R-MVSNet(2019):用于高分辨率多视角立体深度推断的循环神经网络,用“记忆网络”解决内存瓶颈
导出时间:2025/11/24 08:51:58
1、研究背景和动机
背景:多视图立体重建(MVS)在做什么?
给定多张从不同角度拍摄、且相机已标定的图片,MVS 的目标是为每个像素估计一个深度,从而恢复场景的稠密三维结构。传统方法(如代价聚合、半全局匹配)已经能做得不错;而近年来的深度学习方法把多视图信息堆成一个三维代价体(cost volume),再用神经网络“抹平噪声、补全细节”(即正则化),通常能得到更完整、更稳定的深度图。代表性工作如 MVSNet 将多视图特征经同形变换(平面扫描/单应)对齐到参考视角的不同深度平面上,再用 3D CNN 对整个三维代价体做多尺度正则化,最后回归深度。
痛点:3D CNN 的“立方级”内存墙,限制了分辨率与深度范围。
3D CNN 在代价体 H×W×DH\times W\times DH×W×D 上卷积,显存开销随分辨率呈立方增长。一旦图像很大(高分辨率)或深度采样很密(大 DDD、宽深度范围),显存就会爆炸,导致模型很难扩展到高分辨率或超宽景深场景(例如 Tanks and Temples 的 advanced 套件)。这几乎是当时“端到端学习型 MVS”的共同瓶颈:要么降分辨率、要么缩小深度范围、要么拼分块,都会牺牲全局上下文或耗时严重。此前也有尝试用稀疏八叉树(OctNet/O-CNN)或工程化的分而治之策略来省显存,但仍难以应对 >5123512^35123 体素规模或真实大场景。
已有启发:顺序化的体正则化更省内存。
传统 MVS 中,平面扫描(plane sweeping)+ 2D 空间代价聚合 + 胜者为王(WTA) 的按深度顺序处理思路,显存占用更友好(不需一次性把完整 3D 体拿来做重卷积)。但这些做法要么噪声大,要么仅做局部空间滤波,不能像 3D CNN 那样兼顾“空间+深度方向”的上下文。
论文的核心动机:把“顺序化处理”与“深度学习的上下文建模”结合起来。
作者提出 R-MVSNet:不再用 3D CNN 一口气正则整个 3D 代价体,而是把代价体视作按深度切开的一系列 2D 代价图,沿深度方向依次送入卷积式 GRU(Conv-GRU)。
- 直观理解:每到一个深度平面,网络一边做 2D 卷积来汇聚空间上下文,一边通过 GRU 的“记忆/门控”把前面所有深度平面的深度方向上下文也带过来。
- 显存收益:在线内存从对 H×W×D 的立方依赖,降到对 H×W 的平方级(与 D 脱钩),因此可以把 D 设得很大,从容覆盖高分辨率与超宽深度范围的场景。
- 目标:在几乎不牺牲精度的同时,解决学习型 MVS 的可扩展性难题,让网络能在更大的真实场景上稳定工作。
为何值得:预期带来的影响
- 可扩展性:同样显存下可处理更大的图像、更密的深度采样,覆盖更复杂、尺度更大的数据集;
- 效果与效率的权衡更优:相比简单的平面扫描+WTA 或纯 2D 聚合,Conv-GRU 在深度方向引入记忆与门控,更接近 3D CNN 的正则化质量;
- 实践友好:面向真实三维重建工作流(筛深度、稠密融合),在公共基准(DTU、Tanks and Temples、ETH3D)上展示与或优于当时 SOTA 的表现,同时显著降低显存瓶颈。
小结:这篇工作的出发点很朴素——把“3D 体的一次性正则化”改造成“沿深度顺序、带记忆地逐步正则化”。这样既继承了深度学习对上下文的表达力,又绕开了 3D CNN 的显存墙,从工程上把“高分辨率/宽景深”的学习型 MVS 推进了一大步。
2、模型的核心创新点
论文的主角是 R-MVSNet(Recurrent Multi-View Stereo Network),它在前作 MVSNet 的基础上进行改进,关键创新点集中在以下几方面:
(1)从三维卷积到“递归二维卷积”:内存节省的革命性思路
- 以前的 MVSNet 要在三维体积 H×W×DH\times W\times DH×W×D 上用 3D 卷积 做特征融合和正则化。 → 问题是显存需求随三维体积立方增长,非常恐怖。 → 举例:输入图片大一点(比如 1600×1200),或者深度采样多一点(几百层),显存就炸了。
- R-MVSNet 的突破点:把这件事拆开做! 它不再同时处理整个三维代价体,而是把代价体按深度切成一张张“二维代价图”,再用一个能记忆前后信息的网络——Conv-GRU(卷积门控循环单元) 逐层处理。
- 简单比喻: 想象你要看一叠 3D 扫描的切片图(从近到远),3D CNN 是把整叠一起看完; 而 R-MVSNet 则是每次只看一张,同时记住前几张的上下文关系,这样既省内存又能捕捉深度方向的连续性。
- 效果: 显存从原来的立方级降到平方级,意味着模型可以处理更高分辨率和更大深度范围的场景。 在保持精度的同时,推理速度也提升显著。
(2)Conv-GRU 在深度方向的“时序建模”
- 传统 RNN(循环神经网络)用于时间序列; 而这里的“时间轴”换成了“深度轴”——即深度从近到远的一系列平面。
- 在每一层深度:
- 通过 2D 卷积 处理当前代价图,提取空间上下文;
- 通过 GRU 门控机制,记忆上一个深度层的特征;
- 最终输出更新后的隐藏状态,传递给下一层。
- 这种结构让模型能捕捉深度维度的全局依赖关系,而不是像传统平面扫描那样每层独立估计。
(3)反深度(Inverse Depth)采样:更合理的空间分布
- 论文中采用了反深度采样策略(inverse depth sampling),即在近处采样密、远处采样稀。 这样更符合透视几何规律,也能更有效地利用采样点——因为近距离的深度变化对视觉误差更敏感。
(4)概率体与深度回归:让深度估计更稳健
- R-MVSNet 输出的不是单个深度值,而是每个像素在不同深度下的概率分布(概率体)。
- 训练时使用交叉熵损失,回归时取概率加权平均深度。 → 这种方式比直接回归一个数更稳定,也更容易收敛。
(5)多视图融合策略的保持与优化
- 它继承了 MVSNet 的多视图特征对齐方式: 利用单应变换(Homography Warping)把不同视角的特征对齐到参考视图的各个深度平面上。
- 这样可以动态适配任意数量的输入视图,实现端到端的多视图深度估计。
(6)训练与推理兼顾效率
- 训练时可以在中低分辨率下进行;
- 推理时可直接在高分辨率上运行(因为显存消耗小了很多)。
- 这使得 R-MVSNet 成为首个能在大场景高分辨率下稳定运行的端到端 MVS 深度网络。
✅ 总结一句话:
R-MVSNet 的核心创新,就是把原本“笨重的 3D 卷积体”变成一个“沿深度方向循环处理的轻量 2D 网络”,通过 Conv-GRU 记忆机制实现三维信息融合,从而在不牺牲精度的情况下,大幅降低显存占用并提升可扩展性。
3、网络结构与工作原理(配合图示逐步看)
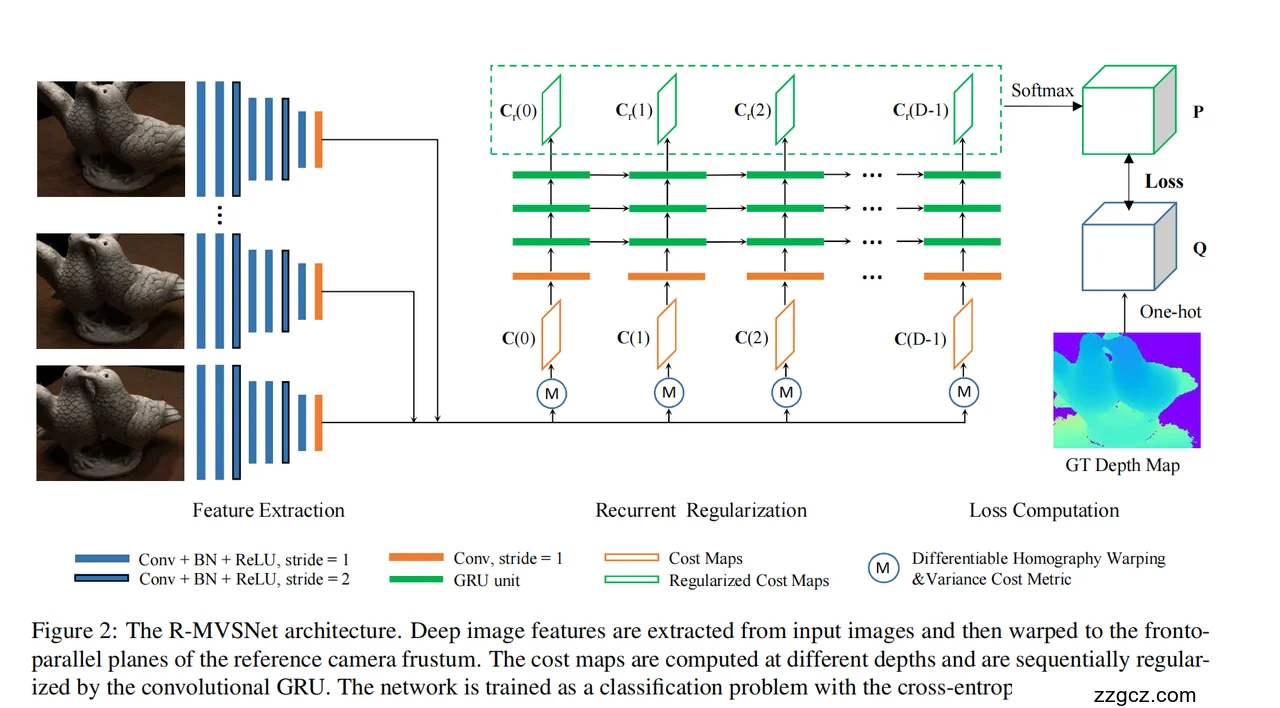
0)任务与输入
- 输入:一张参考图像 + 若干源视图(至少2张更好),以及它们的相机内外参。
- 输出:参考图像视角的一张稠密深度图(每个像素一个深度)。
1)特征提取(图左侧蓝色条)
- 每张图先过一套共享权重的 2D CNN 提特征(蓝色条堆叠)。
- 蓝色深浅两种,表示网络里既有 stride=1 的卷积层,也有 stride=2 的降采样层,得到分辨率较低但语义更强的特征图。
- 这么做的好处:不同视角的图都被“翻译”到同一种特征空间,后面对齐和比对更稳。
2)按候选深度做“可微对齐”与代价构建(图中每个深度的 M 圆圈 → 橙色菱形 C(d))
- 关键想法:把 3D 重建拆成很多个“前平行平面”的2D问题。
- 对参考视角设定 DDD 个候选深度(实际是反深度采样:近处密、远处疏,更符合透视规律)。
- 对每个深度 ddd:
- 用相机参数计算这个深度对应的单应变换(Homography),把每个源视图的特征图“扭”到参考视角这个深度平面上(图中蓝色圆圈 M)。
- 把对齐后的多张特征在通道维做一个方差聚合(variance cost metric),得到这一层深度的代价图 C(d)C(d)C(d)(图里橙色倾斜菱形)。
- 直觉:如果这个深度对了,不同视角被扭到一起后更一致,方差就小;反之就大。
- 结果:我们不一次性做三维体,而是拿到一串按深度排列的二维代价图序列:C(0),C(1),…,C(D − 1))。
3)递归正则化:Conv-GRU 跨深度“带记忆”地处理(绿色横条与方块)
- 这是 R-MVSNet 的招牌:把“深度维”当作“时间轴”,用**卷积 GRU(Conv-GRU)**顺序处理。
- 流程(对每个深度从近到远):
- 把当前代价图 C(d)送入 Conv-GRU。
- Conv-GRU 内部有门控与隐藏状态,它会把“前面所有深度层学到的信息”记住并传下去,同时用卷积在空间上做上下文融合。
- 输出这一层被“抹平/增强”后的代价图 Cr(d)(图里绿色倾斜方块),并更新隐藏状态给下一层深度使用。
- 图里有多层绿色横条,表示堆叠了多层 Conv-GRU,表达力更强。
- 内存优势:只需要保留当前这一层的代价图 + GRU 的隐藏状态,不必把 H×W×D的整个三维体塞进显存——这就是它能上高分辨率和大深度范围的关键。
4)把“代价序列”变成“深度概率”(右侧 Softmax 得到 P)
- 对于参考图像的每个像素,我们都拿到沿深度维的一串正则化后的代价值 {Cr(d)}。
- 把它们过一个1×1 卷积/线性映射后,对深度维做 Softmax → 就得到该像素在每个候选深度上的概率分布 P(d)(图右上绿色立方体 P)。
- 直觉:哪一层概率最高,就表示这个像素最可能在那一层深度上。
5)训练时怎么“对准答案”(Loss 与 Q)
- 训练阶段,真实深度会被量化到最近的候选深度层,做成one-hot 分布 QQQ(图中灰蓝立方体 Q)。
- 用 交叉熵损失 比较预测分布 P 与 Q,推动网络把概率堆到正确深度上(图中 “Loss” 箭头)。
6)推理得到深度图(从 P 变成真实深度)
- 测试时,一般用期望/soft-argmin:d^=∑dP(d)⋅d,得到亚像素级深度估计;
- 再把离散的候选深度索引 ddd 转回真实深度值(因为我们是按反深度在采样)。
7)后处理与多视图融合(图外常规步骤)
- 为了更稳,通常会做两步:
- 光度置信度筛选:如果一个像素的最大概率太低,视为不可靠,剔除或插值;
- 几何一致性检查:在不同参考视图之间交叉验证深度是否一致,移除离群值;
- 最后把各参考视图的深度图融合成密集点云/网格(配合相机参数就能还原 3D)。
把图上的元素再对号入座
- 蓝色条:每张输入图的2D 特征提取(Conv+BN+ReLU,含 stride=1/2)。
- 橙色横条(conv, s=1):对齐后的小卷积,用来整理通道/特征。
- 蓝色圆圈 M:可微单应变换 + 方差代价度量,在每个深度把多视图对齐并聚合成代价图 C(d))。
- 橙色/绿色倾斜块:分别是原始代价图 C(d)与 正则化后的代价图 Cr(d)。
- 绿色横条:Conv-GRU 单元(通常多层堆叠),按深度顺序递归处理。
- Softmax → P:把每像素沿深度的代价转成概率体。
- Q(one-hot)+ Loss:训练时的监督信号与损失。
- 右下角 GT Depth Map:训练用的真实深度图。
一句话总览
“先用单应把多视图在每个候选深度上对齐→方差聚成代价图→用 Conv-GRU 沿深度维递归正则化→Softmax 得到每像素的深度概率→期望/argmax 回归深度→筛选与融合成 3D。” 这整套做法把 3D CNN 的块级计算,变成了“一层层深度切片 + 带记忆的 2D 处理”,既保留上下文,又把显存开销压得很低。
4、模型的核心不足与未来改进方向
一、核心不足
(1)深度维“顺序处理”仍然存在时间开销
- 虽然 R-MVSNet 通过 Conv-GRU 节省了显存,但代价是推理需要逐层处理每个深度平面(从近到远)。
- 这意味着即使显存省了,速度仍受深度采样数 D 限制。如果要在高分辨率场景中保证精度(即 D 很大),计算时间仍然偏长。
- 总结:显存问题解决了,但推理速度仍不是最佳。
(2)Conv-GRU 的长程依赖有限
- GRU 虽然能记忆前面几层的上下文,但在深度方向上层数过多时,记忆衰减问题依然存在。
- 也就是说,Conv-GRU 对非常远处(如深度平面相差几十层)的关系建模不如 3D CNN 那样充分。
- 这会导致远近深度之间的全局一致性略弱,某些复杂表面可能出现局部深度跳变或误差积累。
(3)单尺度特征,缺乏多尺度感知
- R-MVSNet 的特征提取是单尺度的卷积金字塔,虽然有效,但对不同深度范围、不同大小的物体,缺少多尺度特征融合能力。
- 在纹理重复或弱纹理区域(如墙壁、地板)中,模型仍会不稳定或产生空洞。
(4)概率分布离散化带来的误差
- 网络输出的是离散深度概率体(按固定步长采样)。
- 如果深度分辨率过低(采样间隔太大),即使 Soft-argmin 可以插值,也可能出现细节模糊或深度偏移问题。
- 这在真实大场景或远距离视差小的区域尤为明显。
(5)真实场景适配性有限
- 模型主要在实验室标定数据集(如 DTU)上训练,对光照变化、运动模糊、非Lambert表面(反光/透明物体)等现实情况的鲁棒性较弱。
- 同时,它依赖精确的相机参数和稳定曝光,因此在非受控环境中(如无人机或移动设备)直接应用仍有挑战。
二、未来的改进与创新方向
(1)提升并行性,减少顺序依赖
- 研究方向之一是让深度方向处理部分并行化。
- 比如使用 Transformer 或 1D 卷积注意力 替代 GRU,让深度维的全局依赖一次建模,而不是逐层传递。
- 这样既能保留显存优势,又能显著加速推理。
(2)引入多尺度与层次特征融合
- 可以在特征提取阶段引入 FPN(Feature Pyramid Network) 或 多尺度特征融合模块,增强对不同尺度物体的深度感知。
- 也可在代价体构建阶段使用金字塔式深度采样:先粗估深度,再局部细化,提高精度同时减少采样层数。
(3)改进记忆机制:Transformer 或 ConvLSTM 替代
- 近年来有工作提出使用 Self-Attention/Transformer 来替代 Conv-GRU,直接在深度维捕捉远程依赖。
- 或者用 ConvLSTM 等更强的时序单元,增强跨层特征的动态记忆与交互。
(4)结合学习与几何约束的混合框架
- 可在网络中显式嵌入几何一致性约束(如多视图重投影误差),或在损失函数中引入几何正则项。
- 这样能提升模型在光照变化、曝光不一致下的稳定性。
(5)端到端融合后处理(从深度到点云/网格)
- 目前 R-MVSNet 的点云融合是单独后处理步骤。未来方向是把 深度估计 + 融合重建 整合为一个端到端模块,实现自动滤噪、补洞与一致性优化。
(6)跨域泛化与自监督训练
- 现有模型依赖高质量标注深度数据,泛化能力不足。
- 未来可以结合无监督或自监督学习(如基于光度一致性约束),提升模型在真实数据上的适应性。
✅ 总结一句话:
R-MVSNet 的突破在于“显存可扩展”,但仍受限于“推理顺序性”和“长程依赖建模不足”。 未来方向是并行化(如 Transformer)+ 多尺度融合 + 自监督几何约束,让 MVS 网络既高效又能在真实世界中稳健工作。