MVSNet (2018):非结构化多视角立体视觉的深度推断,第一个端到端 MVS深度估计模型
导出时间:2025/11/24 08:50:52
1、背景:为什么要研究 MVS(多视角立体视觉)?
想象一下:你去旅游,拍了一堆照片。你能从这些二维照片中重建出一个三维的场景吗?
这就是 多视角立体视觉(Multi-View Stereo, MVS) 要解决的问题 —— 用多张重叠的照片,推算出场景里每个点的深度,得到 3D 模型。
传统方法的问题
传统 MVS 方法依赖两类关键步骤:
- 人工设计的匹配规则
- 要解决的问题:两张(或多张)照片里,哪个像素点对应同一个真实世界的点?
- 传统做法:
- 人为规定一个“相似度公式”。
- 比如:拿一小块区域(像素块),去另一张图里滑动比对,看哪块最像。
- 常用的“像不像”度量方式有:
- 相关性 (correlation):像比较两段音乐的波形,看节奏是不是一致。
- 互信息 (mutual information):更高级的统计度量,看两个信号共享多少信息。
👉 比喻:
想象你手里有两张班级合照,你要找到“这张照片里的小明,对应另一张照片里的哪个人”。
传统方法就是:
- 看小明的头发、衣服、脸型,算个相似度分数;
- 再在另一张照片里逐个比对,找到最像的。
- 工程化的后处理(以 SGM 为例)
- 要解决的问题:前一步得到的匹配结果常常会“乱糟糟”,比如有噪声、局部错误。
- 传统做法:用一些工程规则,让结果更平滑、连续。
- 半全局匹配 (Semi-Global Matching, SGM):
- 沿着不同方向(水平、垂直、对角线)检查深度结果,强迫它们不要跳来跳去,尽量保持平滑。
- 但也允许在边缘处(比如物体边界)出现明显变化。
- 半全局匹配 (Semi-Global Matching, SGM):
但是传统方法有一些明显缺点:
- 低纹理区域:比如一面白墙,像素太相似,很难知道哪个点对应哪个点。
- 反光/透明区域:比如玻璃、水面,光线不规则反射,导致匹配失败。
- 不完整重建:结果往往有“缺口”,尤其在复杂场景里。
结论:传统方法在“理想条件下”可以用,但在真实世界的场景中,常常不够稳健。
2、动机:为什么引入深度学习?
2.1、什么是语义信息
深度学习的 CNN 在图像识别、目标检测上已经表现惊人。那是不是也可以用在三维重建上?
- 优势:神经网络能学习“语义信息”,可以弥补传统方法在反光/低纹理区域的缺陷。
理解“语义信息”,是从“低级图像特征”到“高级理解”的跨越。
- 什么是“低级特征”?
计算机一开始看到图像,只能看像素值(RGB),或者像素的简单变化:
- 边缘(亮暗变化)
- 纹理(重复花纹)
- 颜色块
这些叫 低级特征,没有真正的“意义”。 👉 举例:一面白墙,对计算机来说全是相似的像素,没有什么区别。
- 什么是“语义信息”?
“语义” = 含义、理解。 当神经网络训练后,它不只是看“像素长得像不像”,而是学会了一些场景规律和物体常识。
- 墙壁 → 通常是大平面,即使没有纹理,也能推测出深度连续。
- 地面 → 一般在图像下方,深度逐渐增加。
- 天空 → 通常在最远处,应该有“无限远”深度。
- 物体边界 → 桌子和背景之间,深度会突然变化。
这些规律就是 语义信息:和“物体类别”、“场景结构”相关的高层理解。
👉 比喻:
- 低级特征:看见“几根黑线、一些灰块”。
- 语义信息:能认出来“这是人的眼睛”,“这是墙壁”。
- 为什么语义信息重要?
在深度估计里,很多地方仅靠像素匹配是没法解开的:
- 白墙:像素都一样,传统方法不知道墙有多远。
- 玻璃:像素花哨,但其实背后有个简单平面。
- 光照变化:同一个物体在不同照片中亮度不同,低级特征会被迷惑。
但如果网络学到了语义先验:
- 知道“这是墙 → 应该是个平面”
- 知道“这是地面 → 深度要逐渐变化”
- 知道“这是天空 → 应该非常远”
就能补足低级信息的不足。
2.2、从双目到多视角,MVSNet 要解决什么?
- 在 双目立体视觉(两张图)里,深度学习已经超过传统方法,做出了像 GCNet 这样的强基线。
- 但是,从“双目”推广到“多视角”就更困难:
- 双目时,图像都被校正了,问题只剩下“一维视差”;
- 多视角时,相机位置任意,几何关系复杂,没法直接套用双目的方法。
在 MVS 出现深度学习之前,也有尝试:
- SurfaceNet (2017):把所有图像颜色和相机信息放到三维体素格子里,用 CNN 学习 → 但内存太大,只能处理很小的场景。
- LSM (2017):用可微投影生成体积,也受限于 3D 网格,难以扩展到大场景。
于是,研究者提出:
👉 能不能设计一个方法,既能 利用深度学习的强大特征提取能力,又能 高效适配多视角的复杂几何,而且还能 大规模扩展?
这就是 MVSNet (ECCV 2018) 的出发点。
记住一句话:MVSNet 是第一个真正把「多视角几何」和「深度学习」结合在一起,做到端到端预测深度图的网络。
3、MVSNet 的三大核心创新
可微单应性(Differentiable Homography)
- 问题:多视角几何里,我们需要把不同相机拍摄的图像对齐到同一个“参考相机视角”,才能比较像素是否一致。
- 传统方法:这是一个几何投影过程,不能直接放进神经网络里学习。
- MVSNet 创新:提出了可微单应性变换,把几何投影写成一个可以反向传播的操作。
- 这样网络能自动学会“如何在不同相机之间对齐”。
👉 可微单应性 = 把“相机视角变换”写进网络里,变成一个能学习、能调优的模块。
构造 3D 代价体(Cost Volume)
- 双目相机:两台相机是并排放的(有一个固定基线),只需要在一条水平线上“左移右移”找匹配(就是一维搜索)。
- 多视角相机:相机不一定是并排的,可以随便拍(正面、侧面、斜着…),这时,同一个物体在不同相机里的投影位置,并不会只是在水平线上移动,而是会在 整张图上乱跑。
所以:
- 你不能再只在“一维的水平线”上找匹配;
- 必须考虑 连续的三维深度空间:物体可能在任意深度位置。
- 通俗说:你要在 很多个深度假设 上尝试,把别的相机的图像投影到这个深度,再去比较是否对齐。
✅ 总结:MVS匹配问题是连续的,需要在三维空间(深度假设)中搜索。
🧩 MVSNet 的思路
MVSNet 说:既然不知道物体到底多远,就干脆 把可能的深度都试一遍。
- 假设我们把场景划分成 D 个深度层(比如从 1 米到 10 米,每隔 1cm 一层)。
- 对于每个深度层,把所有相机的图像都“投影”到参考相机的视角。
- 如果这个深度是假设正确的 → 投影后的图像应该高度对齐;
- 如果深度是假设错的 → 投影后会模糊/错位。
这样,就能在每个深度层收集一组“匹配分数”。
所有这些层堆起来,就得到一个 3D 代价体 (Cost Volume)。
👓 通俗比喻
想象你戴上了一副神奇的 虚拟眼镜:
- 这副眼镜有一个“深度旋钮”。
- 每转动一次旋钮,相当于假设场景里所有东西都在这个深度。
- 系统就会把多张相机拍的图像在这个深度下对齐,给你看效果。
👉 结果:
- 如果对齐后,多个相机的图像都非常一致 → 那说明这个深度可能就是正确的。
- 如果看上去东倒西歪 → 那个深度假设就是错的。
把所有可能的深度都试一遍,相当于你就得到了一本“厚厚的对齐相册” 📖。
这本相册里,每一页就是一个深度层,翻到哪一页图像最清晰,就是正确深度。
这本厚相册 = 3D 代价体。
✅ 一句话总结: 3D 代价体就是“把所有可能的深度都试一遍,把结果堆成一大本厚相册/仓库”,网络后面会从里面挑出哪一层最对,从而得到正确的深度图。
3D 卷积正则化(3D CNN Regularization)
- 问题:代价体往往很嘈杂(有错误匹配、遮挡干扰)。
- MVSNet 创新:用 3D CNN 在 (Depth × Height × Width) 空间中进行特征聚合和正则化,学习到“哪些匹配是可靠的”。
- 最终输出一个概率分布 (probability volume),再通过“期望值”方式得到深度图。
👉 比喻:
就像你收集了一堆同学的意见(代价体),里面有噪声;然后请一个有经验的老师(3D CNN)来综合判断,过滤掉不靠谱的回答,给出最合理的结论。
✅ 总结一句话
MVSNet 的创新点 = 「可微几何投影」+「深度假设代价体」+「3D CNN 正则化」,
这使得它成为第一个端到端的多视角深度学习框架,也奠定了后续 CasMVSNet、PatchmatchNet 等改进的基础。
4、MVSNet 的模型网络结构
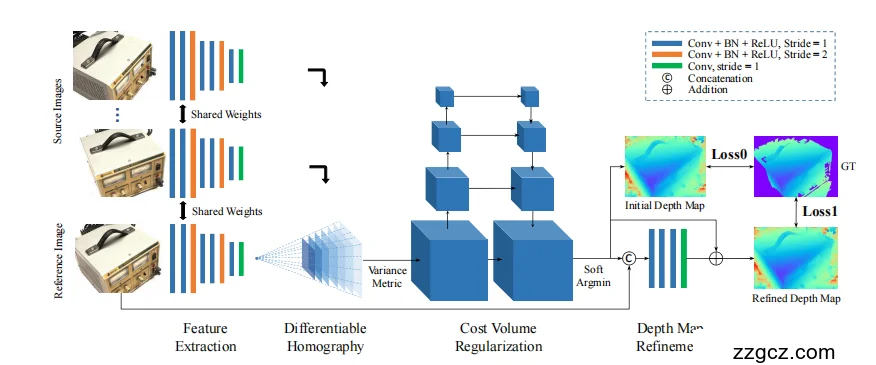
🖼️ 总览
从左到右,可以分成 4 大步骤:
- 特征提取 (Feature Extraction)
- 可微单应性 (Differentiable Homography)
- 代价体构建 & 正则化 (Cost Volume Regularization)
- 深度图预测与优化 (Depth Map Inference & Refinement)
1️⃣ 特征提取 (Feature Extraction)
- 左边是多张图像:一张 参考图像(Reference Image),几张 源图像(Source Images)。
- 每张图都经过同一个 CNN(共享权重 Shared Weights),提取出特征图。
- 这些特征比原始像素更鲁棒,可以包含纹理、边缘、语义信息。
👉 可以理解为:
图像 → “高维描述子”,网络学会“什么特征点更容易匹配”。
2️⃣ 可微单应性 (Differentiable Homography)
- 把源图像的特征,通过相机参数 + 不同深度假设,投影到参考相机坐标系。
- 每个深度假设都会得到一组对齐后的特征图。
- 这样,在参考图像的视角下,我们能比较“在某个深度下,不同相机看到的东西是否一致”。
👉 就好比:
“假设桌子在 3 米远,把所有相机的画面对齐到 3 米层;再假设桌子在 5 米远,对齐到 5 米层……一层层试。”
3️⃣ 代价体构建 & 正则化 (Cost Volume Regularization)
- 上一步得到的对齐特征,按深度堆叠起来 → 代价体 (Cost Volume)。
- 每个 voxel(体素单元)表示在某个深度下的匹配一致性。
- 然后用 3D CNN 在这个三维体 (D×H×W) 上卷积,进行“正则化”:
- 消除噪声
- 聚合上下文信息
- 学习哪些深度假设更可信
👉 类比:
“建了一本厚厚的相册,每一页是一个深度假设。3D CNN 就像老师,翻整本相册,挑出最合理的深度层。”
4️⃣ 深度图预测与优化 (Depth Map Inference & Refinement)
- Soft Argmin:
- 3D CNN 输出一个 概率分布(每个像素在各个深度的概率)。
- 用“加权平均”得到初步深度图(Initial Depth Map)。
- Depth Refinement:
- 把初步深度图和原始图像特征结合,再用 2D CNN 做细化 → 得到更平滑、边缘更清晰的最终深度图。
👉 训练时:
- Loss0:监督初步深度图。
- Loss1:监督优化后的深度图。
- GT:Ground Truth 深度。
✅ 一句话总结
MVSNet 整个 pipeline 就是:
图像 → CNN 特征 → 可微投影到不同深度 → 堆成代价体 → 3D CNN 选最可能的深度 → Soft Argmin 得初步深度 → Refinement 得更清晰的深度图。
5、MVSNet 的重大缺点
虽然 MVSNet 开创了端到端学习的 MVS,但也有不少硬伤:
- 显存/计算开销巨大
- 代价体 (D × H × W) 非常庞大,D = 深度层数,H/W = 图像分辨率。
- 如果图像大、深度范围大,代价体就会爆炸(几百 MB~几 GB 显存)。
- 限制了 MVSNet 只能在较小分辨率下工作,无法大规模工程应用。
- 深度采样固定、不灵活
- 它用均匀采样来假设深度范围。
- 但是:
- 如果场景很大,需要很多层(D),才能覆盖所有深度 → 内存更爆炸。
- 如果场景很小,采样又浪费。
- 所以在大场景(室外/城市级别)效果不佳。
- 推理速度慢
- 3D CNN 在整个代价体上卷积,计算代价非常大。
- 不适合实时应用(如 AR/VR、机器人导航)。
- 对输入相机姿态敏感
- 假设相机位姿很准,但在实际 SfM/SLAM 提供的姿态有误差时,鲁棒性不足。
6、后续基于 MVSNet 的改进模型
研究者们针对这些缺点,提出了很多改进:
🏗️ 内存 & 分辨率问题
- R-MVSNet (2019):用递归方式逐层更新代价体,不用一次存下全部。
- CasMVSNet (2019):提出级联金字塔,先粗采样再细采样,大幅减少 D(内存显著下降)。
- UCSNet (2020):用可变采样策略,自适应深度范围,避免浪费。
⚡ 推理效率问题
- PatchmatchNet (2021):把传统 PatchMatch 算法“学习化”,不需要构造完整代价体,速度和显存占用大幅优化。
- NeuralRecon (2021):面向实时重建,适配视频流。
🤖 模型表达力问题
- TransMVSNet (2022):引入 Transformer,全局上下文建模,提升遮挡/纹理不足区域的效果。
- AA-RMVSNet (2020):引入注意力机制,改进 3D 卷积的正则化。
🌍 泛化 & 大模型方向
- DUSt3R (2024):不再依赖已知相机姿态,直接预测点云/pointmap,鲁棒性极强。
- MVSAnywhere (2025):把单目大模型先验(如 MiDaS/ZoeDepth)和 MVS 几何结合,真正实现“零样本跨场景”泛化。
7、未来趋势
- 高效化 & 轻量化
- 用 PatchMatch/稀疏采样/级联方式,进一步减少显存和计算,让 MVS 可以实时跑在移动设备上。
- 融合大模型先验
- 单目大模型(MiDaS、ZoeDepth)有强大的跨场景能力。
- MVS 未来趋势是“几何 + 语义大模型”结合(MVSAnywhere 就是开端)。
- 摆脱严格相机姿态依赖
- 未来 MVS 会越来越鲁棒,即使位姿估计不准,也能通过学习补偿(DUSt3R 代表)。
- 与 3D 表达形式结合
- 结合 Gaussian Splatting、NeRF、3DGS 等新型表示,让深度估计直接服务于可渲染、可编辑的 3D 表达。