TransMVSNet(2022) :基于Transformer的全局上下文感知多视角立体网络,Transformer 在 MVS 的应用
导出时间:2025/11/24 08:53:57
1、背景:多视图立体(MVS)的核心问题
多视图立体要做的事情是:利用多张不同角度的图像,恢复场景的稠密三维结构。
这实际上是一个 特征匹配问题:
- 给定一张参考图,每个像素都要在其他源图中找到对应的匹配位置,才能确定深度。
- 如果匹配准了,就能得到准确的 3D 重建;如果匹配错了,就会有噪声或缺失。
1.1、传统学习型 MVS 的局限
像 MVSNet、CasMVSNet、PatchmatchNet 等方法,都取得了很大进展,但仍然存在一些痛点:
(1)局部视野(Local Context)的限制
- CNN 的感受野有限,更善于捕捉局部信息。
- 在 纹理缺失、重复纹理、镜面反射 等区域,仅靠局部特征很容易匹配错误。
- 举例:一堵纯白的墙,CNN 只能看到周围几像素,无法区分“这是墙的哪个位置”。
(2)缺少全局上下文(Global Context)
- 现有方法通常是“逐图提特征”,再对齐到参考图后比对,但缺少图像之间的全局交互。
- 结果是:即使参考图和源图里有重复模式,网络也没法利用全局范围的信息去 disambiguate(消除歧义)。
1.2、Transformer 的启发
Transformer 在 NLP 和 CV 里大放异彩,靠的就是 Attention 机制:
- 可以“全局建联”:任何一个位置都能直接和图中任意位置的信息交互。
- 不像 CNN 只能一步步扩大视野,Transformer 一下子就能捕捉全局上下文。
在特征匹配任务里(比如 SuperGlue、LoFTR),Transformer 已经被证明能显著提高匹配质量:
- Self-Attention:整合一张图内部的全局信息。
- Cross-Attention:让不同图像之间的特征互相对齐和交互。
1.3、TransMVSNet 的动机
基于以上背景,研究者提出了 TransMVSNet,主要动机有三点:
(1)解决 CNN 的“近视眼”问题
- CNN 提取的特征是局部的,容易在“低纹理、重复纹理、非朗伯表面”出错。
- TransMVSNet 用 Feature Matching Transformer (FMT),让网络具备 全局感知能力,更稳健地做深度估计。
(2)增强多视图之间的交互
- 传统方法在计算匹配代价时,各图像的特征是“各管各的”,没有提前交流。
- TransMVSNet 在进入代价计算前,就让参考图和源图通过 Cross-Attention 建立关系,这样源图特征会对齐参考图,更利于匹配。
(3)让 Transformer 与 MVS 高效结合
直接把 Transformer 接入 MVS 会遇到两个问题:
- 特征域差距:CNN 输出是局部特征,而 Transformer 更偏全局,二者需要平滑过渡。→ TransMVSNet 提出了 Adaptive Receptive Field (ARF) 模块,桥接局部和全局特征。
- 内存消耗大:Transformer 计算量大,不可能在高分辨率下直接跑。→ TransMVSNet 设计了 分层金字塔 + 特征通道传递,在低分辨率跑 Transformer,再逐级传递到高分辨率。
1.4、总结一句话
TransMVSNet 的背景和动机就是:
现有 MVS 方法在“全局上下文”和“跨图交互”上不够强,导致在低纹理、重复纹理等复杂场景表现不稳。Transformer 的全局建联能力正好能解决这个问题,于是提出了 TransMVSNet,用 Transformer 来做多视图特征匹配,让网络既能看得更远,也能跨图交流。
2、TransMVSNet 的创新点
2.1、Feature Matching Transformer (FMT)
核心创新点 1:把 Transformer 专门改造成适合 MVS 的特征匹配器
- 传统 MVS:只用 CNN 提取特征 → 建代价体 → CNN 正则化。
- 问题:CNN 更关注局部,看不远,也没有让不同图像之间的特征交流。
FMT 的做法:
- Intra-Attention(图像内部自注意力) 就像在一张图里开全员大会,让每个像素都能“听到”整张图的信息,增强全局感知。 → 解决“低纹理、重复纹理”的歧义。
- Inter-Attention(跨图像交叉注意力) 参考图和源图之间互相“对话”,源图特征会根据参考图调整。 → 让匹配前,图像间就已经建立联系,更容易找到对应点。
📌 创新点在于:这是 第一个在 MVS 里用 Transformer 做 dense(稠密)特征匹配 的方法。
2.2、Adaptive Receptive Field (ARF) 模块
核心创新点 2:在 CNN 和 Transformer 之间加了一个“适配器”
- 问题:CNN 特征是“局部小眼光”,Transformer 特征是“全局大视野”,两者直接对接会不顺畅。
- 解决:加一个 ARF 模块(基于可变形卷积),能自动调整特征的感受野,逐渐过渡到全局范围。
📌 形象比喻:就像给近视眼的人配一副渐进多焦点眼镜,让他能从近处到远处都看清楚。
2.3、Transformed Feature Pathway
核心创新点 3:特征通道传递,让 Transformer 的结果逐级上采样
- 问题:Transformer 太吃内存,不能直接在高分辨率上跑。
- 解决:先在低分辨率图上跑 FMT,再通过 特征路径传递,把信息往高分辨率层层传递,同时还能让梯度流回来。
📌 形象比喻:就像先在缩略图上把全局关系弄明白,再把这些“关系图谱”带到高清大图里细化。
2.4、Pair-wise Correlation + Focal Loss
核心创新点 4:更高效、更鲁棒的匹配代价构建与监督
- Pair-wise Correlation:不用传统的高维 cost volume,而是只计算 逐像素的相似度,减小显存和计算开销。
- Focal Loss:训练时特别关注“难样本”(模糊边界、低置信度区域),让模型在模糊场景下表现更好。
📌 形象比喻:不再是“把所有情况都塞到大仓库里比对”,而是“一对一单独对账”,同时训练时更关注那些容易出错的地方。
2.5、总结一句话
TransMVSNet 的核心创新点就是:
它用 Transformer 来做多视图匹配,既能看全局(Intra-Attention),又能跨图交流(Inter-Attention),再通过 ARF + 特征通道传递 把 Transformer 高效地嵌入 MVS 流程,最后用更聪明的代价计算和 focal loss 来提高鲁棒性。整体既提升了准确率,又在复杂场景下表现稳定。
3、图解 TransMVSNet 网络结构
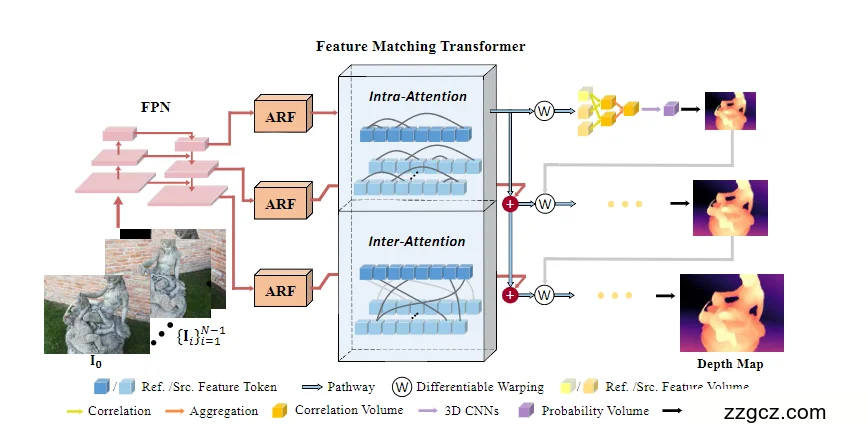
1)输入(最左边)
- 输入:1 张 参考图 + 多张 源图(图里下面的小相机表示 N-1 张源图)。
- 目标:推断参考图中每个像素的 深度(Depth Map)。
👉 类比:参考图是“主考官”,源图是“考官小组”,大家要对齐回答“这个像素到底多远”。
2)FPN 特征提取(Feature Pyramid Network)
- 每张图先经过 CNN(FPN)提取多尺度特征。
- 为什么要多尺度?
- 粗尺度特征:能看大结构,减少搜索范围;
- 细尺度特征:能抠细节,补充精度。
👉 类比:拍一张照片,你既要看“整体轮廓”,也要看“细节纹理”。
3)ARF 模块(Adaptive Receptive Field)
- FPN 输出的特征 → 先送进 ARF。
- 作用:让局部 CNN 特征逐渐适配到能给 Transformer 用的“全局特征”。
- 技术上:通过可变形卷积,扩大感受野,让网络学着决定“该关注多远的邻居”。
👉 类比:戴上渐进眼镜,从“近视局部视角”逐渐过渡到“远视全局视角”。
4)Feature Matching Transformer(蓝色大框)
这是整个网络的 核心创新,分为两部分:
(a)Intra-Attention(图像内部自注意力)
- 在同一张图内,每个像素都能和全图的像素建立联系。
- 作用:提升全局上下文理解,解决“低纹理 / 重复纹理”区域的歧义。
👉 类比:一所学校里的学生开大会,每个人都能听到全校的信息,不再只是看自己教室。
(b)Inter-Attention(跨图像交叉注意力)
- 参考图和源图的特征互相对话。
- 作用:在进入 cost volume 前,特征就已经对齐,减少匹配歧义。
👉 类比:不同学校的学生提前开联谊会,建立联系,等到考试比对时更容易找到对口的人。
5)代价体构建(黄色方块:Correlation Volume)
- 有了参考图特征 + 源图特征,就可以做 Differentiable Warping(可微重投影):
- 把源图特征根据候选深度投影到参考图坐标系下。
- 然后计算 逐像素相似度(pair-wise correlation),得到匹配代价。
👉 类比:假设一个学生说“我在 5 米远”,那就把其他学校的学生按 5 米远的位置投影过来比对,看像不像。
6)3D CNN 正则化(紫色方块)
- 构建好的代价体还很“嘈杂”,需要一个轻量 3D CNN 来平滑、聚合上下文。
- 最终得到一个 概率体(probability volume)。
👉 类比:像老师在阅卷时,不是看单个答案,而是结合上下文判断谁更靠谱。
7)深度回归(右边三个深度图)
- 从概率体中回归出最终深度图。
- 采用 coarse-to-fine(粗到细):
- 上层粗分辨率先大致确定范围;
- 下层细分辨率再精修;
- 最细层用 Winner-take-all(赢家通吃)得到最清晰的深度图。
👉 类比:先看缩略图确定“差不多在这”,再用高清图一点点抠细节。
✅ 一句话总结图的内容: TransMVSNet 的网络结构是: 👉 CNN 提局部特征 → ARF 过渡到全局 → Transformer 抓全局和跨图信息 → 轻量代价体构建 → 3D CNN 平滑 → 粗到细深度回归。 它的特别之处,就是在 cost volume 前加了 Transformer,让特征更全局、更对齐,所以最后的深度图更准。