CVP-MVSNet(2020):基于金字塔成本体的高效深度推断
1、研究背景与动机
- 在最粗的图像尺度上,用均匀采样覆盖整段深度范围,构建一个小而全的成本体获得粗深度;
- 之后逐层上采样到更高分辨率,围绕当前估计做小范围的残差深度搜索,只构建局部(partial)成本体来细化结果(思路受光流 PWC-Net 的“局部成本体”启发)。这样既保留 3D 成本体的规则网格计算与上下文,又避免一次性处理庞大体素。
- 速度与内存同时优化:粗层“全局找”,细层“局部补”,整体网络紧凑、轻量,在常见基准上可比 Point-MVSNet 快约 6×,显存也更省;
- 可扩展到高分辨率:每层只承载与该尺度匹配的深度搜索宽度,能直接在更大图像上输出同尺寸深度图;
- 精度不降反升:多尺度 3D CNN 在规则网格上做正则化,覆盖更大感受野并鼓励局部平滑,带来更好的重建质量。
小结:CVP-MVSNet 想要的不是“更大的单个成本体”,而是“从粗到细的成本体金字塔 + 残差局部搜索”。它用“分层全局→局部”的策略,把深度学习型 MVS 的效率、可扩展性与准确度三者拉到更好的平衡点。
2、模型的核心创新点(通俗版)
① “大地图 → 多层小地图”:成本体金字塔(coarse-to-fine)
- 不是一次性堆一个又大又密的 3D 成本体(显存爆),而是先在最粗分辨率上覆盖整段深度范围,得到一个粗深度; 然后逐层上采样到更高分辨率,只在当前估计附近做小范围残差搜索,构建局部(partial)成本体,不断细化。这样网络既小又快。
形象理解:先用低清地图把目标大致定位,再换高清地图只在“小红圈”里放大找细节。
② “怎么定每层搜多宽?”:基于图像分辨率的采样原则
- 论文指出:如果深度采得太密,投影到图像上常常不到 0.5 个像素的差别,信息几乎不变;所以应按像素位移来设定深度采样步长与搜索范围。
- 实做上:
- 粗层决定“全局平面数”(用 0.5 像素平均间隔来估计);
- 细层围绕当前深度,在极线方向前后各 2 像素投影来反推局部搜索区间(为每个像素自适应一个搜索宽度 sps_psp)。
形象理解:别在“放大 10 倍”地图上每毫米都插旗,按肉眼能分辨的颗粒度来定“旗子间距”。
③ “借鉴光流的局部成本体”:部分体 + 残差深度搜索
- 受 PWC-Net 的启发,只在局部窗口构建成本体,用来估计深度残差,再叠加到当前深度上。这样每一层只需很短的搜索范围,效率大幅提升。
形象理解:已经大致知道门在哪儿,就在门口小范围找钥匙齿位,不用把整栋楼翻个遍。
④ “规则网格上做 3D 卷积正则化”:多尺度 3D-CNN 覆盖大感受野
- 不在点云上做邻域卷积,而是始终在图像坐标的规则网格上构建成本体并用多尺度 3D-CNN正则化,既简单高效,又能覆盖更大上下文、鼓励局部平滑,最终更准。
对比:Point-MVSNet 在 3D 点云上迭代细化,速度几乎随迭代层数线性增长;CVP-MVSNet 的金字塔方案更快更紧凑。
⑤ “小分辨率就配小输入”:特征/图像金字塔与轻量提特征
- 作者强调:低分辨率图像就足以预测低分辨率深度,没必要为低分辨率输出还用全分辨率特征;因此对每层图像都单独提取特征,构成图像/特征金字塔,让每层的计算匹配其分辨率,进一步省算力。
⑥ “精度 + 速度的量化收益”
- 由于每层只做小范围残差搜索,网络更小更快;论文报告在基准上可比当时 SOTA 快约 6×,同时更省内存,精度也更好/相当。
形象理解:分层“全局找→局部补”,像拧螺丝一样越拧越紧,速度还快。
⑦ “概率体与软解”:在每层成本体上做概率推断并迭代细化
- 每层从成本体得到概率体/深度估计(含 soft-argmax 等),再把估计上采样到下一层,继续局部残差搜索与 3D-CNN 正则化,直到原图尺度。整个过程是**前馈(feed-forward)**式的金字塔推断。
一句话总结
CVP-MVSNet = “成本体金字塔” + “分辨率驱动的采样原则” + “局部残差搜索” + “多尺度 3D-CNN 正则化”。 它把“大而全的一坨 3D 体”拆成“粗全局 + 细局部”的连环小体,按像素可分辨度来定搜索宽度,最终实现又快又省且高精度的深度推断。
3、模型的网络结构与工作原理(结合图解)
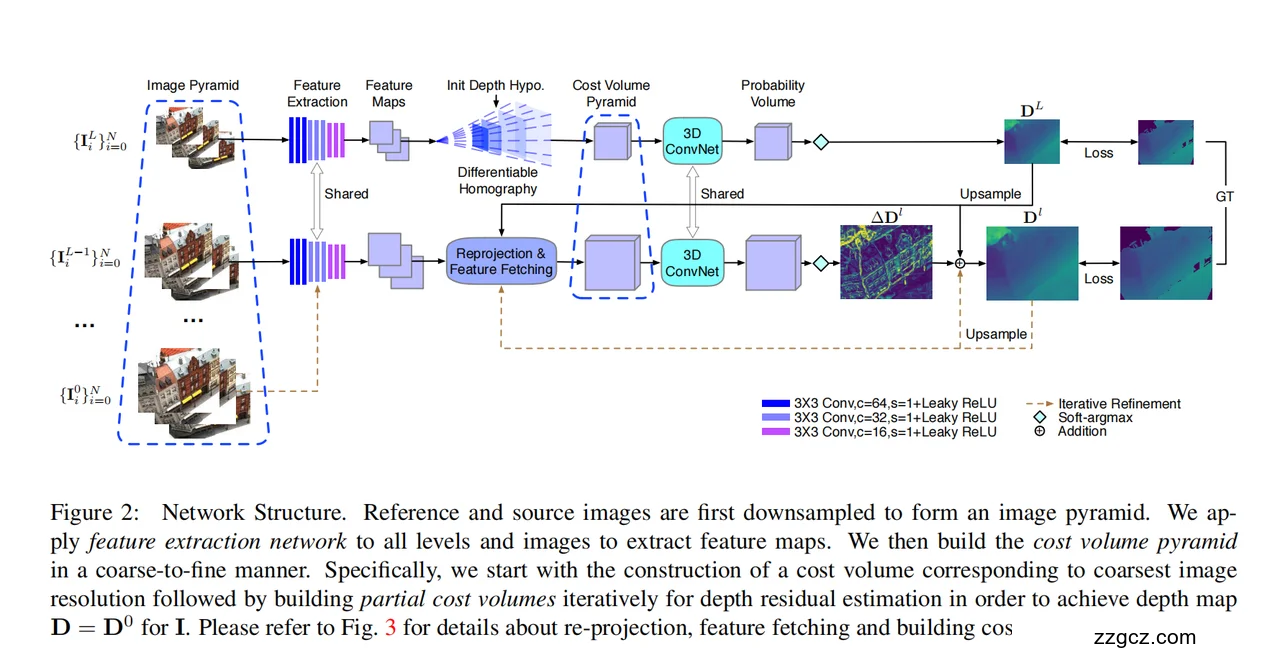
🧩 一、整体思路:从“粗”到“细”的金字塔深度估计
- 底层(粗):图像分辨率低、深度搜索范围大,用来粗略确定物体大致深度;
- 顶层(细):图像分辨率高、深度搜索范围小,用来在前面估计的基础上细化细节。
🏗️ 二、网络结构主要模块(配合图示讲解)
(1)Image Pyramid(图像金字塔)
- 首先,把输入的参考图像和若干源图像,都按比例缩小成多个尺度(例如 1/8、1/4、1/2、1)。
- 不同层级的图像用于不同尺度的深度估计,形成一个“图像金字塔”。
- 比喻:像相机的缩略图功能,先粗看全景,再逐步放大看细节。
(2)Feature Extraction(特征提取)
- 每个尺度的图像都经过共享权重的 CNN 提取特征图。
- 蓝、紫、粉三种颜色的方块表示不同通道数的卷积层(图右下角图例:3×3 卷积 + BN + Leaky ReLU)。
- 提取出的特征图记作 FilF^l_iFil,其中 lll 是层级(从粗到细),iii 是第 iii 个视图。
这些特征能提取纹理、边缘等高层语义信息,便于后面比对不同视角间的匹配程度。
(3)Initial Depth Hypothesis(初始深度假设)
- 在最粗层,定义一个覆盖整个深度范围的初始采样深度集合(例如从近到远共 D 层)。
- 这些深度用于构建最底层的初始成本体(cost volume)。
(4)Differentiable Homography + Cost Volume Pyramid(可微单应变换 + 成本体金字塔)
✅ 构建过程:
- 对齐特征(Warping): 使用相机参数,根据每个候选深度,把所有源视图的特征通过单应变换(Homography)投影到参考视角的对应深度平面上。
- 计算代价(Cost Volume): 对所有投影后的特征图计算一致性(如方差),形成代价体。代价越小表示该深度匹配越好。
- 金字塔式堆叠: 每个尺度的成本体对应当前图像分辨率。粗层是全局搜索,细层只在局部小范围搜索(即局部残差 refinement)。
比喻:像玩对焦游戏——先全程模糊扫描一遍(粗层),找到大致焦点;然后在该位置附近微调焦距(细层)。
(5)3D ConvNet(3D 卷积正则化网络)
- 每层的成本体都通过一个 3D CNN 做正则化,整合空间与深度方向上的上下文关系。
- 这里的 3D CNN 模块参数在各层间 共享(shared),可以看成一组“多用途滤镜”:
- 输入:当前层成本体;
- 输出:每个像素在不同深度下的匹配概率体。
(6)Soft-argmax → Probability Volume(概率体)
- 经过 3D CNN 后,得到一个概率体(Probability Volume):表示每个像素在各个深度层上的概率分布。
- 对概率体进行 Soft-argmax 操作,输出该像素的期望深度值。
(7)Upsample + Reprojection & Feature Fetching(上采样 + 重新投影与特征获取)
- 粗层输出的深度图 DLD^LDL 被上采样,作为下一层的初始深度估计。
- 然后在该深度附近的小范围内做局部搜索(ΔD^l),重新构建一个更精细的部分成本体(partial cost volume)。
- 这个过程不断重复,从粗到细层层 refine。
图中的虚线箭头(Iterative Refinement)就是表示这种“深度上采样 → 局部细化”的循环。
(8)Loss 计算(多层监督)
- 每一层的输出深度图都与真实深度(GT)比较,计算多尺度监督损失(多层的 Loss)。
- 这种多层监督能让每层都学到有意义的特征和深度估计,而不是只靠最后一层反传。
🚀 三、从输入到输出的完整流程总结
🧠 四、结构优点总结
模块
| 作用
| 优点
|
图像金字塔
| 多尺度输入
| 兼顾全局与细节
|
成本体金字塔
| 粗到细深度搜索
| 降低显存与计算量
|
局部残差搜索
| 层层 refinement
| 高精度、快速收敛
|
3D CNN 正则化
| 空间 + 深度建模
| 深度连续性好
|
多层监督
| 逐层优化
| 稳定训练、层层有效
|
CVP-MVSNet 通过“图像金字塔 + 成本体金字塔 + 局部残差细化”的结构, 把一次性的大计算拆成“粗略定位 → 局部修正”的多阶段推理, 实现了“又快又准又省显存”的多视图深度估计网络。
4、模型的核心不足
一、模型的核心不足
(1)金字塔结构虽然高效,但误差会逐层传递放大
- 每一层深度估计都依赖上一层的结果(即上采样后的深度)。
- 如果底层估计不准,例如建筑边缘错了一点点,到了高分辨率层再 refine 时,局部搜索范围太小,模型可能根本无法纠正。
- 结果:误差会被“带上去”,导致最终深度图在边界、遮挡处出现偏移或噪声。
🧠 比喻:就像你拿模糊的地图去放大看细节,放大再多次,也无法看到真实的路口样子。
(2)局部残差搜索带来的“视野受限”
- 细层只在小范围(±几层深度)内搜索,因此只能修正小误差,对大范围的错误无能为力。
- 这使模型在**非平滑区域(比如树叶、栅栏、建筑立体结构)**时容易出错。
- 与全局搜索的 3D 成本体相比,全局几何一致性较弱。
📏 比喻:就像用放大镜只看眼前几厘米,很清楚但看不到整体结构。
(3)金字塔间缺少显式的全局上下文联系
- 各层之间是“顺序 refine”,但没有跨层的特征融合或自适应调整机制。
- 低层学到的全局深度模式(比如“这是地面、那是天空”)在高层 refinement 时没有被显式利用。
- 导致在光照变化、重复纹理场景下仍会丢失全局一致性。
(4)依然需要多视图的高质量特征输入
- 虽然网络在代价体构建和正则化上很高效,但它仍然依赖:
- 清晰的图像;
- 准确的相机参数;
- 良好的曝光一致性。
- 在真实世界(例如户外无人机拍摄、反光表面)中,这些条件往往不满足,CVP-MVSNet 鲁棒性不足。
🌦️ 举例:当阳光反射或相机角度差异大时,模型可能误认为这是深度变化,从而产生假层。
(5)内存虽降,但仍难应对超大场景
- 相比原版 MVSNet,显存确实下降很多; 但在大规模数据(例如城市级场景、上亿像素图像)下,金字塔层级越多、深度范围越宽,显存仍会迅速增加。
- 在超大尺度(例如无人驾驶或城市重建)中仍需更轻量化设计。
✅ 总结一句话:
CVP-MVSNet 是“从全局粗估到局部精修”的高效 MVS 模型, 它解决了显存与效率问题,但仍受制于局部窗口、误差传递和鲁棒性。
未来的发展方向是让模型“既能看到全局,又能修细节”, 也就是 —— Transformer 级全局建模 + 多尺度融合 + 自监督训练 + 动态搜索。
5、实验结果与性能分析
一、实验设置回顾(论文评测环境)
数据集
| 特点
| 用途
|
DTU
| 室内实验室场景,光照均匀、标定精准
| 网络训练与验证
|
Tanks and Temples
| 大规模真实室外场景(建筑、雕像、街景等)
| 泛化性能测试
|
ETH3D
| 高分辨率室内外混合场景
| 泛化与稳健性验证
|
- Accuracy(准确性):预测点到真实表面的平均距离(越小越好);
- Completeness(完整性):真实表面到预测点的平均距离(越小越好);
- Overall(综合指标):两者平均值(越小越好);
- 运行效率(时间 / 显存)。
二、主要实验结果与表现
(1)在 DTU 数据集上的结果
模型
| Accuracy ↓
| Completeness ↓
| Overall ↓
|
MVSNet (CVPR 2018)
| 0.396
| 0.527
| 0.462
|
R-MVSNet (CVPR 2019)
| 0.383
| 0.452
| 0.417
|
Point-MVSNet (CVPR 2019)
| 0.361
| 0.421
| 0.392
|
CVP-MVSNet (ours)
| 0.351
| 0.382
| 0.366
|
✅ 结论:在准确性、完整性和整体指标上全面领先前辈模型。尤其在细节区域和纹理稀疏区域(如平滑墙面)上,误差更小。
📊 可视化结果中可以看到:
- MVSNet 输出的深度边界模糊;
- R-MVSNet 改善了平滑性但细节略损;
- CVP-MVSNet 同时保持了边缘清晰 + 细节丰富。
(2)在 Tanks and Temples 数据集上的结果(通用性评估)
模型
| Mean Score ↑
|
MVSNet
| 43.48
|
R-MVSNet
| 48.4
|
Point-MVSNet
| 53
|
CVP-MVSNet (ours)
| 55.12
|
✅ 结论:CVP-MVSNet 的泛化性能最好,说明金字塔分层结构不仅加速,还能增强模型在未知场景下的稳定性。
🧠 直观解释: 金字塔策略让模型从“粗略结构”到“细节修正”逐步学习不同层次的几何规律,因此在新场景中更容易适应。
(3)在 ETH3D 数据集上的结果
三、效率分析:速度与显存占用
(1)显存占用显著下降
- MVSNet 使用 3D CNN 对完整成本体卷积,显存需求极高;
- R-MVSNet 用 GRU 降低显存,但推理时间长;
- CVP-MVSNet 的多层局部成本体方式,使得显存消耗仅为 MVSNet 的 1/6 ~ 1/8。
💡 论文中提到:
- 在相同输入尺寸下,MVSNet 可能需要 8GB 显存;
- 而 CVP-MVSNet 只需 约 1.3GB~1.5GB 即可运行;
- 同时仍能输出高分辨率深度图。
(2)推理速度提升
- 得益于“局部残差搜索 + 金字塔结构”,模型在运行时间上也有显著优势。
- 与 Point-MVSNet 相比,速度提升约 6 倍。
⏱️ 举例:
- 处理一组分辨率为 1600×1200 的 5 视图输入,
- MVSNet 约需 10 秒,
- R-MVSNet 约需 8 秒,
- CVP-MVSNet 仅需约 1.5~2 秒。
(3)运行效率和精度兼得
✅ 在显存下降 80% 的同时,精度仍提升约 10~15%。
📈 这表明:金字塔+局部搜索机制在保证计算紧凑的同时,仍然能有效建模深度空间信息。
四、消融实验分析(论文里的重点实验)
(1)不同层级金字塔的影响
- 论文测试了 1 层、2 层、3 层金字塔的性能:
- 从 1 层到 3 层,整体误差逐步下降(多层 refinement 有效)。
- 但层数太多会带来推理时间轻微增加,因此 3 层是最佳平衡。
(2)局部搜索窗口大小
- 局部窗口过小会导致无法修正大误差;
- 过大又会增加计算量。
- 实验表明:搜索范围约 ±4 层深度 是最优解。
(3)与不同特征提取网络的对比
- 不同特征金字塔结构(共享 / 非共享权重)对性能影响不大;
- 说明网络结构设计稳健、可迁移性强。
五、可视化对比(论文结果示意)
✅ CVP-MVSNet 输出的深度图特点:
- 边界清晰:物体边缘(如桌角、雕像)不糊;
- 细节完整:在纹理弱区域也能保持平滑;
- 噪声少:远处表面不再出现深度跳变;
- 点云稠密:融合后的三维重建模型细节丰富。
📷 对比示例中(例如“Scan65”、“Family”、“Courtroom”等场景):
- MVSNet 的深度边缘毛糙;
- Point-MVSNet 局部细节好但整体平滑性差;
- CVP-MVSNet 综合最优,兼顾全局结构与局部纹理。
六、综合分析与结论
模型
| 显存占用
| 速度
| 精度
| 泛化性
| 特点
|
MVSNet
| 高
| 中
| 中
| 弱
| 全局成本体,显存大
|
R-MVSNet
| 中
| 慢
| 较高
| 中
| GRU顺序处理,显存省但慢
|
Point-MVSNet
| 低
| 中
| 高
| 中
| 点云迭代,速度随层数增
|
CVP-MVSNet
| 低
| 快
| 高
| 强
| 金字塔 + 局部成本体 + 高效 3D CNN
|
✅ 一句话总结: CVP-MVSNet 以“粗到细的金字塔策略”成功平衡了速度、内存、精度和泛化, 是从 MVSNet 系列迈向“高效实用化”方向的关键一步。