坏机器”。
|
2. 对硬件依赖较大
| 深度可分离卷积虽然理论计算量少,但在实际硬件(尤其是早期 GPU/CPU)上并不一定比普通卷积快,因为需要额外的内存访问和通道操作。
| 好比你设计了一台分工特别细的生产线,但工厂搬运工效率跟不上,结果没有想象中快。
|
3. 模块堆叠过深
| 中间流堆叠了 8 个相同模块,总共 36 个卷积层,对小规模数据集来说容易过拟合,需要数据增强或正则化。
| 就像流水线工序太多,加工过度,反而把原料磨损了。
|
4. 缺少多尺度特征融合
| Xception 完全抛弃了 Inception 的“多分支结构”,虽然简洁,但可能丢掉了多尺度特征的优势,对目标大小差异大的任务(如检测、小目标识别)不一定最佳。
| 就像工厂只设计了一条单一流水线,效率高,但没法同时兼顾大件小件的产品加工。
|
5. 参数量和特征维度依旧较大
| 虽然比 Inception 高效,但最后输出是 2048 维向量,在下游任务(如嵌入、检索)中还是比较“重”,不够轻量化。
| 就像最终的产品虽然很精美,但包装箱还是比较大,不利于运输。
|
4、未来展望和改进思路(基于 Xception 的发展)
改进方向
| 代表模型
| 核心思路
| 类比解释
|
1. 轻量化部署
| MobileNet 系列
| 把 Depthwise + Pointwise 卷积的思想继承下来,但在设计时引入 宽度因子、分辨率因子 来进一步减少参数,适合手机和嵌入式设备。
| 就像把 Xception 的流水线做成“便携式小工厂”,能放进背包随身带,虽然产能小一点,但能随时随地生产。
|
2. 多尺度特征融合
| EfficientNet
| Xception 虽然极简,但放弃了 Inception 的“多分支”。后续改进尝试重新结合多尺度(EfficientNet 中通过复合缩放策略:宽度+深度+分辨率一起调节)。
| 就像重新在流水线上增加“大小件分流工位”,让大件小件的原料都能加工得合适。
|
3. 自动化结构搜索
| NASNet
| 不再完全靠人工设计,而是用 神经结构搜索(NAS) 自动寻找最优的卷积模块组合,结果往往比单纯“极端化”的 Xception 更高效。
| 就像工厂老板不再自己画流程图,而是请一个“AI 工程师”自动生成最优生产线。
|
4. 与注意力机制结合
| SENet
| 在卷积的基础上引入通道注意力(Squeeze-and-Excitation),让模型自动学会“哪些通道更重要”。
| 就像工厂里的质检员,不是所有零件都一样重视,而是会特别关注关键零件。
|
5. 更加轻量化 & 高效推理
| ShuffleNet、GhostNet
| 在深度可分离卷积的框架下,结合更高效的激活函数、组卷积与通道重用,进一步减少计算。
| 就像工厂里用上了 节能机器,既省电又快,特别适合小型工厂。
|