MVSNeRF(2021):从多视角立体视觉中快速重建可泛化的辐射场,将 MVS 融入神经辐射场重建
1、研究背景与动机
🌍 一、背景:NeRF 很“真”,但太慢了!
🌈 效果惊人!NeRF 可以渲出几乎“照片级”的新视角,就像电影特效一样真实!
❌ 太!慢!了!
- NeRF 每训练一个新场景,都要从零开始。
- 每个场景要优化几十分钟甚至几小时,就像每次拍电影都要重建一整个城市。
- 所以它很“酷”,但一点都不“实用”。
✅ 速度快了,但 ❌ 场景一换、角度一变,生成的画面就“穿帮”。
🔍 二、启发:MVS 是个“几何天才”
- 给它几张不同角度的照片,
- 它能算出每个像素对应的深度(离相机多远),
- 从而恢复整个场景的三维形状。
- 它会在不同深度上“平面扫描”场景,
- 比较每个深度下多张图像是否一致,
- 构建一个叫 成本体(Cost Volume) 的 3D 数据立方体,
- 再用 3D 卷积神经网络去“看懂”整个立体结构。
🧠 简单来说: MVS = “几何感知超强,但只会画线条(深度图)”; NeRF = “能画出彩色世界,但没几何概念”。
💡 三、核心动机:让“聪明的 MVS”教“会画画的 NeRF”
“如果我们能让 NeRF 像 MVS 一样理解几何, 又能保留 NeRF 的渲染能力,那岂不是两全其美?”
⚙️ 四、MVSNeRF 的核心思路(简单三步)
① 用 MVS 构建一个“几何透视盒”
- 把多张图像的特征对齐到不同深度的平面上(想象你用不同焦距拍同一个场景)。
- 每一层平面表示一个候选深度。
- 比较多视图间差异后,得到一个 3D 成本体(cost volume)。
📦 就像搭了一个三维积木,每块积木都代表“这个位置有多可能是表面”。
② 把成本体变成“神经积木”(神经编码体)
- 用 3D 卷积神经网络(3D CNN)把这个积木体变成一个神经特征体(encoding volume)。
- 它不仅知道形状(几何),还学到颜色与纹理(外观)。
- 再用一个 MLP(全连接网络)去查询任意 3D 点的:
- 密度 σ(这个点是不是实物);
- 颜色 r(这个点发出的光)。
🔮 就像给每个积木块装上了灯泡,能在不同方向发出颜色光。
③ 用可微体渲染训练整个网络
- 沿着每个像素的视线,把这些小灯泡的光加起来,生成最终的图像(体渲染)。
- 再和真实照片比对,让网络自己调整参数。
🎥 这一步就像导演对比镜头和照片,不断修正演员的站位与灯光。
- 理解三维形状(靠 MVS),
- 渲染逼真图像(靠 NeRF)。
🚀 五、为什么这很厉害
目标
| 传统 NeRF
| MVSNeRF
|
训练时间
| 每个场景几小时
| 几分钟甚至实时
|
输入图像数
| 通常 50+
| 少至 3 张即可
|
泛化能力
| 每景重新学
| 可跨场景直接推理
|
精度
| 高,但慢
| 略低或相当,但超快
|
✅ MVSNeRF 就像一个“上过几何课的 NeRF”:
- MVS 提供 空间理解(知道物体在哪儿);
- NeRF 负责 光线渲染(知道它看起来怎样);
- 两者结合,让网络既“看得懂”又“画得快”。
🧭 六、一句话总结
MVSNeRF 就是让“擅长测量的 MVS”教“擅长画画的 NeRF”变聪明。
它让 NeRF 不再像老艺术家那样一个场景慢慢琢磨, 而像一位“见多识广的速写大师”—— 看几张照片,几分钟就能画出逼真的三维世界。
🌟 一句话先概括:
MVSNeRF = 让 NeRF 长了“三维几何眼睛”的版本。
2、模型的核心创新点(通俗易懂版)
核心创新点一:用 MVS 的方式来“看三维世界”
🧱(1)引入了“平面扫描成本体”——让 NeRF 真的看见深度
“这像素看起来亮一点,可能近一点?暗一点,可能远一点?” —— 完全靠猜。
- 如果玻璃板放在“正确的深度”,这些图像的内容会重合得非常好(几乎一模一样);
- 如果放错深度,图像内容就对不上。
📦 你可以把这个成本体想象成一个立体雷达地图: 每个点的值表示——“这里可能是物体表面吗?” 越小的代价(cost),越可能是真实表面。
⚙️ 核心创新点二:把成本体“变聪明”成一个神经体(Neural Volume)
🧬(2)用 3D CNN 把成本体转化为“神经编码体”
- 它能发现连续的表面、物体轮廓、平滑的深度变化;
- 同时还能结合多视角的图像特征,学习颜色和纹理。
🔮 比喻一下: 成本体就像原始的 3D 积木图, 而 3D CNN 就像在积木上“雕刻出”形状和纹理, 变成一个带有“记忆”的三维世界快照。
- 它是不是实物(几何/密度)
- 它是什么颜色(外观/纹理)
🔥 核心创新点三:把神经体积塞进 NeRF 的“体渲染管道”
🎥(3)在任意 3D 点用 MLP 学颜色 + 密度,并做体渲染
“这个点的特征是什么?它发出的光是什么颜色?它是实心还是透明?”
- 对每条射线(也就是图像中一个像素的光线)进行采样;
- 在编码体中插值得到对应点的特征;
- 把这些特征喂进一个小的 MLP 网络,输出:
- 密度 σ(sigma):这个点是不是物体;
- 颜色 r(radiance):它发出的光是什么;
- 然后用 NeRF 的体渲染公式沿射线累积颜色,生成一张新图。
🎨 比喻: 就像你拿着一束激光(光线),从摄像机发出穿过空气。 每遇到一个体素小块,你问它:“你亮不亮?什么颜色?” 把所有答案按光的传播规律加起来,就得到了图像像素的颜色。
⚡ 核心创新点四:高效泛化 + 快速微调(实用性爆棚)
- 给它三张新场景的图片,它就能直接生成 3D 场景;
- 想更精一点?再用几分钟微调就行(传统 NeRF 要几个小时!)。
🚀 比喻: 普通 NeRF 就像一个“画肖像的画家”,每遇到新模特都要重画几小时; 而 MVSNeRF 就像一个“速写大师”,看几张照片就能迅速画出 3D 像。
🔍 五、四个创新点总结(小表格)
创新点
| 解决的问题
| 类比解释
|
✅ 1. 引入 MVS 成本体
| NeRF 不懂几何
| 给 NeRF 一双能“测距”的眼睛
|
✅ 2. 3D CNN 编码体
| 代价体只是原始几何
| 把几何立体变成能理解形状和颜色的“神经积木”
|
✅ 3. 与体渲染结合
| MVS 不能生成真实图像
| 把几何体塞进 NeRF 的渲染管道,直接出图
|
✅ 4. 快速泛化 + 微调
| NeRF 每景都要重训
| 让模型像熟练画家一样快速适应新场景
|
🧭 一句话总结
MVSNeRF 把 NeRF 从“艺术生”变成了“理工生”: 它既会算空间(几何),又会画光影(渲染), 一次学会,多场景通用,几分钟就能重建出一个逼真的三维世界。
3、模型的网络结构与工作原理
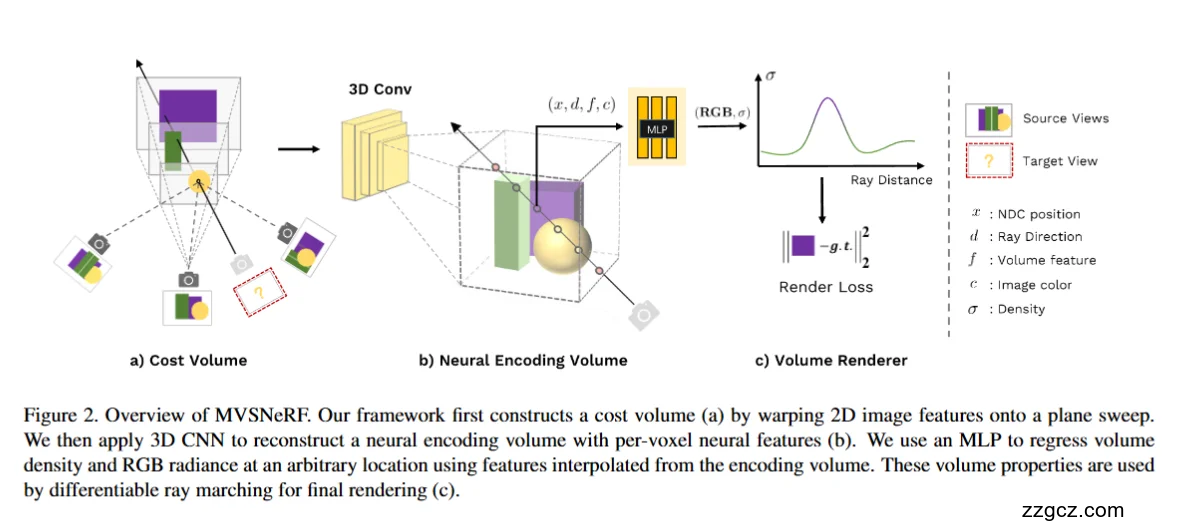
🧩 一、整体思路概览
阶段
| 图示模块
| 主要工作
| 类比理解
|
①
| a) Cost Volume
| 用多张照片拼出三维骨架
| “摄影测距”,建出立体草图
|
②
| b) Neural Encoding Volume
| 让骨架有“生命”,带上纹理和特征
| “神经积木工厂”,把结构变成可理解的体积
|
③
| c) Volume Renderer
| 用光线渲染成像
| “相机拍摄”,输出真实图像
|
🧱 二、阶段一:Cost Volume(成本体)——“MVS 几何眼睛”
🪞1️⃣ 多视图输入
- 模型输入多张从不同角度拍摄的图像(图中底部的三台相机 📷)。
- 每个相机看到的物体角度不一样,提供不同的深度线索。
🧩2️⃣ 平面扫描(Plane Sweep)
- 模型在空间中设定若干个“假设深度平面”,就像在相机前方摆几块透明玻璃板。
- 然后它把所有照片的特征投影(warp)到这些平面上—— 如果某块平面正好在物体表面的位置,多张图像在这一层的纹理就会对齐得很好。
💡比喻: 想象你拿几张不同角度的照片叠在一起,一层层滑动, 当叠得最清晰的那一层,就是物体所在的深度。
📦3️⃣ 计算一致性得到 Cost Volume
- 在每个平面上比较这些对齐后的特征,看它们是否相似(通常用方差或相关性)。
- 把这些“相似度”沿深度方向堆叠,就得到一个三维立体的数据块——成本体 (Cost Volume)。
📦 成本体的每个格子(体素)就表示: “这个位置有多可能是物体表面?” 值越小(代价低),说明匹配得越好。
🔮 三、阶段二:Neural Encoding Volume(神经编码体)——“特征加工厂”
🧠1️⃣ 用 3D CNN 提取空间特征
- 成本体输入一个 3D 卷积网络 (3D ConvNet)。
- 它能在三维空间上提取连续的结构模式:平滑表面、凹凸边缘、空间一致性。
- 这样输出的结果就不只是“几何概率”,而是神经编码体(Neural Encoding Volume)—— 每个体素都包含了几何 + 颜色 + 语义等丰富特征。
🧩比喻: 成本体像素描草图,而 3D CNN 就像给它上色、打光、加阴影, 让模型“感受到立体的空间感”。
💡2️⃣ 生成连续可查询的体积特征
🎨 四、阶段三:Volume Renderer(体渲染器)——“NeRF 渲染画家”
☄️1️⃣ 沿射线采样空间点
- 对于目标视角(Target View),我们从相机发出一条条射线(每条射线对应图像中的一个像素)。
- 在射线穿过空间时,模型会在多个点上采样。
比喻:就像光线从相机镜头穿过空气,遇到物体时会被反射或吸收。
🧠2️⃣ MLP 回归密度与颜色
- 每个采样点的特征会从神经体积中“插值取出”;
- 然后输入一个小型的 MLP 网络,预测:
- σ(sigma):密度(这个点是不是实心的?)
- RGB:这个点发出的颜色。
🎯 sigma 越大,表示这个点更“实”;越小,表示空气或透明区域。
☀️3️⃣ 体渲染(Volume Rendering)
- 根据 NeRF 的体渲染公式,把这些点的密度和颜色沿射线方向整合起来。
- 模型模拟光线的吸收和散射,最终得到这一条射线的颜色,也就是最终图像的一个像素。
💡通俗说: “每条光线问一路上每个点:‘你多亮?你什么颜色?’ 然后把这些回答按物理规律叠加成画面。”
⚙️4️⃣ 训练(Render Loss)
- 把渲染出的图像和真实的目标图像对比,计算重建误差(Render Loss)。
- 这个误差会反向传播到整个网络中,让:
- 成本体学到更好的几何;
- 编码体学到更丰富的特征;
- 渲染器输出更真实的图像。
🧩 五、完整流程总结(生活化版本)
步骤
| 模块
| 比喻
|
🏗️ Step1
| Cost Volume
| 用几张照片测距 → 建出立体骨架
|
🎨 Step2
| Neural Encoding Volume
| 在骨架上贴上纹理、色彩、材质
|
💡 Step3
| Volume Renderer
| 打灯光、拍摄成像,生成新角度的照片
|
✅ 六、模型结构优点总结
优点
| 原因
|
几何理解更强
| 有 MVS 的深度一致性(平面扫描 + 成本体)
|
生成更快
| 只需前向计算,不用每个场景重新优化
|
可泛化
| 几何编码体在不同场景中通用
|
渲染质量高
| 结合 NeRF 的体渲染,输出光照自然的图像
|
4、模型的核心不足与未来改进方向(通俗易懂版)
🧠 一、先回顾:MVSNeRF 的核心思路
MVSNeRF = “会几何的 NeRF” 它用 MVS 的成本体理解空间结构,再用 NeRF 的体渲染生成真实图像。 优点是:速度快、可泛化、效果真。
⚠️ 二、核心不足(四大问题)
🧱 1️⃣ 成本体(Cost Volume)仍然受限于深度采样精度
- MVSNeRF 虽然用平面扫描来构造几何,但它仍然需要在离散的深度平面上采样(比如 64 层或 128 层)。
- 如果深度层数太少,就会出现“深度不够精”或“表面模糊”;
- 如果层数太多,计算量就会飙升,效率下降。
🧩 比喻: 你用 10 层透明玻璃看一个雕像,只能粗略看到轮廓; 想看清细节得加到 100 层,但那样太费时间。
- 使用 自适应深度采样(Adaptive Depth Sampling),在表面附近采样更密;
- 或者用 层级金字塔式成本体(Hierarchical Cost Volume),逐层细化。 👉 类似思路后来被 MVSNeRF++、CVP-MVSNeRF 等模型采用。
🎨 2️⃣ 渲染细节仍不如原始 NeRF 精细
- 虽然 MVSNeRF 速度快,但它的渲染细节(尤其在高频纹理、反射表面、细小结构)略逊于原始 NeRF。
- 原因是:
- 特征来自编码体(低分辨率 3D 网格),空间连续性不足;
- MLP 的容量较小,表达力有限。
🧠 比喻: 就像把一张高清照片打印在略微粗糙的画布上, 远看很好,但近看能看到颗粒。
- 使用更高分辨率或多尺度的特征体(multi-scale feature volume);
- 融合 图像空间细节修复网络(RefineNet);
- 或结合 高频显式表征(hash encoding、tri-plane、implicit grid) 来提升局部精度。
🌍 3️⃣ 光照一致性与外观建模较弱
- MVSNeRF 的主要监督是“图像重建损失”,它并不显式区分光照变化与物体表面颜色。
- 当输入图像光照角度不同或有反射时,模型会混淆“亮度变化”与“几何差异”。
- 结果可能导致渲染的颜色不稳定、明暗突变。
💡 比喻: 如果你白天拍一张、晚上拍一张,MVSNeRF 可能会以为“物体形状变了”, 而不是“灯光变了”。
- 显式建模 光照与反射(如 NeuS、NeRFactor、Relightable NeRF);
- 在网络中加入 BRDF(双向反射分布函数)建模模块, 让模型区分“材质”和“光照”。
🕳️ 4️⃣ 编码体体积庞大,难以处理大场景
- Neural Encoding Volume 是 3D 卷积生成的, 对于大场景(如街景、室内房间), 三维体素分辨率太高会导致显存占用极大(几 GB 级)。
🧱 比喻: 你用乐高搭房子时,积木越小越精细,但也越费料。
- 使用稀疏体积表示(Sparse Voxel / Octree / Hash Encoding);
- 或者分块渲染(Tiled Rendering),只渲染相机可见部分;
- 后续的 MVSNeRF++、GeoNeRF、Mip-NeRF 系列在这方面都有改进。
🚀 三、未来的改进创新方向
🧩 方向 1:更高效的几何建模(Cost Volume → Implicit Geometry)
- 把深度场直接作为连续函数学习;
- 通过 MLP 或 hash-grid 编码几何关系;
- 不再需要显式 3D 体积,节省内存。
🌈 方向 2:多模态融合与可控渲染
- 融入光照、法线、材质等额外监督;
- 实现可控渲染(Relightable NeRF、Intrinsic NeRF)。
比如:能“调灯光、改材质”,而不仅仅生成原始照片。
🧭 方向 3:跨场景、跨任务泛化
- 让模型在新环境(例如街景、室内、无人机视角)下也能稳定重建;
- 可结合大规模预训练(类似 NeRF-GAN、PixelNeRF++、Vision-Language NeRF)。
⚙️ 方向 4:结合稀疏点云 / 激光雷达
- 把 MVSNeRF 与激光雷达(LiDAR)或深度相机信息结合, 在自动驾驶、机器人导航等实际场景中更稳定。
这样能解决“少视图 + 复杂几何”问题。