ResUNet-1D(2022):使用ResNet和UNet相结合的深度学习模型进行基线校正
1、研究背景和动机
1.1、研究背景
读出噪声
- 比喻:像麦克风在录音时会有“电流滋滋声”。
- 解释:探测器(比如相机里的感光芯片)在把光信号转成电信号时,电子元件本身就会产生一些随机的电噪声,这和有没有光、光强多大关系不大。
- 特点:
- 固定存在,不随光的强弱改变;
- 在光很弱的时候影响特别大,因为信号小,而噪声是固定的。
光子统计噪声
- 比喻:像下雨时你接雨滴,虽然平均每秒可能掉 100 滴,但有时是 98 滴、有时 102 滴,这是随机的。
- 解释:光是由一个个光子组成的,它们到达探测器的数量本来就有随机性,即使光源稳定,也会因为“量子本质”出现上下波动。
- 特点:
- 光越强,光子数量多,绝对波动也会大,但相对波动会变小(因为 10000 个光子波动大约 ±100,比 100 ±10 要更稳定)。
对分析的影响
- 这些噪声让图像或光谱的信号“抖动”、峰值不够稳定;
- 会让后面用来分析成分、识别模式的算法更难得到准确结果。
为了获得可靠的定性和定量结果,必须对原始光谱进行预处理:既要去除背景(基线校正),又要抑制噪声(去噪)。
1.2、传统方法的局限
- 参数拟合型:如多项式拟合、样条插值、形态学滤波等;
- 优化型:如惩罚最小二乘(asPLS、arPLS)、迭代最小二乘。
Savitzky–Golay 平滑 (SG 平滑)
- 原理:在一小段滑动窗口内,用多项式拟合数据,再用这个多项式来平滑信号。
- 优点:能在一定程度上保留峰的形状和高度,比简单的滑动平均更不容易“糊掉”信号。
- 缺点:如果窗口太大或多项式阶数选得不好,容易过度平滑,让尖锐的峰变钝或变低。
小波阈值去噪 (Wavelet Denoising)
- 原理:把信号分解成不同频率的“波包”(小波系数),把低频部分保留,高频部分按设定阈值削弱或去掉,以滤掉噪声。
- 优点:能有效去除高频噪声,对非平稳信号也适用。
- 缺点:阈值选不好会削弱或扭曲峰值,甚至导致信号失真。
🔎 一句话总结: SG 平滑靠“局部多项式拟合”去噪,小波去噪靠“频率分解+阈值”去掉高频噪声。两者如果参数设置不当,都会让本该锐利的峰被削弱或变形。
1.3、深度学习的机遇
2、模型的核心创新点
2.1、 “两条路并行”的智慧——残差 + U 型结构
- UNet 就像修了一条主干道,能先走到山顶(编码看大局),再下山时顺便带回上山时看见的小路细节(跳跃连接)。
- ResNet 像在每一段路边留了“捷径”(残差通道),如果主路太绕,可以直接跨过去,不会迷路。
主干道(UNet)负责看全局起伏,捷径(残差)保证不丢局部细节。 这样模型既能看出整个谱线的“大背景趋势”,又能保留每个峰的细微形状。
2.2 、“会学的放大镜”——用卷积自己学缩放和复原
2.3、 “先学会画出背景,再把它擦掉”——直接回归基线
这就像修照片时,不是一次次调整滤镜,而是 AI 直接帮你画出背景层,扣掉就行。
2.4、“自己造世界来练习”——仿真光谱大规模训练
就像模拟器训练无人车,虽然是假的街道,但能让车学会应对各种情况。
2.5、“轻巧又聪明”——在普通电脑上就能跑
相当于把一个高效的自动修图师放在你电脑里,一次就能处理成百上千条光谱,不用超算也能跑得快。
一句话总结
ResUNet-1D 就像一位受过大量模拟训练的“光谱修图师”,有大视野(U 型结构)、有近视镜(残差细节)、有聪明镜头(卷积缩放),能自动画出并擦掉恼人的背景,让拉曼光谱干净又保真。
3、模型网络结构(ResUNet-1D)
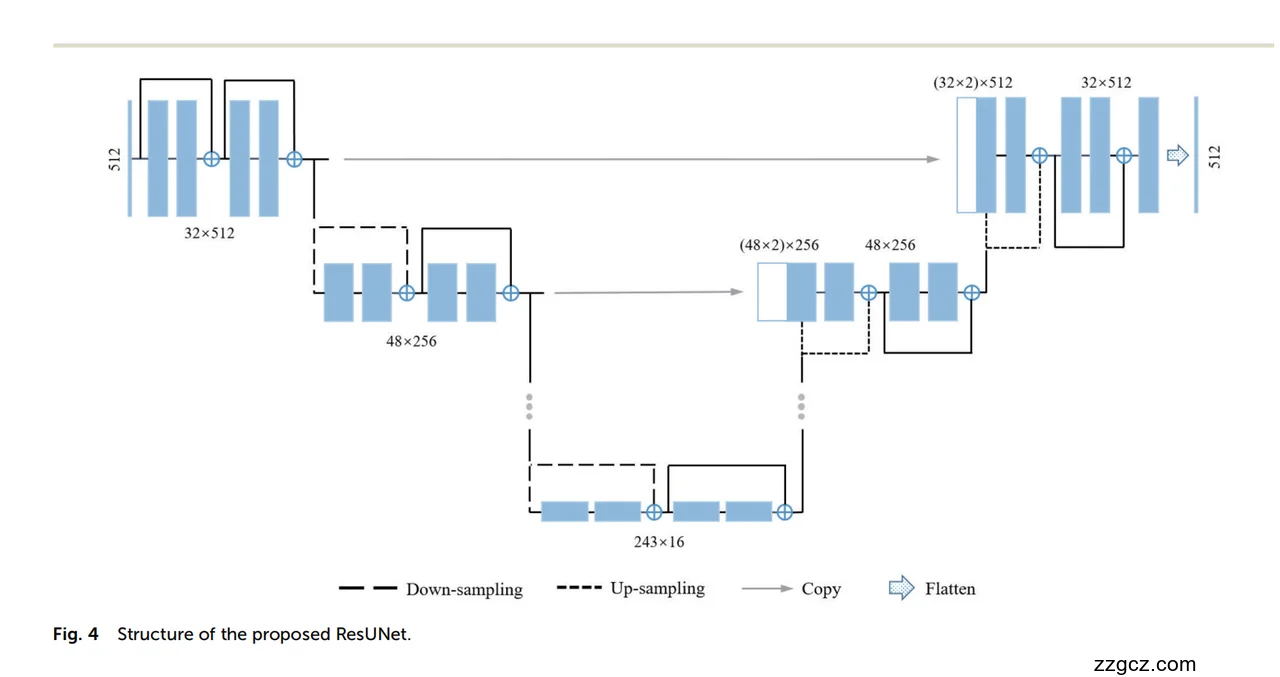
1. 编码器(下采样路径)
- 输入层:首先用一个
Conv1d(卷积核大小 3,步长 1,padding 保持长度)将输入光谱通道扩展到 32 通道,输出尺寸 32 × 512。 - 多级残差块(Block ×4):编码器包含 4 级残差块,每一级由若干
Conv1d + BatchNorm + ReLU组成,并通过**残差短连接(ShortCut)**直接叠加输入和输出。 - 降采样:在每个残差块中,使用卷积步长或专门的卷积层实现下采样,将序列长度依次减半,同时通道数逐步增加:
- 第 1 层:32×512 → 48×256
- 第 2 层:48×256 → 72×128
- 第 3 层:72×128 → 108×64
- 第 4 层:108×64 → 162×32
- 瓶颈层:在最底部再经过一个残差块,输出 243×16 特征,捕获全局基线趋势。
与传统 UNet 不同,这里用卷积下采样代替 MaxPooling,网络可以学习更合理的压缩方式,保留与基线回归相关的信息。
解码器(上采样路径)
- 对称式上采样(Block ×5):解码器逐级使用 转置卷积 ConvTranspose1d 将特征图上采样回原始长度。每一级的上采样结果与编码器同级的特征通过**长跳跃连接(skip connection)**拼接或相加,再经过残差块细化局部信息。
- 243×16 → 162×32
- 162×32 → 108×64
- 108×64 → 72×128
- 72×128 → 48×256
- 48×256 → 32×512
- 这种“长跳跃”保证了在上采样时不丢失编码阶段的高分辨率细节;残差块则保持梯度稳定并进一步提炼局部结构。
输出层
- 解码器末端使用一个 1×1 卷积(Conv1d) 将通道数压缩为 1,直接输出与输入长度一致的基线预测曲线。
- 在推理阶段,用
原始光谱 − 预测基线即可得到校正后的纯净拉曼信号。
参数规模
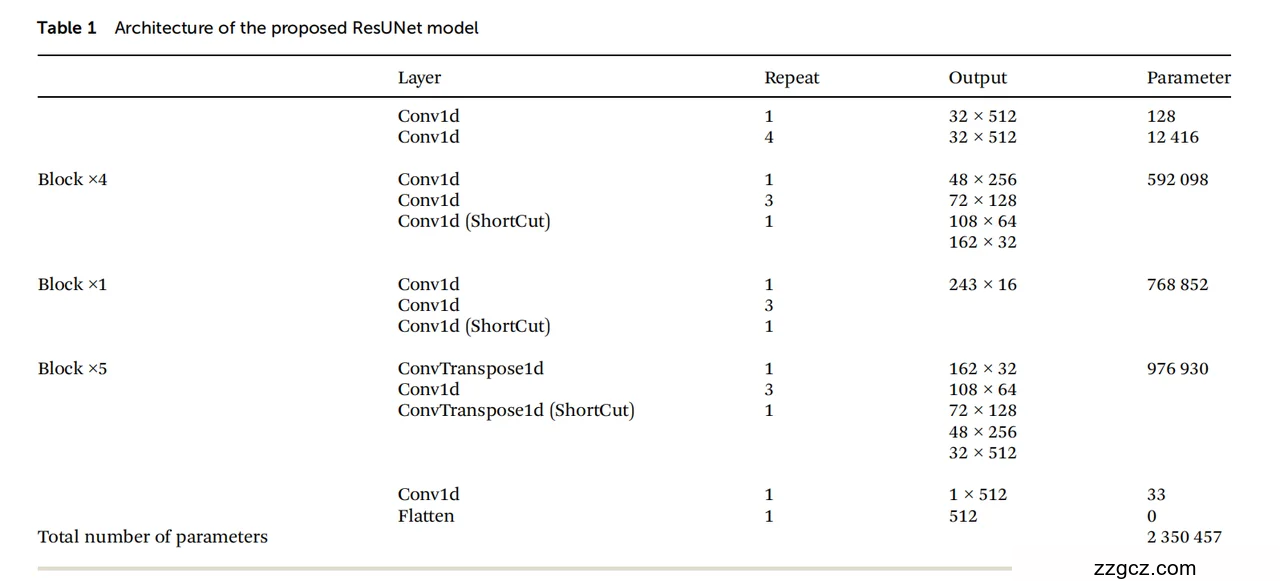
- 编码端 Block ×4 + 瓶颈 Block ×1 共约 2.1M 参数;
- 解码端 Block ×5 约 0.98M 参数;
- 输入、输出头仅占极少量;
- 总参数量约 2,350,457,在桌面级 GPU 上即可快速训练与推理。
结构特点
- 多尺度 + 残差双重跳跃:全局趋势与局部峰形兼顾。
- 卷积式上下采样:相较池化方式,信息丢失少且更平滑。
- 完全一维卷积:针对光谱数据优化,保持波数顺序。
- 轻量化:约 2.35M 参数,适合实验室环境实时处理。
4、模型的核心不足与局限
1. 对输入长度与采样率的适应性差
- 网络在设计时假设输入光谱长度固定为 512,并且训练数据也都是经过归一化与重采样的。
- 如果实际测得的光谱点数不同,或分辨率变化较大,需要额外的重采样或修改网络结构,否则性能会下降。
形象理解:模型像是为“512 格子长”的信号量身定做的尺子,换成不同格数时需要重新刻度。
2. 依赖大量仿真数据,可能存在域偏移
- 模型训练主要依赖人工合成的峰型、基线和噪声。虽然仿真可以覆盖很多情况,但仍可能与实际仪器、样品存在差异。
- 在真实数据上,若背景机理、噪声类型与训练集差别较大,预测基线可能出现偏差,需通过迁移学习或少量真实数据微调。
好比在“虚拟实验室”练习很充分,但真实仪器的光学噪声可能和模拟不完全一样。
3. 只处理基线,不能同时解决去噪
- ResUNet-1D 的输出目标是“背景曲线”,对高频随机噪声没有显式建模。
- 当噪声较强时,虽然网络可能部分平滑,但仍需额外去噪步骤,无法做到“一步到位”完成基线 + 去噪。
相当于它只学会“画背景”,但没有专门学“如何消除杂点”。
4. 泛化到极端复杂光谱可能仍需调试
- 如果谱线同时存在强荧光、陡峭变化、非典型峰形,模型可能无法完美分离背景与信号,需要适当扩充训练集或人工干预。
- 目前网络没有显式的不确定度估计,难以判断何时输出的基线可能不可靠。
5. 推理虽快,但训练仍需显存和时间
- 虽然参数量(2.35M)不算大,但训练时仍需 GPU,且对初学者来说准备仿真数据、调整学习率和训练策略有一定门槛。
总结性一句话
ResUNet-1D 在自动基线校正上精度高、无需人工调参,但仍受限于固定输入长度、合成数据与真实数据的差异、对噪声的处理不足,以及对极端复杂光谱的泛化能力。
5、基于 ResUNet-1D 的后续改进方向
1. 适应不同长度与分辨率 —— 可变长/全卷积输入
- 做法:将网络从固定输入 512 改成完全卷积结构(Fully Convolutional),或使用 全局池化 + 动态上采样,使其能处理任意长度光谱。
- 意义:不同仪器输出的点数不一致时,不需要额外重采样。
像把“只能量衣服 512 码”的尺子,改成可伸缩的软尺。
加入去噪能力 —— 多任务输出或残差噪声学习
- 做法 A:在网络尾部加多任务分支,同时输出“基线”和“去噪后的信号”;
- 做法 B:在训练时加入噪声建模,让网络学会分离高频噪声。
- 意义:从“只修背景”升级为“背景+降噪一体化”,可一步得到干净谱线。
像修图时不光擦背景,还顺便去掉杂点。
改进训练数据策略 —— 半监督 / 域自适应
- 做法:
- 在仿真数据基础上加入少量真实标注光谱,进行微调或领域自适应;
- 使用**对抗训练(GAN)**或 Style Transfer 技术让仿真基线更接近真实仪器特性。
- 意义:减少“虚拟世界学得很好,现实世界有偏差”的问题。
就像让无人车在虚拟道路训练后,再上真实道路微调。
引入注意力机制与更强的特征建模
- 做法:在 UNet 跳跃连接或残差块中加入 通道注意力(SE Block) 或 Transformer 编码器,让模型自适应地关注峰与背景的不同区域。
- 意义:提高复杂基线(如局部剧烈变化、重叠峰)的分离能力。
像给修图师一副“放大镜+聚焦灯”,能精准看见需要处理的部分。
融合物理/化学先验知识
- 做法:在损失函数中加入基线平滑约束(如二阶导惩罚),或把光谱峰的物理模型(洛伦兹/高斯)嵌入网络输出层。
- 意义:让模型不仅依赖数据,还能遵守“基线应平滑、峰形应连续”等物理规律。
相当于在 AI 修图时提醒它“天空一般是平滑的,不要画出锯齿”。
不确定度与可解释性
- 做法:采用贝叶斯神经网络或 Monte Carlo Dropout,输出基线预测的不确定度;或用 Grad-CAM 等方法可视化模型关注的区域。
- 意义:帮助使用者判断模型预测是否可信,避免在异常光谱上盲目使用。
像医生做诊断时会告诉你“这张片子我有 90% 把握”。
一句话总结
未来改进方向可以概括为:
- 更通用(可变长输入、跨仪器适配),
- 更全面(基线+降噪一体化),
- 更聪明(注意力机制、物理约束),
- 更可靠(域适应+不确定度评估)。
6、代码复现
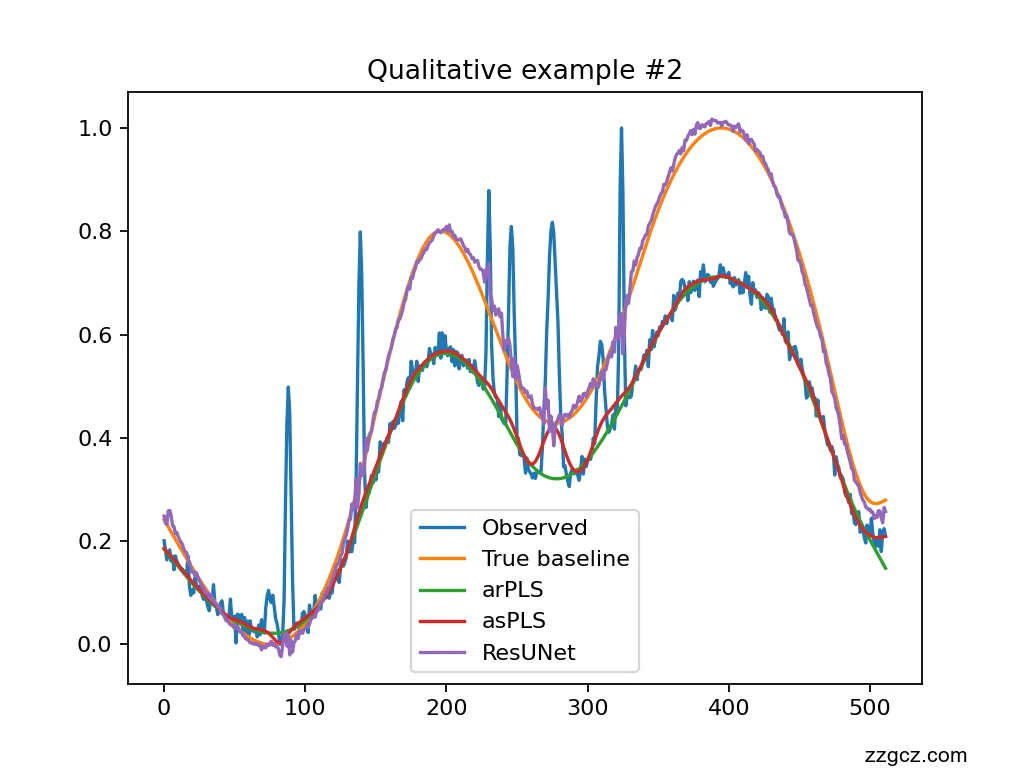
- 这是一个基于 ResUNet1D 的拉曼光谱基线校正复现项目,包含数据合成、模型训练、传统基线算法对比以及可视化评估的完整流程。
- 目录 resunet1d_raman_baseline 下主要包括配置文件、模型实现、数据生成工具、基线算法、训练与评估脚本,以及自动生成的图表与模型权重。
- 所有训练、验证、测试样本都由 resunet1d/data/simulate.py 动态生成,无需外部数据文件。
- 每条光谱长度固定为 512 个采样点(可在配置中修改),由三部分构成:平滑变化的基线、若干随机峰以及高斯噪声。
- 基线通过随机锚点的自然三次样条插值产生,并归一化到 0 到 1 范围。
- 峰值数量、宽度和幅度均在给定区间内随机抽取;峰形采用汉宁窗以模拟拉曼谱特有的光滑尖峰。
- 噪声强度、峰与基线的混合比例、锚点数量等参数由 configs/default.yaml 控制,可按实验需求调整。
- resunet1d/models/resunet1d.py 实现了一维 ResUNet 网络。
- 编码器由多层下采样块组成,每个块包含一维卷积、批归一化和残差子结构,可逐步捕获不同尺度的基线趋势。
- 解码器通过反卷积逐层上采样,并与对应的编码层特征进行跳跃连接,再通过残差块融合信息,保留局部细节。
- 输出通道为 1,对应预测的平滑基线曲线。
- train.py 读取配置文件,生成指定数量的训练与验证样本。
- 使用 NumpyDataset 和 DataLoader 将 NumPy 数组打包成批,支持 GPU 加速训练。
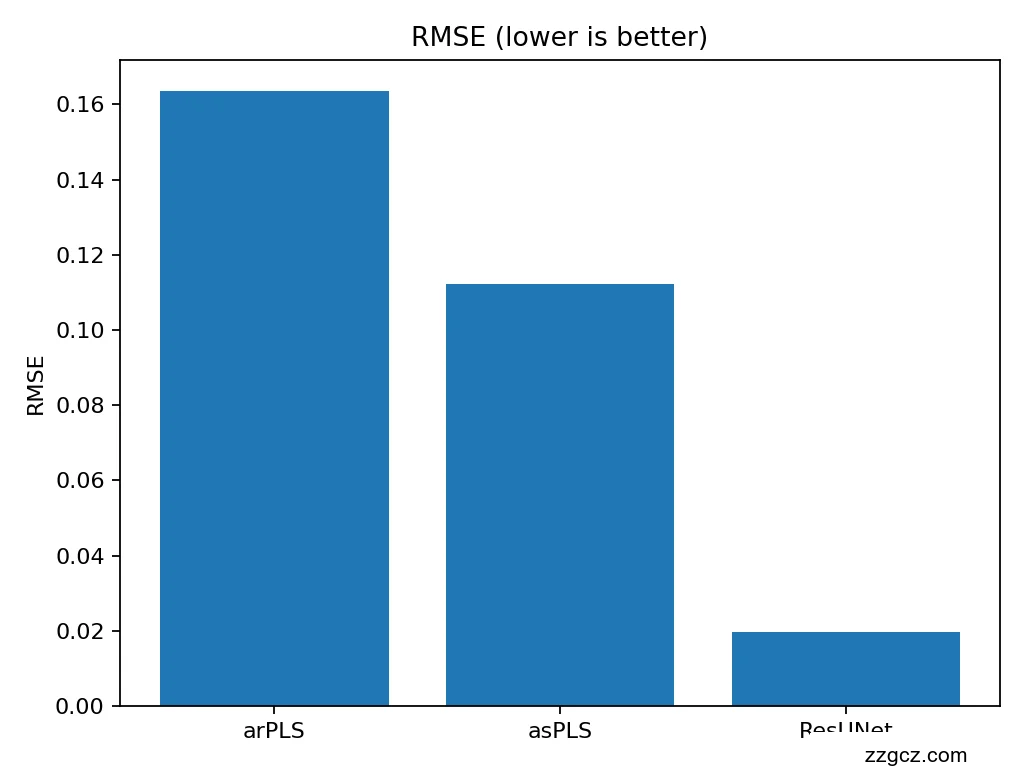
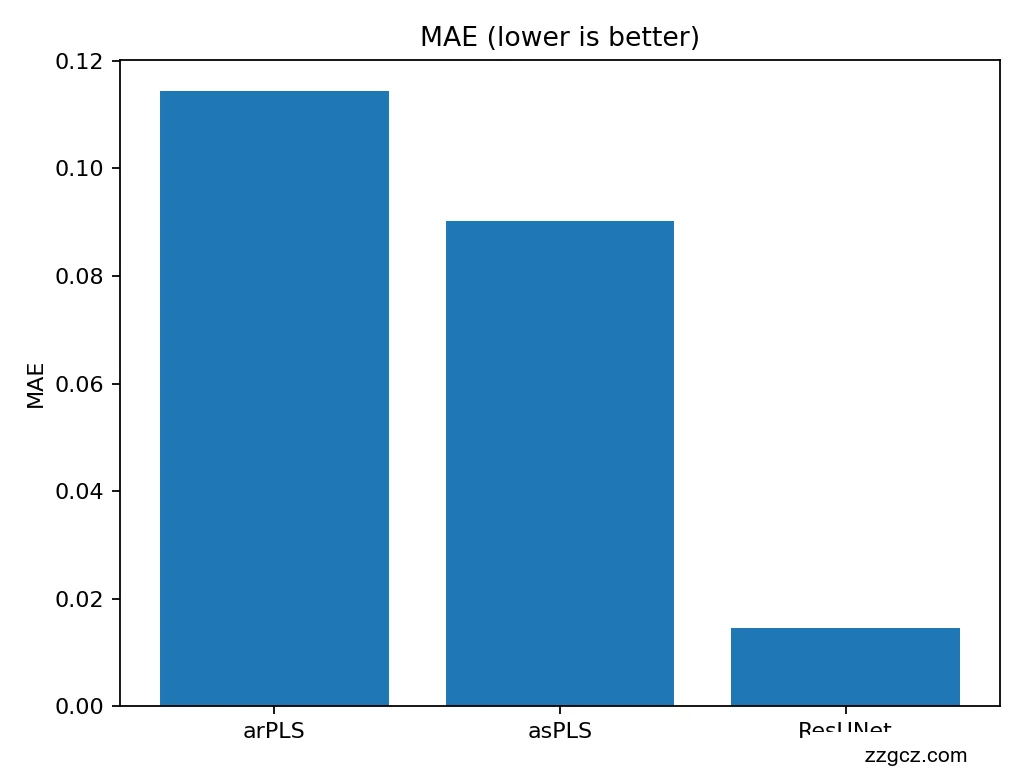
- 优化器默认采用 Adam;损失函数使用均方根误差(RMSE),以衡量预测基线与真实基线的差异。
- 每个 epoch 后在验证集上计算平均绝对误差(MAE),保存表现最好的模型至 best.pt。
- 配置文件中的 optim 部分设定批大小、最大 epoch、学习率、权重衰减以及分段式学习率衰减策略。
- resunet1d/baselines/arpls.py 与 resunet1d/baselines/aspls.py 实现了文献中的 arPLS 和 asPLS 方法,均基于稀疏矩阵求解。
- 在评估阶段,它们用于生成对照曲线,与深度学习模型的输出进行误差统计。
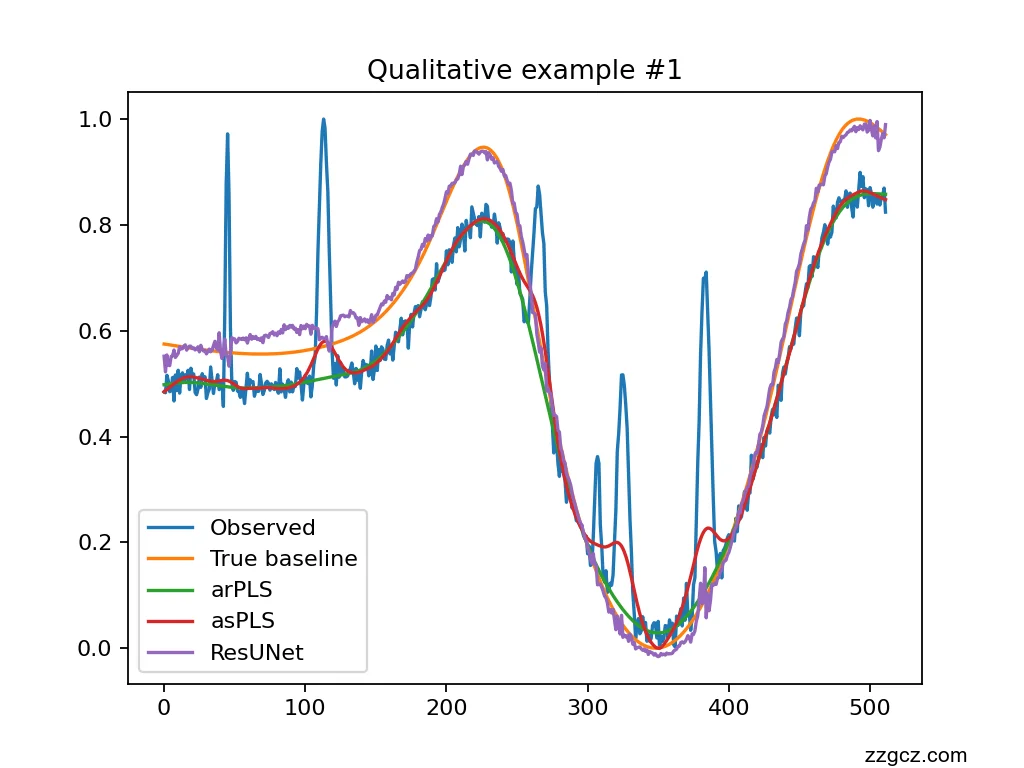
- eval_visualize.py 提供两类结果:定性样例图与整体指标柱状图。
- plot_examples 随机生成两条光谱,绘制观测信号、真实基线、arPLS、asPLS 以及(若加载了检查点)ResUNet 的预测,输出为 fig_qual_1.png、fig_qual_2.png。
- eval_and_bars 批量生成测试集(默认 70000 条),计算各方法的 RMSE 和 MAE 均值,并以柱状图保存为 fig_rmse.png 和 fig_mae.png。
- 通过在命令行提供 --ckpt 参数,可以在定性与定量分析中同时展示训练后的 ResUNet 结果。
- --n_test 参数可用于控制评估样本数,便于在快速调试与最终统计之间切换。
- 项目推荐使用 Python 3.11 虚拟环境,依赖列表在 requirements.txt 中。
- 需要安装带 CUDA 的 PyTorch(项目示例使用 torch 2.6.0+cu124,兼容 CUDA 12.x)。
- 其他依赖包括 NumPy、SciPy、Matplotlib、scikit-learn、pandas、tqdm 等,用于数据处理、科学计算和可视化。
- 在项目根目录创建并激活虚拟环境,安装 requirements.txt 中的所有依赖。
- 运行 train.py 完成模型训练,根据需要调整配置中的样本数量、噪声强度、学习率等参数。
- 训练完成后使用 eval_visualize.py --config configs/default.yaml --ckpt best.pt 生成图表,若只做快速检查可减少 n_test。
- 查阅输出目录下的 fig_qual_*.png、fig_rmse.png、fig_mae.png,了解模型与传统算法在定性、定量层面的差异。
- 如需替换数据生成策略或加入真实光谱,可修改 simulate.py 或扩展 make_dataset 接口,再沿用现有训练与评估脚本。
- 从数据合成到评估均高度自动化,便于复现实验和进行消融。
- ResUNet 架构针对一维信号做了适配,保留了 U-Net 的多尺度优势。
- 评估脚本默认提供经典 baselines,对比清晰,生成的图表可直接用于报告或论文复现说明。
- 配置化设计使得参数调整和实验追踪更为便捷。