MVSAnywhere(2025):现阶段的终点,零样本泛化方向
导出时间:2025/11/24 08:54:59
1、研究背景
- 多视图立体(MVS)的重要性 多视图立体任务就是从多张带有相机位姿的图片中,估计出场景的三维几何(深度)。它是三维重建、自动驾驶、VR/AR 等下游应用的核心技术。
- 现有 MVS 方法的瓶颈
传统的深度学习 MVS 模型(比如学过的 MVSNet、CasMVSNet、TransMVSNet):
- 在 特定场景(如室内 or 室外)表现很好,但 跨场景泛化性差。
- 通常需要提前 知道深度范围,否则无法正确构建代价体积(cost volume)。
- 单视图深度模型的启发
最近几年出现了一批通用的 单视图深度估计模型(比如 DepthAnything、DepthPro 等),它们在各种场景都能预测出相对合理的深度。
- 优点:泛化性强。
- 缺点:只有单张图像,缺乏多视图几何约束,因此深度比例容易不准确。
2、MVSAnywhere 的动机
论文作者想解决的关键问题是:能不能有一个既继承单视图模型的泛化能力,又能利用多视图信息保证深度尺度和几何一致性的通用 MVS 系统?
他们总结了几个核心挑战:
- 跨领域泛化 模型需要在 室内、室外、无人机航拍、自动驾驶 等各种环境下都能工作,而不仅仅局限于某一种场景。
- 深度范围自适应
场景差异很大:
- 室内只有几米深度;
- 室外可能上百米。 传统 MVS 方法依赖固定的深度区间,难以适配这种差异。
- 充分利用 Transformer 架构 Transformer 在视觉中已经很强(ViT、DepthAnything),作者希望把它引入 MVS,而不仅仅停留在 CNN 特征提取阶段。
- 视图数量可变 现实中输入的图像数量可能变化(比如 2 张、5 张、10 张),模型需要能处理不同数量的源视图,而不是依赖固定输入。
3、MVSAnywhere(MVSA) 的整体流程与每个模块
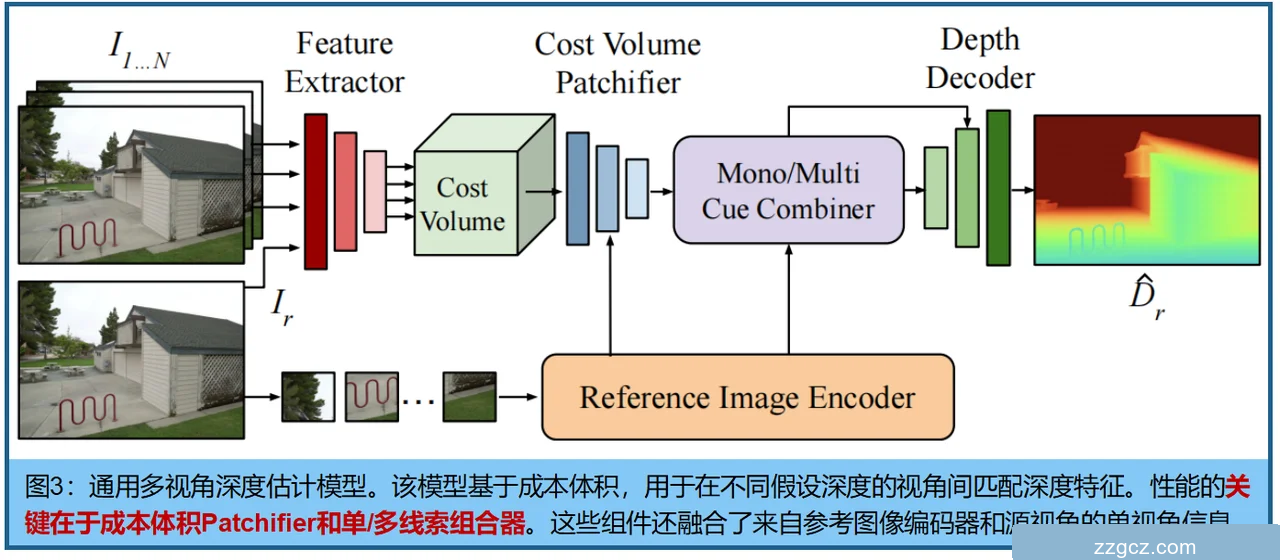
Feature Extractor(特征提取器)
它做什么?
- 把输入的每张源图像 I1,I2,…,INI和参照图像 Ir,转成比较“鲁棒”的特征图(不是原始像素)。
- 特征图分辨率通常缩小到原图的 1/4,但通道数增加(16、32 维等)。
- 这些特征主要用于图像间的几何匹配,也就是构建 Cost Volume(代价体积)。
为什么需要?
- 直接比像素会受光照、纹理弱等干扰。
- 特征提取器能学到“同一个物体在不同视角下”的稳定表示,让匹配更可靠。
代码里怎么做的?
- 两种实现:
- ResNetMatchingEncoder
- 用轻量 ResNet(conv1 + layer1),stride=4,下采样到 1/4 尺度。
- 接几层卷积调整通道数(输出 16 或 32)。
- 输出:
B × C × H/4 × W/4的特征图。
- UNetMatchingEncoder
- 用 MNASNet backbone,FPN 融合多尺度,再取 1/4 尺度的特征,通道数固定 16。
- ResNetMatchingEncoder
👉 所以 Feature Extractor 分支就是所有图像都走一遍,得到一堆几何匹配特征。
Reference Image Encoder(参考图像编码器)
它做什么?
可以把它理解成:
- 在主流程里,我们已经有了一个“成本体”,它记录了多视角几何的匹配信息;
- 但这个成本体的弱点是:细节容易模糊,比如窗框、树叶的边缘,或者被遮挡的地方;
- 所以单独开了一条“旁路”,专门把参照图像 Ir再做一次更深的编码,提取高层次语义/单目深度先验。
这条旁路得到的结果,就叫 参考图特征。
为什么需要它?
单靠几何匹配,遇到遮挡/纹理差区域,深度就会很不稳定。
参考图像编码器(一般是 ViT + DINOv2)可以学到物体的语义、结构信息,提供更全局、更高层的线索。
它是怎么被用的?
- 送给单/多线索融合器:
在“Mono/Multi Cue Combiner”模块里,成本体的几何证据会和参考图特征一起融合。
- 成本体给“哪个深度靠谱”;
- 参考图特征给“这个地方应该长什么样子”。 两者结合,能得到既有几何精度又有细节的深度表示。
- 送给解码器做“跳连”或“引导”: 解码器最后要生成整张深度图。在上采样、恢复分辨率的过程中,如果只有模糊的成本体,画出来的深度图也会模糊。 但如果在解码的不同阶段,都能把参考图的清晰特征“插进来”当提示,就像是描图纸一样,最后的深度边缘会更清楚。
代码里怎么做的?
- 用
DINOv2这样的 ViT:- 把图像切成 patch,过 Transformer,输出多层 token。
- 用
DPTHead把 token reshape 回空间特征图(多尺度)。 - (可选)
ViTCVEncoder会把几何分支的特征打包成 token,在 ViT 的某些层跟单目 token 融合。
- 输出:参照图像的多尺度特征,语义更强,可以和 Cost Volume 特征结合。
🔑 二者的关系(结合图)
- Feature Extractor: 所有图(源 + 参照)走 → 输出几何匹配特征 → 构建 Cost Volume。
- Reference Image Encoder: 只对参照图 IrI_rIr 走 → 输出高层单目/语义特征 → 在 Mono/Multi Cue Combiner 阶段和代价体积融合。
可以理解为:
- Feature Extractor = “几何眼睛”,看像素差异。
- Reference Encoder = “语义大脑”,知道这是墙、地面、车子。
- 两者结合,才让深度估计既精细(几何)又稳定(语义)。
Cost Volume(代价体,基于平面扫描/深度假设)
一个 3D 张量,表示“某个像素在不同深度假设下的匹配代价”。
为什么叫“Cost Volume”?
- Cost(代价):意思是“匹配的好坏”。假设一个像素在某个深度上,你去别的相机视角找对应的像素,看它们像不像。如果像,就说明这个深度合理,代价小;不像,就说明深度错了,代价大。
- Volume(体):因为我们不是只看一层,而是要在很多个深度假设上都做检查,相当于堆成了一个“三维积木块”。所以叫体。
你可以想象成:每个像素的背后都有一条“深度尺”,在这条尺子的每一格上,都记一笔“这个深度合不合理”的分数。所有像素的深度尺放在一起,就变成一个三维大方块,也就是 成本体。
为什么要有它?
- 多视图几何的本质就是“哪个深度下,投影后能对齐”。
- 代价体提供了所有深度的匹配证据,后续网络只需要在里面挑最可能的深度。
它是怎么构造出来的?
用日常比喻讲:
- 准备深度刻度尺 我们假设场景里东西可能离相机 1 米、2 米、3 米……一直到几十米。每一个可能的深度就是刻度尺上的一个格子。
- 像素假装放到那个深度 对参考图片的每个像素,我们假装它在“2 米远”这个位置上。然后用相机的几何关系,把它“投影”到其他视角里去,看看它在那些图里应该落在什么位置。
- 去源图片里找对应特征
在其他图片里找对应位置的特征,看看跟参考图这个像素的特征像不像。
- 如果像,说明这个深度假设对;
- 如果不像,说明这个深度假设错。
- 对多个视角求一个总结果 因为我们通常有好几张源图片,不同角度都会有证据。我们可以平均一下、取最小值,或者用权重把它们融合起来。得到的就是“这个像素在这个深度上的匹配好坏”。
- 重复所有深度 我们在所有深度假设上都做一次,就得到了一个厚厚的“分数本”。这个分数本在空间上有长宽(像素位置),在深度方向上有一层层的分数,所以整体看就是一个三维方块——这就是代价体。
数学/流程
- 对每张源图 InI_nIn,拿它的特征图 FnF_nFn。
- 对参照图的特征 FrF_rFr,在某个深度 ddd 下,把源图特征投影回参照相机坐标。
- 用相机内参、外参,把每个像素 (u,v) 的 3D 点投影到源图坐标。
- 双线性采样取对应的特征值。
- 这样在深度 ddd 下,你得到参照图和源图的一组“对齐特征”。
- 把它们和参照特征做相似性计算(点积/拼接+卷积)。
- 重复 D 个深度,把结果堆叠成一个
B × D × H × W的代价体。
代码里怎么做?
在官方代码中:
feature_volume.py和cost_volume.py里实现了这一步。FeatureVolumeManager/CostVolumeManager负责:- 对源图像特征做几何投影(warp)。
- 把 warped 特征和参照特征计算代价(点乘、MLP 或 cat+conv)。
- 最终输出:
Cost Volume,形状一般是B × D × H/4 × W/4。
Cost Volume Patchifier(成本体 Patch 化)
它是什么?
- 把代价体切成“补丁 (patch)”然后压缩/打包成 token,便于喂给 Transformer(或和 Reference Encoder 的 ViT 特征对齐)。
- 类似 ViT 的“Patch Embedding”,只是这里的输入是 3D 代价体,而不是 2D 图像。
👉 通俗比喻:代价体本身太大太稠密,好比一整个立方体;Patchifier 把它切成一块块小立方体,变成一串“代价 patch token”,再送给后续模块学习。
为什么需要:
- 3D 体维度太大,直接用CNN/Transformer很吃显存与算力;patch化能够:
降维、压缩冗余信息;
把它转成 Transformer 可以处理的 token 序列;
方便与 Reference Encoder 的 ViT token 融合。
图里成本体后面那几片“蓝色小砖块”就是被切出来的 Patch/token。
数学/流程
- 输入:
Cost Volume(B × D × H × W)。 - 用 3D 卷积 / 展平,把它划分为若干个 patch:
- 类似把体积分成
(patch_d × patch_h × patch_w)大小的小块。 - 每块展平成向量,经过线性层 → token。
- 类似把体积分成
- 输出:一组 token,形状
B × N_patches × C。- 其中 N_patches = (D/patch_d) × (H/patch_h) × (W/patch_w)。
- C 是 embedding 维度。
代码里怎么做?
- 在
view_agnostic_feature_volume.py、layers.py和networks.py里能看到PatchEmbed或者CostVolumePatchifier。 - 它一般用 Conv + Flatten 来做 patch embedding:
- Conv 负责滑动窗口切 patch;
- Flatten + Linear 映射到 token 空间。
- 最终输出的 token 会在 Mono/Multi Cue Combiner 阶段和 Reference Encoder 的 token 对齐融合。
总结(结合架构图)
- Feature Extractor → 得到所有图的特征图。
- Cost Volume → 在不同深度假设下,把源特征 warp 到参照图上,计算匹配代价,堆成 3D 体。
- Cost Volume Patchifier → 把代价体切成 patch,变成 token,送入后续的 Transformer(Mono/Multi Cue Combiner)和 Reference Encoder 融合。
👉 可以理解成:
- Cost Volume = “三维显微镜”,里面保存了“每个像素在不同深度下的匹配证据”。
- Patchifier = “代价体压缩机”,把这个庞大的三维显微镜快照打包成 Transformer 能吃的小片段。
Mono/Multi Cue Combiner(单/多线索组合器)
它是什么:
把两类信息融合:
Multi-view 几何线索(来自 Cost Volume Patchifier):告诉你“在不同深度下的匹配好坏”。
单目先验线索(来自 Reference Image Encoder):告诉你“语义/物体结构上哪个深度更合理”。
为什么需要?
- 仅靠几何 → 在纹理弱/遮挡区域容易出错。
- 仅靠单目 → 容易出现尺度歧义(比如不知道桌子具体有多大)。
- 两者结合,既精确又稳定。
👉 通俗比喻:
就像裁判判定结果:几何特征是“证据”,单目特征是“经验直觉”,两者结合才更靠谱。
数学/流程
- 输入:
- Patchified Cost Volume → token 序列(代表不同深度的几何匹配信息)。
- Reference Image Encoder 的 ViT token / 多尺度特征(代表单目先验)。
- 融合方法:
- 常见做法:在 Transformer block 内,把两组 token 在特定层进行特征拼接 + 线性投影 + 残差相加。
- MVSAnywhere 里,
ViTCVEncoder就在 ViT 的指定层,把几何 token 与单目 token 进行融合。
- 输出:
- 一个融合后的 token/feature 表示,既包含深度几何证据,又融合了单目语义。
- 可以 reshape 回到
B × C × H/4 × W/4的 2D feature map,供解码器使用。
代码里怎么做?
- 在
vit_modules.py→ViTCVEncoder:- 准备几何特征 token(由 Cost Volume Patchifier 输出)。
- 在 Transformer 的若干层,把单目 token(来自 Reference Encoder)过一层 MLP 投影后,加到几何 token 上。
- 在
depth_anything_blocks.py→DPTHead:- 会把融合后的 token 还原为空间特征,形成多尺度特征图。
Depth Decoder(深度解码器)
它是什么?
- 最后把融合后的特征 → 转换成一张实际的深度图。
- 本质上就是一个 上采样 + 卷积预测 的解码头。
为什么需要?
- 前面的输出还只是抽象的特征/代价 token,没有对应到实际的 像素深度值。
- Depth Decoder 负责恢复空间分辨率,并预测每个像素的深度(通常是连续值)。
数学/流程
- 输入:融合后的特征(一般分辨率是 H/4 × W/4)。
- 解码:
- 先通过几个卷积块 refine 特征;
- 用上采样(上采样 + skip connection)逐步恢复到原始分辨率;
- 最后一层卷积输出单通道深度图
D̂_r。
- 输出:一张和原图大小相同的深度估计。
代码里怎么做?
- 在
depth_anything_blocks.py的DPTHead里有解码逻辑:- 多尺度特征融合(skip connection + 上采样)。
- 逐级恢复分辨率。
- 输出深度预测(有时还会输出置信度或 mask)。
- 在
networks.py/networks_fast.py中,DepthDecoder通常是几个Conv2d + UpConv组合。
🔑 架构图结合讲解
在你给的图里:
- Feature Extractor → 提取几何匹配特征。
- Cost Volume + Patchifier → 构建并打包几何匹配证据。
- Reference Image Encoder → 给参照图提取单目/语义先验。
- Mono/Multi Cue Combiner → 把两条线索融合成一个整体特征表示。
- Depth Decoder → 把融合特征还原成实际深度图 D^r。
👉 可以理解为:
- Combiner = “把几何证据和语义先验搅拌在一起”
- Decoder = “把搅拌好的信息重新铺回图像,生成深度”
4、MVSAnywhere 最核心、最重大的缺陷
1. 单目分支带来的尺度不稳定
- 本质问题:单目模型(DepthAnything 等)只能提供“相对深度”,缺乏绝对度量能力。
- 后果:在几何约束不足或重叠度低的场景,整体深度会出现尺度偏差,影响三维重建精度。
- 比喻:就像顾问能告诉你“这栋楼很高”,但说不出“到底 5 米还是 10 米”,容易在关键任务里出错。
2. 计算开销过大,难以高效应用
- 本质问题:结构复杂(两阶段 cost volume + Transformer 融合 + 单目分支),显存和算力消耗显著。
- 后果:推理速度较慢,难以直接应用于实时或算力有限的场景(比如机器人、无人机在线重建)。
- 比喻:就像一个“豪华深度估计套餐”,营养丰富但很耗时耗钱,不适合在“快餐场景”里使用。
👉 总结:
MVSAnywhere 的 最大缺陷可以浓缩为一句话:
它虽然泛化能力强,但依赖单目分支导致尺度不准,同时模型过于庞大,实际部署效率不足。