cascaded级联网络(2022):级联深度卷积神经网络作为拉曼光谱数据预处理的改进方法
导出时间:2025/11/24 08:58:26
1、研究背景和动机
一、研究背景:为什么要关注拉曼光谱预处理
- 拉曼光谱在生物医学中的潜力
拉曼光谱是一种“非侵入式”“无需染色”就能分析样品分子成分的光学技术,非常适合医学检测。比如:
- 可以直接分析患者组织中是否有癌变;
- 检测胎盘外泌体(EVs)以研究妊娠疾病;
- 对药物或化学物质进行快速成分分析。
这就像“用光照一照,就能看到分子世界”。
- 实际测得的光谱往往不干净
真实的拉曼光谱数据经常受到三大干扰:
- 基线漂移:仪器和样品的背景信号叠加在有用的信号上,像照片上有一层雾;
- 随机噪声:探测器的电子噪声或热噪声让光谱曲线变得抖动;
- 宇宙射线干扰:偶尔会出现非常尖锐的“假信号峰”。
在进行分类或检测前,必须先把这些干扰去掉,这一步就叫“光谱预处理”。
- 传统预处理的局限性
以往的方法像手工修图:
- 需要人工调节很多参数(比如多项式的阶数、平滑系数等);
- 对不同样本需要反复试错;
- 一点点调整就可能意外改变信号里的关键信息。
结果就是 处理慢、依赖专家经验、难以保证一致性和可重复性。
在大规模医学实验或临床应用中,这几乎无法操作。
二、研究动机:为什么要用深度学习,特别是“级联 CNN”
- 用神经网络“自动修图”
深度卷积神经网络(CNN)能够像图像处理一样,从原始光谱中自动学会:
- 去掉背景(基线);
- 平滑噪声;
- 保留真正的化学信号。
理论上可以让科学家不再手工调节参数,实现“一键清洗光谱”。
- 现有深度学习方法的不足
早期有两种尝试:
- 直接用 CNN 分类原始光谱:虽然准确率高,但需要大量训练数据(数万条以上),而医学上样本获取往往很困难;同时模型缺乏可解释性,不利于临床应用。
- 单一 U-Net 或 ResNet 做预处理:可以自动降噪和基线校正,但往往无法很好地分离不同任务,也难与传统方法定量对比。
换句话说,现有模型要么“黑箱”且吃数据,要么处理不够灵活可控。 - 提出“级联式 CNN”的核心想法
作者将基线校正和降噪分成两个独立但相互衔接的深度网络(ResNet 或 U-Net):
- 先用一个网络专门学会去掉复杂的基线;
- 再用另一个网络专门处理噪声和
- 尖锐干扰;
- 中间还设置潜在空间输出,让模型能在每一步保留有用信息并便于解释。
- 这样做的好处:
- 自动化:不再需要专家调参数;
- 更小的数据需求:用模拟生成的大量光谱训练即可,减少真实数据采集压力;
- 可解释性强:处理后的光谱可以被直接分析或用常规机器学习(如 SVM、LDA)分类;
- 对临床友好:适合小数据场景、速度快、结果透明。
✍️ 形象比喻
- 传统预处理 = “手工修照片”:每张都得调曝光、调对比度,费时费力,还可能调坏。
- 以前的深度学习 = “一键美颜”:效果惊艳但不透明,需要大量样本练出来,别人不放心用。
- 级联 CNN = “智能修图师”:先去背景,再去噪点,每一步都清晰可控,照片干净又真实,还能快速批量处理。
2、模型的核心创新点
1. 将“预处理”分成可解释的两步:基线校正 + 去噪
- 第一阶段:基线校正 专门设计基于 ResNet 的网络来消除复杂背景(基线漂移),保持信号峰值不被扭曲。
- 第二阶段:降噪与尖峰去除 独立的网络处理随机噪声和宇宙射线干扰。
这种“任务分工”式的级联设计让网络在每一步都只专注一件事,结果更干净、泛化更好,也便于科学家分析每一步到底做了什么。
🔍 类比:以前是“一个人又扫地又擦桌子”,容易做不干净。现在是“先请一个扫地工,再请一个擦桌工”,各司其职。
2. 加入“潜在空间输出”提高信息保留和可解释性
在两个网络之间,作者增加了潜在层输出(latent space):
- 这个潜在层相当于中间“半成品光谱”,能显示基线被去掉后但噪声还没处理完的样子;
- 让模型在训练中逐步学会如何去掉背景而不丢失真实信号;
- 也帮助研究人员理解模型到底改动了哪些部分,避免黑箱化。
🔍 类比:修图软件加了“历史记录和中间预览”,让你能看到每一步的处理效果,而不是只看到最终成品。
3. 利用 ResNet 与 U-Net 的优势重新设计一维网络
- ResNet 的短跳连接 解决了深层网络训练时的梯度消失问题,使网络可以更深、更稳定地处理复杂基线。
- U-Net 的长跳连接 适合保持细节结构,帮助在噪声去除时保留峰形特征。
作者根据拉曼光谱是一维数据的特点,对原本用于图像的架构进行了调整,包括卷积核大小、步长和张量形态,使其适合光谱信号。
🔍 类比:把一辆越野车(U-Net、ResNet)改造成适合窄轨道的矿道车,专门应对一维的“光谱轨道”。
4. 用大量模拟光谱训练,降低对真实大数据的依赖
- 以往的深度学习方法需要上万条真实光谱,医学上很难获得;
- 作者用随机生成的模拟光谱(加入各种随机基线、噪声、峰型变化)训练网络;
- 这样网络就能适应各种复杂情况,而只需少量真实样本微调或直接使用。
🔍 类比:让AI先在“虚拟赛车”里学会开各种路,再去真实赛道跑几圈就能上手。
5. 一次性实现全自动、快速且高精度的预处理
- 传统方法:需要反复人工调参,每次几秒到几分钟;
- 新方法:训练好模型后,每条光谱处理只要几毫秒;
- 性能:在去基线和降噪方面优于常用的 airPLS、AsLS、iMor、SG、小波等传统方法;
- 结果:让常规机器学习算法(SVM、LDA、KNN)在小数据集上也能接近深度 CNN 的分类精度。
🔍 类比:以前修一张图像要手工调很久;现在是“批量修图秒出结果,还比手工修得更好”。
6. 适合临床和科研的可解释、轻量化工作流
- 输出结果是干净的光谱,医生或科研人员可以直接看峰位、分析化学信息;
- 不再是“黑箱模型直接给出诊断”;
- 支持小数据集训练,特别适合医学场景中样本昂贵或稀少的情况。
🔍 类比:把“黑盒医生”变成“会给你看病历和检查结果的医生”,让科研人员有信心使用。
🌟 核心创新总结
创新点
| 传统方法的问题
| 本文的改进
|
任务分级:基线校正 + 降噪
| 一锅乱炖,容易互相干扰
| 拆分任务,独立优化
|
潜在空间输出
| 模型黑箱,难解释
| 中间输出可视化每步处理
|
ResNet + U-Net 改造
| 原架构为图像设计,不适合一维光谱
| 针对光谱重新设计卷积与连接方式
|
模拟光谱训练
| 真实数据不足,成本高
| 大量虚拟数据训练,降低需求
|
自动化与高效性
| 人工调参慢且不可重复
| 全自动、毫秒级处理、结果稳定
|
临床友好
| 黑箱预测不被信任
| 输出可解释光谱,支持常规 ML
|
3、模型网络结构
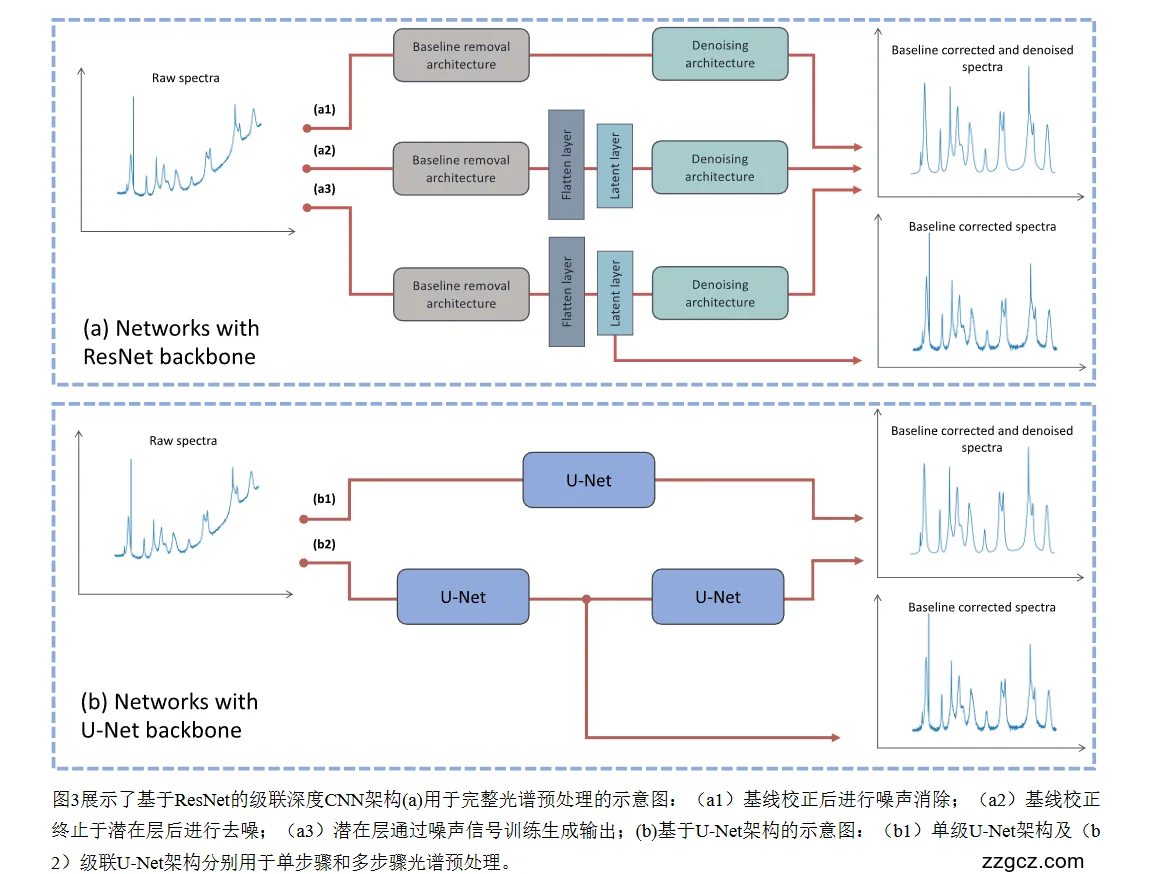
一、总体思路:级联两步走
这套模型不是一个“大杂烩”式的单网络,而是两阶段级联结构:
- 第一阶段:基线校正(Baseline Removal) 目标:去除光谱中缓慢变化的背景,使峰形更清晰。
- 第二阶段:去噪与尖峰干扰消除(Denoising) 目标:进一步清理随机噪声、尖锐的宇宙射线干扰,得到干净的光谱。
这种两步走的优势是:每个子网络只处理一种干扰,效果更稳定,可解释性更好。
二、两种主干网络设计
论文提出两条不同的“骨干(backbone)”实现方案,你的图中正是这两类:
1️⃣ ResNet 级联结构(图 (a))
- 输入:原始拉曼光谱(Raw spectra)
- 第一模块:Baseline removal architecture
- 使用 ResNet(残差网络)作为主体。
- 残差连接(skip connection)可以缓解梯度消失,让网络更深也能训练。
- 目标:学习如何拟合并消除基线背景。
- 中间潜在层 (Latent layer)
- 类似“中间结果”,保留去基线后的光谱。
- 可选择直接输出基线校正光谱,供分析或下游机器学习使用。
- 第二模块:Denoising architecture
- 同样是基于 ResNet 的结构,输入是中间结果。
- 学习如何去掉高频噪声、尖锐干扰。
- 输出:
- 可以得到两种结果:
- 仅基线校正后的光谱;
- 同时去噪后的最终光谱。
- 可以得到两种结果:
🔍 图中的 (a1)、(a2)、(a3) 表示三种不同的使用方式:
- (a1) 先去基线,再去噪;
- (a2) 去基线后在潜在空间连接到去噪模块;
- (a3) 用潜在层直接生成输出。
2️⃣ U-Net 级联结构(图 (b))
- 输入:原始光谱
- U-Net 架构特点:
- 编码器(下采样):提取光谱的全局趋势和背景信息;
- 解码器(上采样):重建去除背景/噪声后的信号;
- 长跳连接(skip connection):保持细节(峰形)不被破坏。
- 单级 U-Net(b1): 一次性完成基线去除和降噪。
- 多级 U-Net(b2):
分两次处理:
- 第一个 U-Net 专门去基线;
- 第二个 U-Net 再做降噪。
这种设计更适合数据量不大、希望保持峰形完整的场景。
三、关键细节
- 1D 卷积替代 2D
- 原本的 ResNet/U-Net 是给图像用的(2D 卷积),
- 作者针对光谱信号改成 一维卷积(1D CNN),以适应光谱数据的序列性质。
- 潜在空间的多输出设计
- ResNet 版本里,网络可以在中间阶段输出“仅基线校正”版本,方便科研人员直接使用。
- 对临床和分析工作友好:如果只需要去掉背景,不一定要走完第二阶段。
- 训练策略
- 利用模拟生成的大量光谱数据(加入随机基线、噪声、峰型变化)训练;
- 再用少量真实数据微调或直接评估,减少对真实大数据集的依赖。
四、整体工作流程(用生活比喻)
像照片修复:
- ResNet/U-Net 1 = 自动“去雾和调光” → 去掉背景基线;
- 潜在层输出 = 修完底图后可以先看一眼半成品;
- ResNet/U-Net 2 = 专门“去噪点、去划痕”;
- 最终图像 = 清晰、无噪声的光谱数据,可直接做分析或分类。
五、结构优点总结
特性
| ResNet 级联
| U-Net 级联
|
核心优势
| 残差结构适合深度去基线,训练稳定
| 跳连接保留峰形,重建能力强
|
可解释性
| 有潜在层,可中途输出结果
| 简洁但黑箱感稍强
|
适用场景
| 噪声和基线都复杂;需要分步可视化
| 数据量较少、希望保持峰形
|
处理速度
| 快,结构相对轻量
| 稍慢但重建精细
|
✨ 一句话总结
该模型通过 “两步走的级联 CNN + 可中途查看的潜在层”, 将原本繁琐、依赖人工调参的拉曼光谱预处理过程自动化、结构化, 并可选择 ResNet 或 U-Net 主干来适应不同的实验需求。
4、模型的核心不足与局限
4.1 大量依赖模拟数据
- 作者主要用模拟生成的光谱来训练模型(随机添加基线、噪声、峰形)。
- 虽然这样解决了真实样本稀缺的问题,但模拟数据与真实实验数据之间存在域差异:
- 仪器噪声和生物样本中的化学背景往往比模拟更复杂;
- 当实际光谱的分布与训练时假设的分布不同时,性能可能下降。
🔍 影响:模型在真实临床数据上的泛化能力需要更多验证。
4.2 对小样本微调仍需要经验
- 虽然减少了大规模真实数据的需求,但如果换仪器或样本类型(例如从胎盘外泌体到血液样本),模型仍可能需要重新微调。
- 迁移学习流程、如何选择微调数据量,作者未给出明确指导。
4.3 两阶段串联带来延迟和复杂度
- 级联的两步处理(基线→去噪)比单一模型更复杂:
- 推理时需要经过两次前向传播;
- 训练时需要分别优化两个子网络。
- 在实时分析或大规模在线检测中,可能不如单阶段轻量模型高效。
🔍 影响:在工业在线检测场景,速度可能仍是瓶颈。
4.3 潜在空间虽然提高解释性,但依旧是黑箱
- 中间输出只是提供“视觉上可看”的光谱,并不能解释模型内部如何做出每一步修正;
- 仍缺乏真正的可解释性分析(如特征归因、注意力可视化)。
- 对临床用户来说,这比传统手工预处理方法的“公式和参数”依然不够透明。
4.4 网络参数量较大
- ResNet/U-Net 都是比较深的卷积架构,相比一些传统方法(如 airPLS、iMor)对计算资源和显存要求更高;
- 如果在嵌入式光谱仪或边缘设备上部署,会面临资源受限问题。
对比实验的局限
- 虽然与常见的预处理算法(airPLS、iMor、SG、小波等)做了比较,但与其他深度学习预处理模型的系统性对比不足;
- 对最终分类任务的改进,作者主要测试了传统 ML 分类器(SVM、LDA),未对比端到端的深度分类器在同样数据量下的性能,因此难以完全量化预处理对下游深度学习的价值。
5、后续改进方向
一、近年改进/替代模型方向概览
在级联 CNN 预处理模型之后,后续工作主要沿着以下几个方向演进:
年份
| 模型 / 方案
| 主要用途 / 创新点
| 与级联 CNN 或注意力 / Transformer 的关系
|
2023
| Raman ConvMSANet
| 融合一维卷积 + 多头自注意力 (multi-head self-attention) 机制进行光谱处理 / 分类
| 在传统 CNN 基础上加入注意力模块,使模型能“关注重要频点”的能力加强。
|
2023
| RamanNet
| 引入 shifted MLP + 稀疏连接,克服 CNN 在光谱上的平移不变性问题
| 这是更加偏结构创新 + 模型设计方向的尝试,避开单纯卷积方式的局限性。
|
2024
| RSPSSL(Raman Spectral Preprocessing via Self-Supervised Learning)
| 自监督预处理方案,用 “背景估计补丁 CNN (RSBPCNN)” 等模块进行基线校正 + 去噪
| 强调“无需人工干预 / 通用性 / 高保真度”的预处理,在模型设计上兼顾卷积与 patch 处理思想。
|
2024
| “Denoising + Baseline Correction via Convolutional Autoencoder”
| 使用卷积自编码器(CAE / CDAE)做去噪 + 基线校正的统一模型
| 虽然不是 Transformer,但代表“把两个阶段(基线 + 噪声)融合到一个端到端模型”的趋势。
|
2024
| TMNet(混合 Transformer 网络)
| 在表面增强拉曼 (SERS) 频谱分类 / 识别任务中,将 Transformer 编码器与多层感知机 (MLP) 结合
| 主要用于分类 /识别层面,但它把 Transformer 引入频谱处理 /特征提取流程。
|
2024
| Deep-learning-based acquisitional denoising with Transformer
| 在 Raman 光谱获取 / 采集过程的去噪任务中尝试 Transformer 模型
| 这个工作是比较接近用 Transformer 做预处理 /处理噪声的尝试。
|
下面挑几个比较有代表性的方法详细聊聊它们怎么“在级联 CNN 上改进”。
二、几个典型改进模型详解
6、重点模型 / 方案解析
1. Raman ConvMSANet (2023)
- 论文 / 出处:A High-Accuracy Neural Network for Raman Spectroscopy (Ren et al., 2023) ACS Publications
- 主要结构:一维卷积 + 多头自注意力 (MultiHead Self-Attention, MSA)
- 首先用卷积抽取局部特征(峰型、局部形状);
- 然后用自注意力模块让模型能够“关注”频谱中的重要频点,提升全局信息建模能力。
- 优点 / 可能改进:
- 注意力机制可以捕捉远距离点之间的依赖,有助于识别相互干扰、重叠峰或复杂背景关系;
- 相对于纯卷积,模型更加灵活,可能在多尺度 / 非局部结构上表现更好。
- 局限 /挑战:
- 引入注意力后,计算量 /内存开销上升;
- 在极低信噪比或极端干扰背景下,注意力模块可能容易被噪声引导。
2. RamanNet (2023)
- 论文 / 出处:RamanNet: a generalized neural network architecture for Raman spectroscopy SpringerLink
- 设计思路:
- 认为光谱与图像 / 时序信号不同,不应盲用卷积 “平移不变性” 假设。
- 引入 shifted MLP 结构 + 稀疏连接,来兼顾特征提取能力与保留局部特性。
- 创新点:
- 在早期层用 MLP 而非卷积提取跨谱点特征;
- 使用稀疏连接、跳层结构来模拟卷积优势但避免不适合的平移假设。
- 与级联 CNN 的关系:
- 它不是典型的“预处理网络”,更偏向于可泛化的整体谱分析模型;
- 如果在未来将预处理与 RamanNet 结合,可能出现“不做预处理 / 直接建模”的趋势。
3. RSPSSL & RSBPCNN (2024)
- 论文 / 出处:RSPSSL: A novel high-fidelity Raman spectral preprocessing scheme Nature
- 主要思路 / 结构:
- 自监督训练:构造多源多样本的训练数据集(包含不同设备 / 样本 /背景类型),以训练一个通用的预处理模型;
- 预处理模型命名为 RSBPCNN(Background-Estimation-Patches CNN),它在设计上考虑了“光谱-物理成分关系”的 patch 分割策略 + 局部 /全局融合。
- 采用两阶段结构:第一阶段做背景估计,第二阶段做去噪与细节恢复。
- 性能 /亮点:
- 在速度上表现优越,可达到 ~1900 条/秒的处理速度;
- 在多个设备 / 实验室数据集上表现鲁棒,减少设备间 /样本间差异的影响;
- 在一些医学 /生物应用中显著提升分类 /定量性能(例如癌症诊断 AUC 提升)。
- 评价 /潜在挑战:
- 自监督预训练依赖训练集的多样性覆盖性,如果新设备 /样本类型不在训练分布内,可能性能下降;
- 模型复杂度与部署成本可能较高,尤其是在光谱仪端或低算力设备上。
4. 混合 Transformer / TMNet (2024)
- 出处 /背景:在 SERS(表面增强拉曼光谱)识别任务中,有论文提出使用混合 Transformer + MLP 结构,即 TMNet。科学直通车
- 思路:
- 在光谱分类 /识别任务中,将 Transformer 的编码器用于特征表示,后接 MLP 进行分类;
- 虽然主要用途是识别 /分类,但它体现出 Transformer 在频谱特征提取中的可用性。
- 意义:
- 表明 Transformer 不仅能用于图像 / NLP,也逐步被用于光谱特征学习;
- 在未来的预处理 /降噪 /基线校正任务中,可能有更多论文尝试将 Transformer 模块插入或替代卷积模块。
5. Deep-learning based acquisitional denoising with Transformer (2024)
- 出处 /场景:在试图对光谱采集过程中的噪声进行去噪处理时,部分研究引入 Transformer 模型。SPIE Digital Library
- 特点 /挑战:
- 去噪任务是预处理的一部分,这类工作尝试直接对原始采样信号做噪声抑制;
- 引入 Transformer 可以更灵活地对整条谱线作全局建模,而不仅是局部卷积;
- 但由于噪声的随机性、幅度差异、频率成分复杂,引入 Transformer 成本 + 不稳定性是个挑战。
6. Convolutional Autoencoder 统一预处理 (2024)
- 出处 /论文:Denoising and Baseline Correction Methods for Raman Spectroscopy Based on Convolutional Autoencoder: A Unified Solution MDPI
- 主要做法:
- 使用 卷积去噪自动编码器 (CDAE) 来做噪声抑制;
- 使用改进版 CAE+ 来做基线校正(在解码后附加对比 /调整模块以更好地拟合基线)
- 两者可组合为一个统一流程(去噪 + 基线校正)
- 与级联 CNN 的联系 /区别:
- 与级联 CNN 的“两个独立网络串联”思想类似,但这里更加强调一步到位、端到端训练;
- 相对于 Transformer /注意力模型模型而言,仍然相对轻量、稳定;
- 在实际性能上,这类 autoencoder 方法在模拟/实验谱上展示了比传统算法(如多项式拟合、ALS)更好噪声还原与峰保留效果。
7、总结与未来趋势预测
从这些改进可以看出,基于级联 CNN 的预处理模型向以下几个方向发展:
Transformer / 注意力机制 正在渗透
- 虽然目前将 Transformer 完全用于基线校正 + 去噪的预处理部分的研究还不多见,但越来越多研究把 Transformer 用作特征提取或分类模块(如 TMNet、Raman ConvMSANet);
- 未来的趋势可能是 “卷积 + 注意力混合模块插入预处理网络” 或 “Transformer 作为主干网络替代部分卷积结构”。
自监督 / 预训练 成为重要方向
- 像 RSPSSL 这样的自监督预处理方案,能够减少对人工标注 /仿真数据的依赖,增强跨设备 /跨样本的通用性;
- 在未来,可能出现更强大的预训练预处理模型,可用于零样本 /少样本光谱任务。
端到端 / 一体化结构更受青睐
- 级联 CNN 的“两步走”思路好在清晰模块分工,但有一定复杂度开销;
- 趋势可能是将基线校正、去噪、特征提取、分类 /定量等模块融合成一个端到端可训练网络。
轻量化 /边缘部署 /实时性要求加强
- 在光谱仪器端或现场检测场景,需要在算力 /内存受限环境下运行模型;
- 模型压缩、剪枝、知识蒸馏、量化等技术可能会与预处理网络结合。
跨设备 / 跨域鲁棒性成为试金石
- 新模型是否能在不同光谱仪、不同样本类型、不同实验室间通用,是衡量其实用性的重要标准;
- 自监督 /多源训练 /域适应 (domain adaptation) 方法可能成为关键技术。