MVSFormer(2022):结合预训练视觉Transformer的鲁棒MVS
1、研究背景与动机
1)问题:学到的图像特征在“镜面/纯色”区域很不靠谱
- CNN 的低层特征看得近(感受野小),缺少全局理解,遇到反光/纯色很迷茫;
- CNN 的高层特征又太“语义化”(更像分类需要),不够细腻匹配。即便用预训练 CNN(如 ResNet)也帮不了太多。
2)启发:ViT 天生看全局,可能是更好的特征“底座”
- CNN 更像“近视眼 + 放大镜”,细节好但全局弱;
- ViT 像“高台望远镜”,能把整幅图的关联看清楚;
- 把两者结合,可能既稳又细。
3)难点:ViT 不“耐分辨率变化”,直接拿来用会“水土不服”
4)动机与方案:用“预训练 ViT + FPN”学到更靠谱的 MVS 特征
- 目标:在反光/纯色/遮挡场景也能学到稳健特征,让点云更完整、误差更低,同时跨分辨率、跨数据集更能打。
- 做法思路:
- 用预训练的层次化 ViT(Twins)或冻结的 DINO ViT,与 FPN 简单相加融合,既有全局注意力又保留 CNN 细节;
- 设计高效多尺度训练(动态分辨率 + 梯度累积 + 合适的位置编码/CPE),让 ViT 能从 512~1280 的训练尺寸泛化到 1536/1920 的测试分辨率;
- 进一步从学习范式上统一“分类式深度(CE/argmax,置信度好)”与“回归式深度(soft-argmin,数值更准)”:**测试时引入“温度系数”**做期望深度,前面阶段偏“分类”、后面阶段偏“回归”,既稳又准。
5)一句话总结
以前 MVS 在“反光/纯色”地方容易“看不清”;MVSFormer 的动机是:把会看全局的预训练 ViT 接入特征端,再配上多尺度训练解决分辨率泛化,最后用温度策略把“分类的稳”和“回归的准”合起来,从而得到更鲁棒、可泛化、点云更干净的 MVS。
2、模型的核心创新点
- 把 ViT 当“高台望远镜”,FPN 当“放大镜”:ViT+FPN 互补特征
- 做法:用 预训练的 ViT(Twins 或 DINO)提供全局关系,再与 FPN 的细节纹理做简单相加融合,作为后续构成本体的特征。
- 直觉:CNN 细节强但“近视”,ViT 远视强看全局;两者合体,反光/纯色处也更能稳住匹配。
- 依据:作者明确用 FPN 为主干,并把 ViT 输出直接加到最高层特征上,得到从 1/8 到原分辨率的多尺度特征;Twins/DINO 的选择和特性也给出说明。
- 选对“可泛化”的 ViT:Twins 的层次注意力 + CPE 位置编码
- 做法:默认用 Twins 作为可训练主干,它既有局部分组注意力+全局下采样注意力,又用 CPE(卷积式位置编码),更能适配不同分辨率的训练/测试。
- 直觉:给 ViT 加点卷积“归纳偏置”,就不怕分辨率换来换去“水土不服”。
- 依据:Twins 的全局/局部设计与 CPE 对跨尺度的好处;作者解释为何选 Twins。
3) 多尺度训练策略:让模型从 512~1280 学到 1536/1920 也不慌
- 做法:对不同尺寸进行训练(含位置编码的调整/插值等),显著提升跨分辨率的鲁棒性;实验表明 Twins/DINO 版本都明显收益。
- 直觉:平时就“高强度变焦训练”,上场(高分辨率测试)才稳。
- 依据:多尺度训练能带来“可观提升”的消融结果;ResNet 不太吃这套。
4) 分阶段(coarse→fine)多尺度成本体 + 3D U-Net 正则
- 做法:沿经典 MVS 流水线构建多阶段成本体并用 3D U-Net 正则化,逐级细化深度概率(每阶段都输出像素级 3D 代价/概率体)。
- 直觉:先“粗找范围”,再“细抠细节”,每层都有三维上下文做“抹平/强化”。
- 依据:方法总览图与文字:多尺度构成本体、warp 特征、体积融合(带可见性权重)、3D 正则得到阶段性概率体。
5) 可见性加权的体积融合:让被遮挡的视图“少说两句”
- 做法:从多源视图融合成本体时,引入视图可见性权重,抑制遮挡/反光导致的不一致。
- 直觉:谁看得清,谁就多投票;看不清的别抢话。
- 依据:图 2(B) 中明确写到 “Volume Fusion with respective visibility (Eq.5)”。
6) “温度”统一回归派与分类派深度:稳与准都要
- 痛点:回归式(soft-argmin)数值更准但易给越界深度高置信;分类式(argmax+CE)置信图更可靠却易有量化误差。
- 做法:推理时在 softmax 前给代价体乘“温度系数 t”,t→∞ 近似分类、t→0 近似回归;或分阶段设不同 t,在同一模型里兼得稳与准(无需重训练)。
- 直觉:像“调味盐”一样调整分布“尖/钝”,一把网住两派优点。
- 依据:作者系统对比 REG/CLA 的性质与问题,并提出 temperature-based depth prediction 的公式与效果表。
7) 预训练真的有用:ViT 预训练与注意力图带来可泛化性
- 做法/现象:DINO 的无监督预训练 + 多裁剪策略使特征对环境、光照、分辨率更能泛化;Twins 预训练也明显下降整体误差。
- 直觉:让模型“先见世面再上岗”。
- 依据:DINO 的泛化描述;Twins 预训练的消融表(开启预训整体指标下降)。
小结(一句话)
MVSFormer = 预训练 ViT 的全局眼界 + FPN 的细节触感 + 多尺度体积与可见性融合 + “温度”统一深度推理。 它把“看得远、看得细、跨分辨率稳”和“稳准兼得的深度预测”放在一套简单有效的流水线上。 这正是它在反光/纯色/遮挡等“难场景”里更鲁棒的关键。
3、模型的网络结构
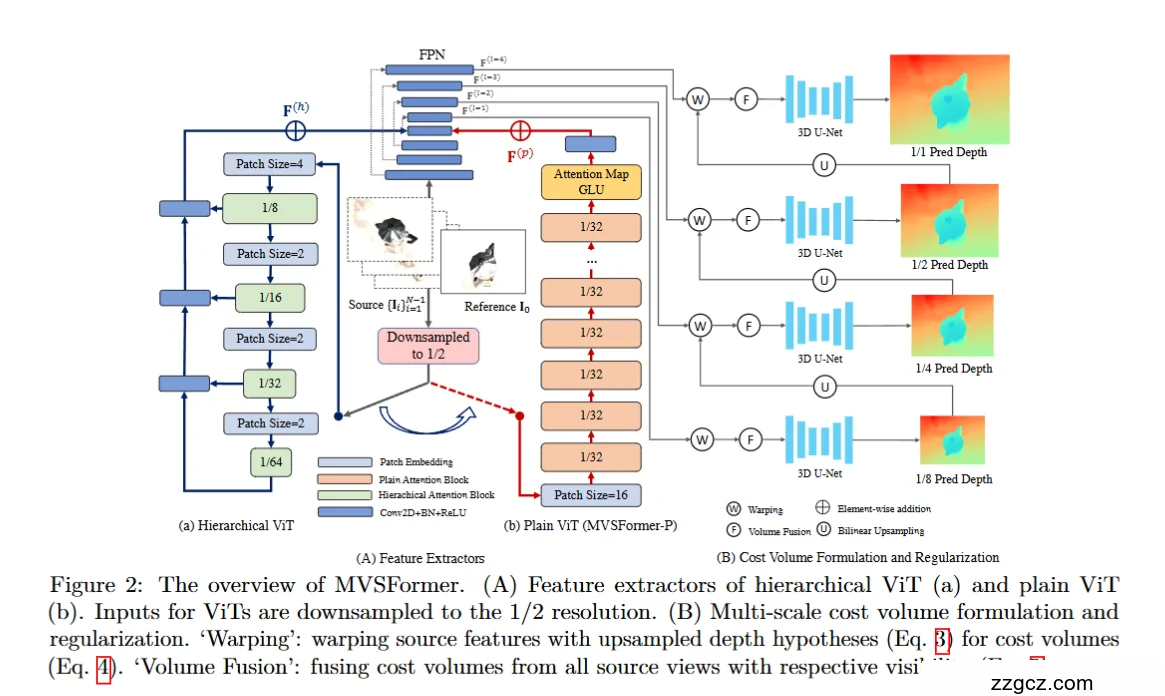
🧩 一、整体思路(先有个大框架)
区域
| 模块名
| 功能
| 比喻
|
左边
| 特征提取器(Feature Extractors)
| 看图提特征(包括层次化ViT和普通ViT)
| 相机的大脑——从图像中看出“深浅线索”
|
右边
| 成本体构建与正则化(Cost Volume + 3D U-Net)
| 拼成本体、融合、输出不同尺度的深度图
| 3D 画家——根据线索画出物体的立体形状
|
🧱 二、左半部分:Feature Extractor —— “看得远又看的细”
🌈 1️⃣ Hierarchical ViT:像一台“层层放大”的望远镜
- 它把输入图像分成小块(patch),每层做注意力计算,分辨率越来越低、感受野越来越大。
- 图中“Patch Size=4 → 2 → 2 → 2”代表不断下采样,形成 1/8、1/16、1/32、1/64 尺度的特征。
- 最浅的层看“局部细节”(边缘、纹理)
- 最深的层看“全局布局”(大形状、空间关系)
🔄 2️⃣ FPN(Feature Pyramid Network):多层特征的“拼接大师”
- ViT 各层提取的特征被送进 FPN。
- FPN 会从底层细节到高层语义逐层整合,得到多个分辨率的特征图(1/8、1/16、1/32、1/64)。
🔍 3️⃣ Attention Map + GLU:增强关注重点
- 在 FPN 输出后,增加一个 Attention Map 模块,再用 **GLU(门控线性单元)**调节通道重要性。
- 它帮助模型自动聚焦在关键区域(例如物体表面、边缘)。
类比:就像你用聚光灯照在目标上,让模型更“专注”地看对地方。
🧱 4️⃣ ViT + FPN 特征融合
- 最终,ViT 的全局特征与 FPN 的局部细节特征逐层相加(图中红色“⊕”),得到更强的空间感知特征。
- 这个特征会被送往右边的“成本体构建”部分。
ViT 给模型全局眼界,FPN 给模型锐利细节, 合起来就像一个“既能看全场又能看细节”的摄影大师。
🎨 三、右半部分:Cost Volume + Regularization —— “拼出三维形状”
🧱 1️⃣ 多尺度成本体构建(图中右侧的三条线)
- 1/8、1/4、1/2、1/1(即原图大小) 每个阶段都进行一遍“拼立体 → 修立体 → 出深度”。
💡 (1) Warping —— “把多张图在不同深度上对齐”
- “W” 图标表示 视图变换 (Warping)。
- 对于每个候选深度,把所有视图(Source Views)的特征根据相机参数投影到参考图的坐标系下。
类比: 你拿几张不同角度拍的照片,把它们投影在一块透明玻璃上。 当玻璃放在正确的深度时,图像重合得最好。
🔄 (2) Volume Fusion —— “整合所有视角”
- “F” 图标表示 融合 (Fusion)。
- 把来自不同相机的特征在体素上融合,同时利用可见性权重(Visibility)抑制遮挡。
类比: 如果某个角度被遮挡,那张相机的意见就“少算一点”, 看得清的相机“多说一点”。
🧠 (3) 3D U-Net Regularization —— “三维医生,抹平噪声”
- 构建好的成本体通过 3D U-Net 处理。
- 它能在三维空间上滤波,让表面更平滑、深度更连续。
类比:就像一个雕塑师,用三维砂纸打磨出干净的物体表面。
🎯 (4) 输出多尺度深度图
- 每个阶段都会输出一个深度图(1/8、1/4、1/2、1/1)。
- 后面的高分辨率阶段会用低分辨率结果做引导(上采样 + refinement)。
先粗后细,每一层都在“确认”深度,最后得到精致的高分辨率深度图。
⚙️ 四、网络的“流水线”总结(像工厂一样运作)
步骤
| 模块
| 功能
| 类比
|
①
| Hierarchical ViT
| 全局-局部特征提取
| 望远镜看世界
|
②
| FPN
| 多层次特征融合
| 混音调和器
|
③
| Warping
| 多视图对齐
| 把多张照片叠成3D层
|
④
| Volume Fusion
| 加权融合成本体
| 投票决定真实表面
|
⑤
| 3D U-Net
| 立体正则化
| 打磨雕塑表面
|
⑥
| 多尺度深度输出
| 渐进式细化
| 从粗糙到精细的立体画家
|
🧭 五、一句话总结
MVSFormer 的网络结构 = 预训练 ViT + FPN 做“聪明的眼睛”,多尺度成本体 + 3D U-Net 做“稳定的手”。
它看得远、看得细、能对齐多视角,还能自适应光照与分辨率变化,最终拼出更完整、更干净的三维世界。
4、模型的核心不足与未来改进方向
🧩 一、MVSFormer 的核心不足(通俗讲解版)
① 🧠 ViT 特征虽然“聪明”,但“贵”也“懒”
- 问题1:显存和算力开销大。 ViT 的注意力是“全连接”的,全图每个 patch 都要和其他 patch 计算关系。 当输入是 1K 或更高分辨率的图像时,显存和计算量暴涨,推理速度慢、显存吃不消。
- 🧠 打个比方: ViT 就像一个“八卦分析型的老板”——每个员工(patch)都得和每个其他员工说一遍话。 聪明是聪明,但会议太多太累。
- 问题2:特征偏平面、对局部几何不敏感。 虽然 ViT 看全局,但不像 CNN 那样擅长捕捉边缘、纹理等微结构。 在立体匹配这种需要精细像素对齐的任务中,容易在局部精度上吃亏。
② 🧱 成本体(Cost Volume)依然昂贵、内存爆炸
- MVSFormer 虽然引入了多尺度结构(1/8→1/1),但每一层都要构建三维成本体(H×W×D×C)。 这在高分辨率时非常占 GPU 内存,尤其是在 1/1 级别的 fine stage。 即便使用了 coarse-to-fine 策略,总体计算成本依旧不轻。
- 💬 类比: 它像一个“拼三维积木”的工人,每一层都要把整栋楼重新堆一次。 有时候确实太累、太耗砖头(显存)。
③ 🧭 泛化虽强,但仍受“预训练域”的限制
- MVSFormer 借助 ViT(尤其是 DINO/Twins)获得了较好的跨场景泛化, 但 预训练数据多是 ImageNet 类自然图像,并非针对“多视图几何”的分布。 所以当遇到 极端视角、室内杂乱结构 时,模型仍会出现错深、漏重建。
- ⚠️ 简单说: ViT 的“眼睛很聪明”,但它“没见过这种几何环境”,在三维场景下还是容易犯迷糊。
④ 🎯 温度深度融合虽然巧妙,但仍需人工调参
- MVSFormer 的 “Temperature-based depth prediction” 是个聪明的点子: 通过调整 softmax 温度,在“回归式”与“分类式”深度之间取中庸。 但问题是:温度 t 需要手工选择,不同数据集甚至不同场景最优值不一样。
- 🔧 换句话说: 模型还不能自己判断“我现在该偏分类一点,还是回归一点”, 这让部署时还得“试温度”,不够自动化。
⑤ 🔄 多尺度结构的层间衔接仍然是“手工拼”
- 当前 MVSFormer 的多尺度结构是“固定金字塔”,从 1/8 到 1/1。 每一层之间是简单的上采样 + 拼接,而不是“自适应”或“动态”层间传递。 这意味着模型可能无法根据场景复杂度动态分配计算资源。
- 💡 举个例子: 如果场景很简单(比如纯平面),其实不需要那么多层 refinement; 但模型还是机械地走完所有层,浪费时间。
🚀 二、未来改进方向(研究者可以怎么补)
✅ ① 用 轻量化 Transformer 或混合架构 降算力
- 替代大 ViT 的方向包括:
- Swin Transformer / MobileViT / ConvNeXt-V2:局部注意力+滑动窗口,保留全局性同时降显存。
- Hybrid CNN-Transformer Backbone:前几层 CNN 负责低级特征,ViT 只在高层建全局关系。
- 这样既保留了 ViT 的全局“聪明”,又能减负显存。
✅ ② 成本体的压缩与自适应采样
- 可以借鉴 PatchMatchNet、ACMH、MVSNeRF 的思路:
- 用稀疏/自适应深度采样代替固定深度层;
- 用轻量体积表示(如 occupancy grid)减少内存;
- 或者用 Transformer-based matching,直接做多视图相关性建模,不再显式建体。
趋势:从“密集体积” → “稀疏几何” → “隐式匹配”。
✅ ③ 针对几何的预训练或跨模态预训练
- 构造大规模多视图几何预训练数据集(如 DTU + Tanks & Temples + synthetic datasets)。
- 或者用 自监督几何预训练(例如结合深度一致性损失、视角重建损失),让模型学习“立体几何 priors”。
✅ ④ 自动温度调节或混合深度预测策略
- 用一个小网络预测“最优温度 t”;
- 或者引入“双头结构”:一个头分类式、一个头回归式,最后自适应融合。
这样模型能自己在“稳”和“准”之间找到平衡,不用人手调参。
✅ ⑤ 动态多尺度与分层蒸馏
- 让模型根据场景复杂度自适应决定 refinement 阶段数;
- 或者把高层的几何知识蒸馏给低层网络,减少推理阶段重复计算。
未来的 MVSFormer++ 已经部分探索这条路,更多使用层间 cross-scale transformer 来动态传递信息。
🧭 三、一句话总结
MVSFormer 的优点是用 ViT 看得更远、泛化更强; 缺点是算力高、几何偏弱、温度调参麻烦; 改进方向是走向轻量化、自适应化、几何感知化。
MVSFormer 已经是“眼光最聪明的摄影师”, 接下来要让他“拍得更快、更稳、更懂几何”。