PatchmatchNet(2021) :学习型多视角Patchmatch立体匹配,学习化 PatchMatch,效率里程碑
导出时间:2025/11/24 08:52:35
1、PatchmatchNet 的背景和动机
多视图立体(MVS)的“建房子”问题
想象你要用几张房子的照片,把房子的三维模型搭建出来。
这就是 多视图立体(MVS):通过多张相机拍的照片,推算每个像素在空间里的深度(离相机有多远)。
问题是:
- 照片里有的地方暗、有的地方亮;
- 有的地方被挡住了;
- 有的地方墙壁很光滑,几乎没纹理。
所以,想要准确重建房子,就很难。
MVSNet / CasMVSNet 的办法:堆砖头法
之前的 MVSNet、CasMVSNet,就像是为了建房子,先把所有可能的位置都搭建一个“巨大的脚手架”(这就是 3D cost volume)。
然后:
- 把每张照片都往这个脚手架上对齐,
- 再用一个强大的工人(3D CNN)在脚手架里检查每个位置,
- 最后决定哪里应该有墙、哪里是空的。
优点:很全面、很准确。
缺点:脚手架太大,
- 占地方(显存太大),
- 搭建和检查太慢(计算太耗时)。
所以 MVSNet 系的方法 很好,但太笨重,用在手机或 VR 眼镜这种小设备上,几乎不可能。
PatchMatch 的办法:传小纸条法
传统的 PatchMatch 更聪明。它不去搭建庞大的脚手架,而是:
- 每个人(像素)一开始随便猜一个答案(比如“我离相机 5 米远”)。
- 然后把这个答案传给邻居,邻居如果觉得靠谱,就用;觉得不行就再改一改。
- 大家这样互相传递、修改,小区里的答案会逐渐接近正确。
好处:
- 不用搭建庞大的脚手架(省显存);
- 猜的方式很快,不需要看遍所有可能情况。
坏处:
- 这个方法虽然快,但毕竟是靠“随便猜 + 邻居传话”,没用到学习到的图像特征,所以在一些复杂情况(比如玻璃、光滑墙面)就容易犯错。
PatchmatchNet 的动机:快 + 准的结合
于是,研究者就想:
能不能把 PatchMatch 的“快速、轻量” 和 深度学习的“聪明、准确” 结合起来?
这就是 PatchmatchNet:
- 沿用 PatchMatch 的“传小纸条”机制 → 保证快、占内存少。
- 在传和判断的时候,不是瞎猜,而是让 神经网络来指导谁该信谁、该怎么改答案 → 提升准确率。
- 还用 多层粗到细的方式(先看大概,再慢慢细化),就像先画草图,再精雕细琢 → 更高效。
2、PatchmatchNet 的模型网络结构
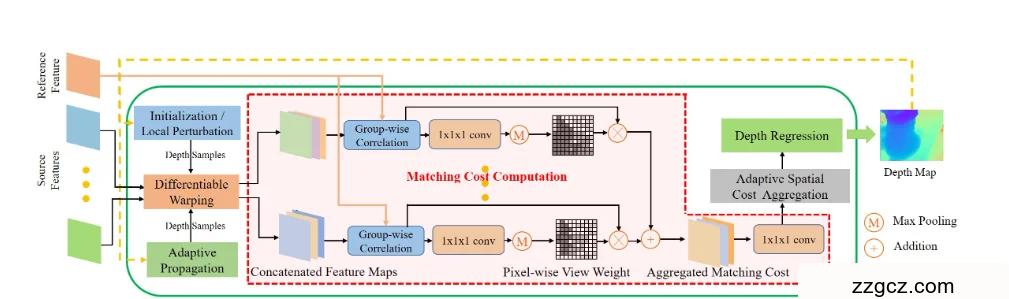
把“求深度”想成一群住在网格里的居民(每个像素),大家一开始对“我离相机有多远”都只有猜测。PatchmatchNet做的事,就是让大家先大胆猜、再向靠谱的邻居取经、再用多台相机相互印证、再在本地开小会求共识,循环几轮,答案就稳定了,而且全程很省内存、很快。
图解 PatchmatchNet(照着图,一路走到底)
0)左边:Reference / Source Features(参考图与多张源图的“指纹”)
- 把输入的多张照片先变成更好比对的“图像指纹”(特征)。这样后面比相似度会更稳。
- 这些特征其实来自一个多尺度金字塔(粗到细),方便后面逐级细化深度,既快又省。
1)Initialization / Local Perturbation(初始化 / 局部抖一抖)— 橙色块
- 类比:每个居民先随机写几张“可能的距离小纸条”(一像素会同时保留多条“深度假设”)。这样全社区的初始答案足够多样,别一上来就集体跑偏。
- 后续迭代时,不再完全随机,而是围绕上一次的最好猜测“抖一抖”(局部扰动),在附近再取几条候选,帮助精修细调。
2)Adaptive Propagation(自适应传播)— 绿色块
- 类比:向“靠谱的邻居”取经。但邻居不是固定的“上下左右”,而是网络学着挑:哪些位置更可能跟我属于同一块真实表面(比如同一面墙),就从那儿“抄作业”。
- 这一步用到了“可变形的采样”思想:偏移量是学出来的,不跨物体边界,也能在无纹理处向更大范围搜寻可靠意见——所以比死板的九宫格邻居更聪明、更快收敛。
3)Differentiable Warping(可微重投影)— 橙色块
- 类比:有了“深度小纸条”,就能推断:如果我真在这个深度,在别的相机里我会投到哪里?
- 网络据此把源图的特征拉到“我的这张深度假设平面”上来对齐。对齐后,大家就能对着同一位置比“像不像”了(这就是经典的平面扫掠思路)。
4)Matching Cost Computation(匹配代价计算)— 红色虚线大框
这是图里最大的一块,里面有三步:
4.1 Group-wise Correlation(分组相关)
- 类比:把特征拆成若干小分组,分别算“相似分”,最后再综合。分组能让相似度计算更细腻、也更稳。
4.2 Pixel-wise View Weight(像素级视图权重)
- 类比:不是每台相机都能看到我(有遮挡/视角问题)。那就先学一个“我对哪台相机最能说得上话”的权重:
- 每个像素单独评估,数值大表示“这台源相机在这个像素上更可信(更可见)”。
- 这些权重在最粗一级的第一次迭代根据一开始那批“多样化深度假设”学出来,之后在更细级别里沿用并上采样,既稳又省算力。
- 结果:把多台相机来的“相似分”按权重加权,得到聚合后的匹配分。图里的“⊗ 乘号 / ⊕ 加号 / M 最大池化”就是这套加权与聚合的小操作符。
4.3 1×1×1 Conv(小脑袋做决策)
- 用几层小小的 3D 卷积把“分组相似度们”压成一个总的代价值,对应“这个像素在这条深度假设下,像/不像”的评分。
5)Adaptive Spatial Cost Aggregation(自适应空间聚合)— 灰色块
- 类比:在最终投票前,先在我周围的一个邻域里开个小会,听听邻居们的代价评分,再自适应聚合一下。
- 重点是“自适应”:网络会学着挑哪几个邻居更像跟我在同一表面(避免跨边界串门),并且根据特征相似度/深度相近度给不同邻居不同权重,减少噪声、稳住结果。
6)Depth Regression(深度回归)— 绿色块
- 把一像素所有深度候选的代价先变成“概率”(softmax),再做一个加权平均,得出这个像素的最终深度。
- 类比:我手里有很多张“深度小纸条”,每张的支持率不同;最后按支持率加权投票,形成我的“定案”。
7)黄色虚线回环:迭代 + 粗到细
- 刚刚得到的深度图,会喂回前面:下一轮就围绕它做“局部抖一抖”再细修,或者下到更细一级的特征图继续干(金字塔式 coarse→fine)。
- 因为是粗到细、而且传播/邻域都是学出来的,几轮就能收敛,既稳又快、显存还小。
额外一笔:最细一级不再做完整 PatchMatch,而是直接上采样 + 一个小的残差细化网,用原图 RGB 做引导,把边缘再磨一磨,细节更干净,同时更省时。
把整条流水线再串成一个“故事”
- 先做指纹:把多张图变成好比的特征(多尺度)。
- 大家先大胆猜:每像素拿几张深度小纸条(初始化/局部扰动)。
- 向对的邻居取经:自适应找“同一块表面”的邻居,搬来更靠谱的假设(自适应传播)。
- 跨相机核验:把源图在每条假设深度下重投影到我这儿来,逐一比“像不像”(分组相关)。
- 会看谁更可信:学会按像素给每台源相机打可见性权重,只听可信的人(像素级视图权重)。
- 本地小会:在我附近但不跨边界的地方再开个小会,稳住噪声(自适应空间聚合)。
- 投票定案:把所有假设按支持率投票,得出我的深度(回归)。
- 进入下一轮:把结果传回去,在更细一级继续抖一抖、修一修,直到收敛。 ——这一整套,就是图里从左到右、再回环的流程。
为什么这套设计既“快”又“准”?
- 快 & 省内存:不建庞大的 3D 代价体、也不跑重型 3D CNN;候选是“按需取邻居 + 局部扰动”,显存与深度范围解耦,能扛高分辨率输入。
- 准:
- 传播与空间聚合都是学出来的邻域,不会傻傻跨过物体边界;
- 像素级视图权重能识别遮挡/不可见视角,只跟看得清的人对表;
- 粗到细逐级细化,先定大概、再抠细节。