1dtans(2024):基于Transformer和人工标注数据的拉曼光谱基线估计
导出时间:2025/11/24 08:58:35
1、研究背景和动机
1.1 拉曼光谱为何必须做预处理
真实拉曼光谱常被荧光/背景基线、随机噪声、甚至仪器与环境因素所淹没;若不先做基线校正+去噪,峰位与峰强都会偏离,后续定量/分类会显著失真。传统参数法(ModPoly、IModPoly、airPLS 等)需要大量调参,而且不同样本/设备下“最佳参数”差异很大,效率低且容易引入主观偏差
1.2 深度学习预处理的第一波:级联 CNN 路线
为摆脱“人肉调参”,Broderick 等(2022)提出用级联深度 CNN把预处理拆成两步:先基线校正,再去噪/去宇宙射线;还设计了潜在层/中间输出,让每一步都能被直观看到。他们大量用模拟光谱训练(多峰形+多阶多项式基线+噪声),在合成与多种真实任务(SERS 成像、膀胱组织低分辨率拉曼、EV SERS 分类)上,相比 airPLS/AsLS/iMor、SG/小波等传统预处理显著提升了速度与效果,并把常规机器学习分类的性能拉到了接近端到端深度模型的水平
要点:自动化、两阶段可解释、中间结果可用、推理毫秒级;不足是强依赖“高拟真模拟数据”,对跨设备/跨样本的真实域泛化仍存在风险
1.3 现实落差与新问题
虽然“模拟驱动”的级联 CNN 在论文里效果亮眼,但当真实数据分布复杂且与模拟假设不一致时,模型可能“纸上谈兵”:
- 全模拟训练→实测泛化掉档:即便合成集很大、峰形/基线很花,仍难完全覆盖生物样本的多样性与荧光背景形态;作者直观报告了“在合成验证集很好,但到实验数据就降级”的现象,这直接暴露出域差问题
- 参数法依旧在大量应用,但“每谱调参”的现实成本很高;在手持式设备、农业/食品等落地场景里尤其明显
1.4 本研究(1dTrans)的直接动机:从“模拟优先”转向“实验标注优先”
Zhao 等(2025)把问题的关键拎出来:与其继续砸更庞大的合成数据,不如基于真实实验谱做人工基线标注与增强,再训练一个一维 Transformer(1dTrans)专职做基线估计——把最容易“拖后腿”的那一步先做好、做稳
。他们的动机与设计可概括为三点:
- 数据动机:用人工标注覆盖真实变异
- 采集8 类生物材料(木材、啤酒花、小麦、叶组织、马铃薯、草莓、苹果酒、苹果),来自手持式 830 nm仪器的真实拉曼数据;在每类中抽样做人工基线标注,再用样条/权重做系统化数据增强,优先拟合“真实世界”的多样性,而非只追求“更花哨的模拟”
- 他们也试过10 万条全合成训练,但跨到实验数据上性能不佳,因而转向“实验标注优先”的策略
- 模型动机:引入注意力 → 全局上下文对基线更敏感
- 1dTrans采用一维 Transformer 编码器,并配Skip Concat 与 Dense Block做跨层信息复用,能在整条谱上建模长程依赖,适合估计缓变而非局部的基线趋势;相比局部卷积的 CNN/ResUNet,更符合“基线=全局缓变”的先验
- 应用动机:去掉“人肉调参”的门槛
- 目标是得到一个开箱即用的基线估计器:跨材料/设备时尽量稳健,减少用户在 ModPoly/IModPoly/airPLS 上反复调参的成本与主观性
- 在他们的实验里,1dTrans 在 MAE/SAM 指标上显著优于 ResUNet 与三种参数法,并在**未见材料(洋葱、薯片)**上泛化更平滑、伪影更少,印证了上述动机
一句话总结
过去的级联 CNN把拉曼预处理自动化了,但过度依赖模拟训练,遇到复杂实验分布易掉档 本研究用人工标注+增强的真实数据训练一维 Transformer做基线估计,以全局注意力替代局部卷积,直面“域差”和“调参门槛”的两大痛点
2、模型的核心创新点
① 从“模拟优先”改成“实验标注优先”的训练范式
过去很多深度学习预处理都依赖大规模合成光谱训练;本文反其道而行:先在真实实验光谱上做人工基线标注,再配合数据增强来训练模型,直接对准真实分布的复杂性与变异性(而不是只追求更花哨的仿真)。这一步实打实地减少了“纸面上很强、落地就掉档”的风险。
比喻:不再只在“模拟赛道”练车,而是把“真实路况”(坑洼、拥堵、逆光)采样标注后再练,驾照更“抗造”。
② 任务聚焦:把“基线估计”单列为可学习模块
论文把基线校正定位为一个明确的学习目标:针对“慢变的全局背景”而非局部噪点,训练专职的基线估计器,替代传统 ModPoly/IModPoly/airPLS 那种“每谱都要反复调参”的工作流,显著降低上手门槛。
比喻:请来“专业拉线师”专门把照片的“灰雾背景”拉平,后面的细修(去噪/分析)就更顺手。
③ 架构层面:一维 Transformer(1dTrans)做“全局视野”的基线建模
与卷积(更擅长局部感受野)不同,1dTrans 用自注意力跨整条谱建模长程依赖,更契合“基线=全局缓变趋势”的先验;作者据此定制了一维 Transformer用于拉曼基线估计,并拿它去对标 ResUNet 与参数法。
比喻:卷积像“手电筒”看局部,Transformer 像“泛光灯”一眼看整面墙——找“整墙的底色”(基线)更稳。
④ 标注与增强:用“多法融合”的方式构造高质量真值基线
他们不是凭主观手绘基线,而是把 ModPoly / IModPoly / airPLS 在不同区段最贴合的结果拼接+样条平滑成“地面真值”,再做系统化增强(关键词里也明示了 Augmentation)。这一流程把“真值”做得可复查、可复现、覆盖面更广。
比喻:不靠一个修图师拍脑袋,而是请三位修图师各做擅长部分,再由总监统一润色成“黄金版底图”。
⑤ 实证对比:在 MAE 与 SAM 两项指标上全面胜出
在8 类生物材料的原始拉曼数据上,1dTrans 相比 ResUNet(深度学习基线法)和三种参数法,MAE 更低、SAM 更优;并在“未见样本”上也呈现更平滑、更少伪影的基线,验证了方法的有效性与泛化性。
比喻:不仅“跑分高”,而且“盲测”也稳定,不挑场地。
⑥ 与既有深度法的定位差异被清晰化
经典的 ResUNet 基线校正多以仿真数据训练、以卷积为主;本文通过真实标注+Transformer路线,在“如何获得可靠训练信号、如何利用全局上下文”两个环节上,给出了与 ResUNet 不同的答案,构成方法学上的互补与升级。
比喻:同样是修路,一家擅长“局部铺补+模拟演练”,另一家主打“真实路况测绘+全局规划”。
⑦ 工程可用性:把“开箱即用”落到实处
核心落点不是“炫技”,而是让用户少调参/不调参即可得到可信基线,便于接入既有光谱流程(后续再做去噪、归一化、定量/分类等)。这正是工业/临床/手持设备落地最关心的一点。
和学过的“级联 CNN 预处理”(两步走、强调中间输出)相比:这篇工作把“数据侧(真实标注)+模型侧(Transformer 全局建模)”都做了结构性调整,直击域差与调参门槛两大痛点;而与 ResUNet 的“卷积+仿真训练”路径也形成了清晰对照。
3、模型网络结构
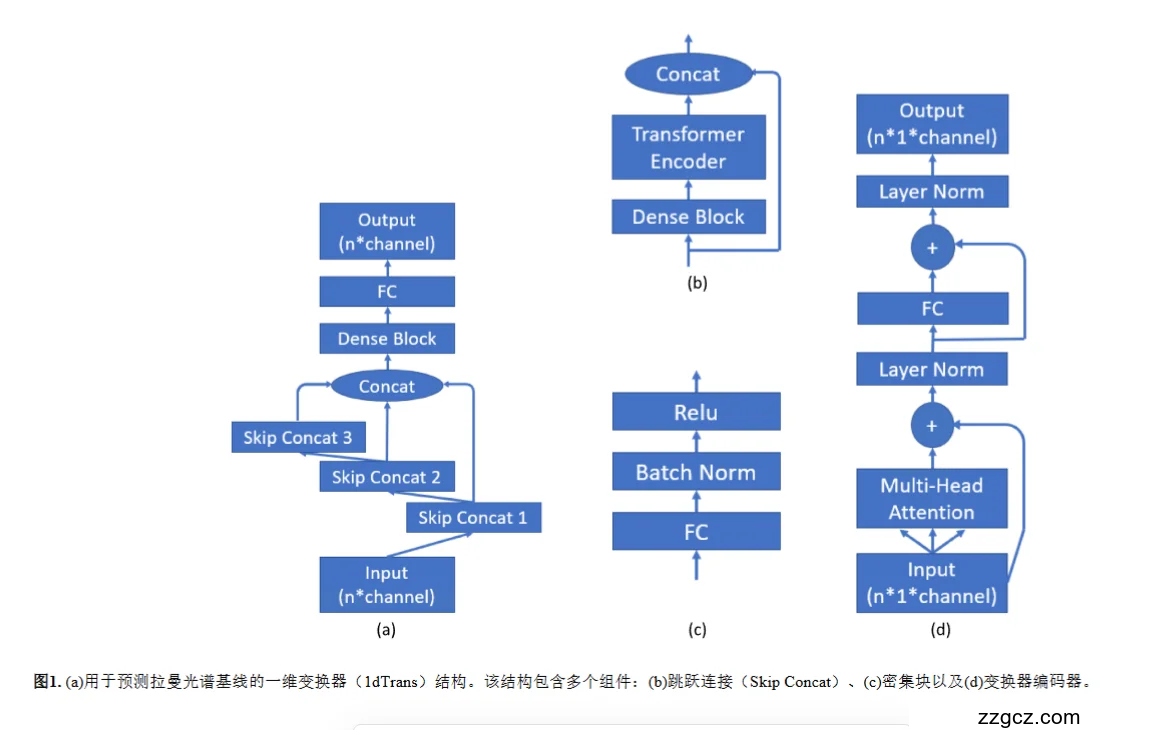
3、模型网络结构(结合你给的图)
下面把 1dTrans 的结构按图(a)–(d)拆开说清楚,并配上“为什么要这样连”。
总览:一条主干 + 多个“Skip Concat”旁路
- 输入/输出:输入是一条一维光谱向量,形状可记为 (n × channel)(通常 channel=1);输出同尺寸,是逐点回归得到的基线。图(a)里主干自下而上穿过若干单元,三处Skip Concat把早期/中期特征直接并到高层,再经 Dense Block + FC 得到最终基线。
- 同时该模型在论文中被称为1dTrans(一维 Transformer),用于拉曼基线估计。科学直通车
直觉:主干学“全局底色”,旁路把“早期细节”带上来,最后一起“会审”再给出每个波数点的基线值。
(b) Skip Concat:多尺度特征直连 + 拼接
- 结构:每个 Skip Concat 分支里,先过一段 Dense Block,再过 Transformer Encoder,把得到的高层表征与主干特征做 Concatenate(而不是相加)。
- 目的:
- 保留细节:拼接比相加保信息更充分;
- 多尺度融合:不同深度的分支看到的“缓慢趋势/局部起伏”不同,拼接能把多种尺度一起带到最后一层。
- 对照:与图像里的 U-Net “跳连”类似,但这里的跳连里还放了 Transformer 编码器,让分支在拼接前已具备“全局上下文”。
(c) Dense Block:轻量“通道混合”与稳定训练
- 内部:FC → BatchNorm → ReLU(可堆叠成若干层),把谱点的特征做非线性投影与归一化,让后续注意力更稳、更好收敛。
- 作用:
- 前端嵌入:把原始谱点投到合适的特征维度;
- 中端整形:在各个 Skip 分支里先做一轮“去噪/整形”,再交给 Transformer 编码器处理全局关系。
(d) Transformer Encoder:全局建模“缓慢基线”
- 标准结构:
- Multi-Head Self-Attention(MHSA)
- 残差“加”和 LayerNorm
- 前馈网络(FC)
- 再一次残差“加”与 LayerNorm ——和经典 Transformer 编码器一致(只是这里是一维光谱 token 序列)。
- 为什么合适做基线:注意力天然是全局的,能让每个波数点在整条谱的上下文里决定自己的“底色”应当是多少;这比只看局部邻域的卷积更贴近“基线=缓慢全局趋势”的先验。0
输出头(Head)
- Concat → Dense Block → FC:把主干与各 Skip 分支拼接后的大特征向量,再过一段 Dense Block 精炼,最后 FC 逐点输出基线(形状仍为 n × channel)。
- 损失:对每个点做回归(论文用 MAE / SAM 做评估;此处是结构描述)。
一句话数据流(和图对应)
- Input (n×c) →
- Dense Block(嵌入/整形)→ Transformer Encoder(全局关系)→ Skip Concat 1 输出挂到上层的 Concat;
- 再堆若干“(Dense Block → Transformer) + Skip Concat”级(图示了 3 个),形成多尺度旁路;
- 顶部 Concat 汇合所有分支 → Dense Block → FC → Output (n×c)(基线)。
4、模型的核心不足与局限
对训练数据多样性的依赖较强
1dTrans 的性能很大程度上取决于训练数据集的代表性。虽然作者收集并增强了多种生物样本的拉曼光谱,但如果未来遇到与训练集差异很大的新样本(例如完全不同的材料、特殊荧光特性),模型的预测准确度可能显著下降。要维持高性能,通常需要重新微调模型或增加特定领域的数据
训练成本高、模型参数量大
与 ResUNet 相比,1dTrans 的参数量大约多 18.7 倍,虽然单次训练时间相近,但要达到最佳性能需要更多训练轮次和更长总时间。这意味着在资源有限或算力不足的场景中,训练和部署成本会更高
对完全模拟数据的泛化不理想
作者尝试过用大规模(10 万条)纯模拟光谱来训练模型,但在真实实验数据上的效果不佳。说明 1dTrans 无法仅依赖模拟数据来获得稳定性能,必须依靠人工标注和真实数据增强,否则在实际应用中可能出现性能骤降
缺乏“即插即用”的通用性
虽然深度学习模型相比传统参数法更省调参,但 1dTrans 仍不算完全“开箱即用”。当应用到新的仪器或不同测量条件时,如果光谱分布、噪声特性发生较大变化,模型可能不适用,需要做额外的微调或重新收集数据进行训练
⚖️ 总结(简单理解)
1dTrans 很强,但有前提条件。 它在已知类型的拉曼光谱上表现非常好,能显著优于传统方法和 ResUNet。但如果数据分布变化大、算力有限或没有人工标注的数据集,模型就可能失效或训练代价过高。这意味着它适合有充足实验数据和计算资源的研究和工业环境,但对需要快速迁移或低成本部署的用户并不算友好。
5、后续改进方向
(1)构建更大规模且多样化的真实数据集
目前 1dTrans 的性能在很大程度上依赖已有数据集的代表性。后续可以持续扩展实验数据来源,引入更多类型的生物材料和测量条件,例如不同仪器型号、不同光谱噪声水平及荧光背景。通过不断丰富训练样本,模型可更好地应对实际应用中的多样性与复杂性,减少因数据分布差异带来的性能下降
(2)开发轻量化与高效的模型结构
现有 1dTrans 模型参数量较大,训练轮数和时间成本较高。未来可尝试模型压缩与轻量化,如引入知识蒸馏、剪枝、低秩分解或混合卷积-Transformer 架构,以在保持精度的前提下降低训练与推理的资源消耗,使模型更易部署在便携式拉曼光谱设备中
(3)探索迁移学习与增量式微调
针对新的材料或测量条件,目前需要重新收集和标注大量数据。未来可考虑迁移学习、增量学习或少样本微调策略,让模型能够在较少数据和较低成本下快速适配新的场景,提高实际应用的灵活性和可扩展性
(4)融合模拟数据与真实数据的混合训练策略
纯模拟数据无法保证模型在真实数据上的良好泛化,但完全依赖人工标注又成本高昂。未来可以将高质量模拟数据与有限的人工标注数据结合,通过生成对抗网络(GAN)、物理约束建模或自适应数据增强方法来弥合两者差距,提升模型对新场景的适用性
(5)引入可解释性和不确定性估计
当前 1dTrans 虽然性能优越,但结果缺乏可解释性。未来可通过可视化注意力权重、构建不确定性评估模块,帮助用户理解模型在不同光谱区域的决策依据,并对低置信度预测进行标记,从而提升结果的可靠性和用户信任度
✨ 总体展望
未来的改进方向将围绕“更通用、更高效、更可信”三点展开。 通过丰富真实数据、优化模型结构、引入迁移学习和可解释性机制,1dTrans 有望从实验室研究走向实际应用,实现对复杂拉曼光谱的高精度、低成本、可扩展基线校正。