CasMVSNet(2020) :级联代价体:用于高分辨率多视角立体视觉与立体匹配。级联思想,后续大部分方法的原型
导出时间:2025/11/24 08:52:12
1、 背景:MVSNet 的问题
你之前学过 MVSNet:它是第一个端到端的多视角立体视觉网络。
它的思想很棒——用 CNN 特征 + 可微投影 → 构造代价体 (cost volume) → 3D CNN 正则化 → 输出深度图。
但是它有一个致命缺点:
- 代价体太大了!
- 代价体大小是 D × H × W,D 是深度层数,H/W 是图像分辨率。
- 举例:假设要处理一张 1000×1000 像素的图像,深度范围采样 256 层:
- 256×1000×1000≈2.56×10的8次方
- 这对 GPU 显存来说是“灾难”。
- 结果就是:MVSNet 只能处理 低分辨率小图,在真实大场景里跑不动。
👉 简单比喻:
就像你要在一栋大楼里找人,MVSNet 的做法是“把大楼里每个房间都复制一遍,做成一本厚厚的相册”,最后翻完再决定人在哪。
这当然能找到,但太占地方、太慢。
2、CasMVSNet 的动机:级联金字塔
研究者们就问:
- 有没有办法 不用一次把所有深度都算出来,而是先粗略估计,再逐渐细化?
- 就像人类在找东西时,先大致缩小范围,再精确定位。
于是,他们提出了 CasMVSNet (Cascade MVSNet):
- 粗到细 (coarse-to-fine) 的策略:
- 先在低分辨率图像上估一个粗糙深度 → 范围大,但不精细。
- 再在更高分辨率上缩小范围、采样更密 → 精度提高。
- 最后在最高分辨率上做精细估计。
- 每一层只需要构建一个小得多的代价体,逐层 refine。
- 这样既保证了精度,又大幅节省了显存和计算。
👉 比喻:
- MVSNet = 一上来就用“放大镜”,把整个场景每个细节都看一遍,太累。
- CasMVSNet = 先用“望远镜”大致看看人在哪个楼层,再用“放大镜”去看具体哪个房间。
✅ 总结
- 背景:MVSNet 提出了端到端 MVS,但代价体太大,限制了分辨率和场景规模。
- 动机:CasMVSNet 引入 级联金字塔 (Cascade) 思想,逐层 refine 深度 → 既快又省内存,同时还能保持高精度。
3、 CasMVSNet 的三大核心创新
1. 级联金字塔 (Cascade) 结构
- MVSNet 一次性在高分辨率 & 大深度范围上构造代价体 → 显存爆炸。
- CasMVSNet 改成 多阶段、粗到细的金字塔结构:
- Stage 1(低分辨率,大范围): 在低分辨率的特征图上,均匀采样一个大深度范围,得到粗糙估计。
- Stage 2(中分辨率,中范围): 用 Stage 1 的结果作为先验,只在它附近的小范围继续采样 → 更精细。
- Stage 3(高分辨率,小范围): 最终在高分辨率上,围绕预测结果做精细搜索,得到高质量深度图。
👉 比喻:
找人 = 先看哪一栋楼(粗),再看哪一层楼(中),最后看具体哪个房间(细)。
这样比“一口气搜完整栋楼的每个房间”快太多了。
2. 自适应深度采样 (Adaptive Sampling)
- 每一层的采样范围不是固定的,而是根据上一层预测结果动态调整。
- 这样既不会浪费采样在远离真值的地方,也能保证精度。
👉 比喻:
你如果已经知道人可能在 3 楼,就不会再去搜 1 楼或 10 楼,而是只在 2~4 楼之间仔细搜。
📌 总结
CasMVSNet 的核心创新点:
- 级联金字塔:多阶段 coarse-to-fine,逐层 refine。
- 自适应采样:用上一层预测指导下一层搜索。
- 高效高分辨率:减少显存和计算,同时输出高质量深度图。
👉 所以 CasMVSNet 被认为是 MVSNet 的“真正实用化版本”,几乎所有后续工作(如 UCSNet、PatchmatchNet)都借鉴了它的级联思想。
4、 图解 CasMVSNet 网络结构
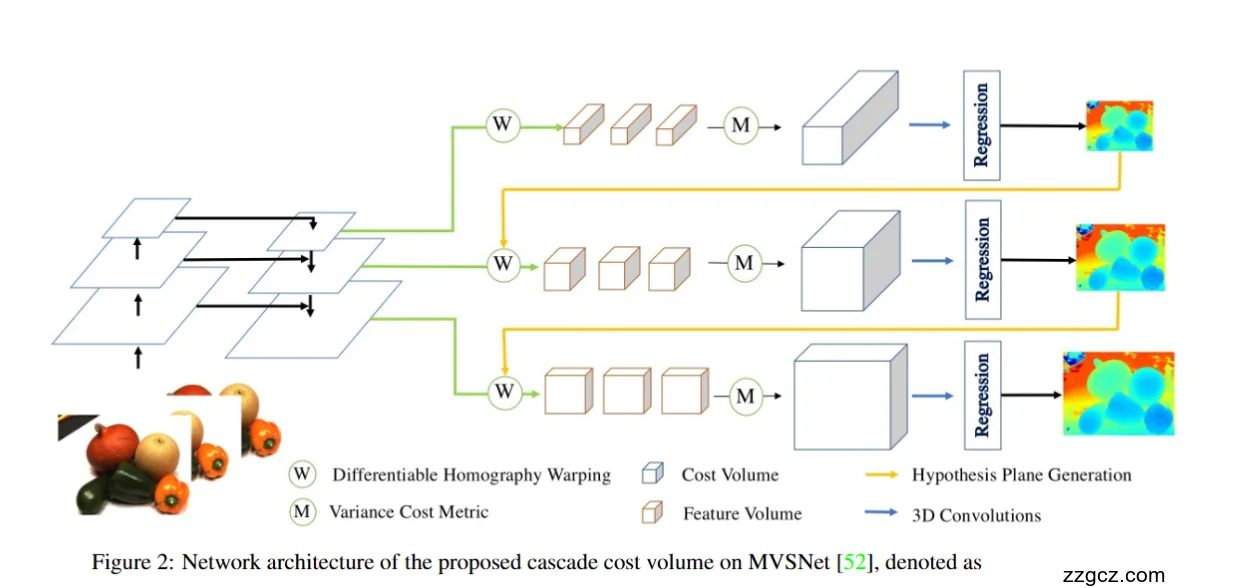
从左到右,大致可以分为 输入图像 → 多阶段级联 → 深度预测 这几块。
1️⃣ 输入图像与特征提取
左下角是一组输入图像(水果场景 🍎🍊🥒)。
- 首先,每张图像会经过 CNN 提取特征(图中橙色小方块 = feature volume)。
- 这些特征比像素更有辨识力,能更好地做匹配。
2️⃣ 多阶段级联(关键创新)
你看到图中有 三层结构(绿色箭头 → 黄色箭头 → 最终蓝色箭头),这就是 级联金字塔:
(a)第一阶段:粗匹配(Coarse Stage)
- 输入分辨率低(小 feature maps)。
- 用 可微单应性 (W) 把源图像投影到参考相机视角,构造一个粗糙的 cost volume(浅蓝色长方体)。
- 用方差度量 (M) 聚合不同视角特征,得到一致性评分。
- 用 3D CNN 学习正则化,回归 (Regression) 出一个粗糙深度图(右边的第一张热力图)。
👉 像是“先大概看人在哪栋楼”。
(b)第二阶段:中等分辨率(Medium Stage)
- 以上一阶段的预测为“先验”,在它附近生成更小范围的 假设平面 (Hypothesis Plane Generation)。
- 再次用 (W) 可微单应性,把图像对齐,得到一个新的 更小、更精细的 cost volume。
- 经过 3D CNN,输出更细的深度图(右边的第二张热力图)。
👉 像是“缩小范围 → 看人在哪一层楼”。
(c)第三阶段:精细预测(Fine Stage)
- 在最高分辨率下运行。
- 深度采样范围更小,但分辨率更高,所以能得到清晰细节。
- 再经过一次 cost volume 构造 + 3D CNN 正则化,输出最终精细深度图(右边最后一张热力图)。
👉 像是“精确定位 → 确认具体在哪个房间”。
3️⃣ 输出
- 最终得到的深度图比 MVSNet 高分辨率得多,边缘清晰、噪声更少。
- 而且由于逐级 refine,计算和显存大大节省。
5、CasMVSNet 的重大缺点
虽然 CasMVSNet 相比 MVSNet 有了很大进步(显存少、速度快、分辨率高),但依然存在一些不足:
- 推理速度依旧较慢
- 虽然分阶段减少了代价体大小,但每个阶段还是要构造 cost volume + 3D CNN。
- 在高分辨率和多张图像输入时,计算量仍然很大,难以实时。
- 深度采样策略有限
- 它是“围绕上一次预测结果,在小范围均匀采样”。
- 如果上一次预测不准,下一阶段可能“采歪了”,导致误差累积。
- 对相机位姿依赖强
- 和 MVSNet 一样,CasMVSNet 需要准确的相机姿态输入。
- 一旦 SfM / SLAM 的位姿估计有误,深度预测也会出错。
- 遮挡 / 纹理缺乏区域表现不佳
- 代价体方法还是依赖光度一致性。
- 在低纹理区域(如白墙)或遮挡严重的场景中,深度估计不够鲁棒。
6、基于 CasMVSNet 的改进模型
研究者在 CasMVSNet 的基础上,提出了很多改进:
1. 效率改进
- UCSNet (CVPR 2020)
- 提出 可变采样 (Adaptive Sampling),不用固定均匀采样,能更灵活地选择深度假设,提高效率与精度。
- PatchmatchNet (CVPR 2021)
- 不再构造完整的代价体,而是借鉴传统 PatchMatch 算法,进行逐像素深度传播与更新。
- 极大降低显存和计算量,可以处理大规模场景。
2. 语义 / 全局上下文增强
- TransMVSNet (CVPR 2022)
- 引入 Transformer,让网络能捕捉跨区域、跨视角的全局关系。
- 在遮挡和低纹理区域表现更好。
- AA-RMVSNet (ECCV 2020)
- 在 3D 卷积里加入 注意力机制,提升 cost volume 正则化效果。
3. 鲁棒性提升
- CVP-MVSNet (CVPR 2020)
- 利用深度回归的不确定性来引导采样,减少误差累积。
- Vis-MVSNet (CVPR 2021)
- 引入显式遮挡建模(visibility reasoning),提升在遮挡区域的鲁棒性。
4. 大模型与泛化方向
- DUSt3R (CVPR 2024)
- 摆脱了对相机姿态的严格依赖,直接预测点云(pointmap)。
- 能够在大范围场景中稳健工作。
- MVSAnywhere (CVPR 2025)
- 把单目大模型(MiDaS/ZoeDepth)的语义先验与 MVS 几何结合。
- 真正实现“零样本泛化”,任何场景都能用。