BERT(2019):双向预训练,语言理解革命
1、研究背景与动机
🧩 一、研究背景:从“任务专属”到“通用语言理解”
每个下游任务(如情感分析、问答、命名实体识别)都需要单独设计和训练模型。
- 每个任务都要收集标注数据(成本高)。
- 模型结构差异大(难以迁移)。
- 不同任务都要“重新学”语法、语义、共现关系等语言规律。
- 模型无法真正掌握语言本身的“共通知识”。
“能不能像人那样,先通过阅读大量文本学会语言规律,再针对任务进行微调?”
📚 二、前期尝试:从 word2vec 到 ELMo,再到 GPT
阶段
| 代表模型
| 核心思想
| 局限
|
词向量阶段(2013)
| word2vec / GloVe
| 学词语的静态语义向量
| 每个词只有一个向量,无法区分语境(“bank” 问题)
|
上下文表示阶段(2018)
| ELMo
| 使用双向 LSTM 得到上下文词向量
| 结构复杂、无法完全双向建模
|
单向语言模型阶段(2018)
| GPT
| 用 Transformer 预测下一个词(左到右)
| 只能从左到右读,无法同时理解前后文
|
让机器理解语言结构,而不仅仅是记词向量。
- 无法充分利用上下文的双向信息。
- 语言理解往往依赖“前后语境”,单向模型很容易漏掉关键信息。
💡 三、BERT 的动机:让机器真正“理解整句话”
“我们需要一个真正的 双向语言模型(bidirectional language model), 能同时从左、右两个方向理解句子。”
- 像人一样理解整句语义;
- 用大规模无监督语料学习语言知识;
- 一次预训练,多任务通用(one model fits all)。
⚙️ 四、关键理念:预训练 + 微调(Pre-train → Fine-tune)
- 在海量无标注文本上,通过设计自监督任务让模型学语言规律。
- 类似“读书阶段”:先积累知识,不针对具体任务。
- 在特定任务(如分类、问答)上用少量标注数据进行微调。
- 类似“考试阶段”:带着学到的知识做题。
💬 这相当于让 NLP 模型第一次具备了“通用理解能力”, 而不是每次都从零开始学。
🚀 五、技术动机:解决前人模型的三大问题
过去模型的问题
| BERT 的创新解决方案
|
1️⃣ 单向理解(只能左到右)
| 提出 Masked Language Model (MLM),随机遮盖部分词,强制模型同时利用左右文预测被遮住的词,实现深度双向理解。
|
2️⃣ 缺乏句间关系建模
| 提出 Next Sentence Prediction (NSP),让模型学习句子之间的逻辑关系(例如问答、推理、摘要)。
|
3️⃣ 模型参数难迁移
| 采用 Transformer Encoder 结构,使同一预训练模型可直接微调到多种下游任务。
|
🌍 六、研究目标总结
让机器真正“读懂”文本,拥有可迁移的语言理解能力。
- 建立一个双向上下文理解的预训练模型;
- 提供统一的、可微调的语言表示框架;
- 用最小的任务特化改动实现最佳性能。
BERT 的研究动机是打破单向语言建模的局限,通过双向 Transformer + 预训练框架,让机器真正具备像人一样“从前后语境共同理解语言”的能力。
2、模型的核心创新点总结(含 MLM 与 NSP 详解)
(1)“深度双向”的统一编码器
(2)Masked Language Model(MLM):实现真正双向建模
MLM 的具体做法(80/10/10 规则)
- 选中约 15% 的位置作为预测目标;
- 其中 80% 用特殊符号 [MASK] 替换;
- 10% 换成随机词;
- 10% 保持原词不变(让模型不过度依赖 [MASK] 形态)。 这样模型不知道哪些位置会被问到、哪些被随机替换,被迫为每个 token维持上下文表示;代价是每批次只有 15% 位置参与预测,训练步数需要更久一些。
(3)Next Sentence Prediction(NSP):显式学习句间关系
作用验证:消融实验显示,去掉 NSP 或改成左到右 LM(无 NSP)都会整体拉低多项下游指标,说明“双向 + 句间建模”的组合是性能关键。
(4)输入表示的“三件套”: [CLS]/[SEP] + Segment + Position
- [CLS] 置于序列首,作为句对/单句的整体表示;
- [SEP] 分隔句子 A 与句子 B;
- 叠加 Segment Embedding(区分 A/B)与 Position Embedding(相对位置信息)。 这一设计让同一模型自然覆盖“单句、句对、问答起止”等多种范式,并在微调时直接复用。
(5)“预训练→微调”的通用范式落地
- 预训练阶段:用 MLM + NSP 在大语料上学习语言知识;
- 微调阶段:在下游任务上端到端更新全部参数,仅换任务头即可。 这使它在句子级与 token 级一系列任务上刷新 SOTA,并显著减少对“重工程化任务结构”的需求。
小结(一句话)
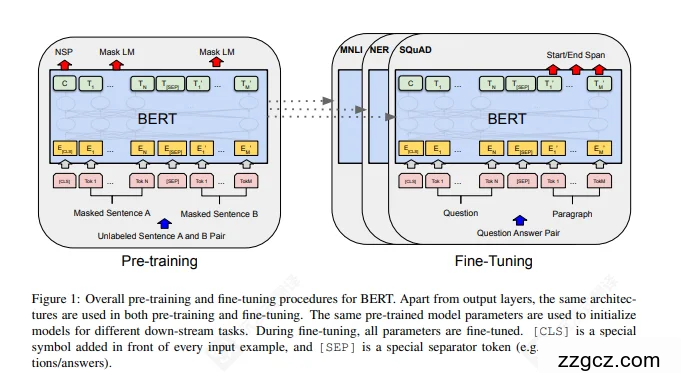
3、模型的网络结构(含图解 + 流程讲解)
🧩 一、整体框架:预训练 + 微调 的“两阶段一体系”
- Pre-training(预训练阶段):模型在大规模无标注语料上,学习语言规律。
- Fine-tuning(微调阶段):把预训练好的参数迁移到具体任务上,只加一个简单任务层即可。
BERT 在两阶段使用的是同一套 Transformer 编码器结构,参数共享! 也就是说——预训练学语言,微调学任务,但“脑子”是同一个。
🧠 二、核心结构:多层 Transformer Encoder 堆叠
- 让每个词都能与句中其他所有词建立联系。
- 模型通过注意力权重来理解哪些词互相关联(例如“he”指代谁、“bank”是哪个含义)。
- 对每个词的表示进行非线性变换,提升特征表达能力。
🧩 三、输入层设计:统一的“句子打包”结构
类型
| 作用
| 示例
|
Token Embedding
| 表示每个词的语义
| “I”, “love”, “NLP”
|
Segment Embedding
| 区分句子 A / 句子 B
| A=问题, B=回答
|
Position Embedding
| 编码词序信息
| 第1词、第2词…
|
- [CLS]:放在句首,代表整句或句对的全局语义,用于分类任务;
- [SEP]:用来分隔两个句子,或标记句末。
🔍 四、预训练阶段(Pre-training)
(1)Masked Language Model(MLM)
- 输入中随机遮盖一些词(用
[MASK]替代); - 模型必须根据上下文去猜出原词是什么;
- 例如输入:“the [MASK] barked loudly”,模型学到“dog”。
(2)Next Sentence Prediction(NSP)
- 输入由两个句子组成(A 和 B);
- 模型要判断 B 是否是 A 的真实下一句;
- 例如:
- ✅ “I went to the park. It was beautiful.” → True
- ❌ “I went to the park. The stock market crashed.” → False
🧩 五、微调阶段(Fine-tuning)
- 保留预训练的 Transformer 权重;
- 在顶部添加一个轻量任务层(如分类、序列标注、问答 span 预测)。
任务类型
| 输入示例
| 输出结构
| 微调策略
|
句子分类(如情感分析)
| 单句输入
| 用 [CLS] 向量接 softmax 分类
| 更新全部参数
|
句子对任务(如自然语言推断 MNLI)
| 句 A + 句 B
| [CLS] 作为句对表示
| 分类层预测关系
|
序列标注(如命名实体识别 NER)
| 单句
| 每个 token 经过线性层预测标签
| Token 级 softmax
|
阅读理解(SQuAD)
| 问题 + 段落
| 输出起始/结束位置概率
| 预测答案 span
|
⚙️ 六、运行流程总结
输入文本(单句或句对)
│
┌─────────┴─────────┐
│ [CLS] + tokens + [SEP] │
└─────────┬─────────┘
│ (三层嵌入相加)
▼
多层 Transformer Encoder
│
┌─────────┴─────────┐
│ [CLS] 表示全局语义 │
│ token 表示上下文词义 │
└─────────┬─────────┘
▼
预训练任务(MLM, NSP) 或 任务层(分类/问答)
🔍 七、为什么这种结构强大?
✅ 一句话总结
BERT 的网络结构 = 多层 Transformer Encoder + [CLS]/[SEP] 输入设计 + MLM + NSP 预训练 + 通用微调框架。 它的精髓是: “用同一个双向 Transformer 学会语言,再把这个理解迁移到所有下游任务。”
4、模型的优势、不足与改进方向(含与 GPT、ELMo 对比)
🌟 一、模型的核心优势
1️⃣ 真正的“深度双向理解”
- 以往语言模型如 GPT、ELMo 只能从左到右或双向拼接,但并非“深度双向”;
- BERT 通过 Masked Language Model (MLM) 实现了在同一层同时整合左、右文信息, 即每个词都能看到整个句子的上下文;
- 这让模型理解更准确,尤其在代词指代、歧义消解、句子依赖等任务上表现突出。
💬 举例:句子 “He went to the bank to deposit money”
- 传统单向模型看到 “bank” 时还不知道是“河岸”还是“银行”;
- BERT 同时看到 “deposit money”,就能判断是金融意义。
2️⃣ “预训练 + 微调”范式彻底改变了 NLP 的工作方式
- 在 BERT 之前,研究者需要针对不同任务设计专用结构(情感分析、问答、NER 等都不同)。
- BERT 提出统一的预训练语言表示框架:
- 一次预训练 → 多任务直接微调。
- 这相当于让机器有了“通用语言知识”,只需小量标注数据就能快速适应任务。
🧠 类比:BERT 就像一个读过成千上万本书的学生,只需简单训练,就能应对各种考试。
3️⃣ 引入两大自监督学习任务(MLM + NSP)
- MLM 让模型学会词级上下文依赖;
- NSP 让模型学会句间关系和语篇逻辑;
- 两者结合,使 BERT 能同时处理句子内、句子间的理解任务;
- 例如,在问答或自然语言推断(NLI)中,模型能区分 “因果” 与 “无关” 的句子关系。
4️⃣ Transformer 架构的强表达能力
- BERT 采用纯 Transformer Encoder 结构,无需 RNN;
- 自注意力机制可在一次计算中捕捉所有词之间的依赖关系;
- 训练与并行效率远高于 LSTM/GRU;
- 模型层数深(12 或 24 层)但仍能高效收敛,支持大规模预训练。
5️⃣ 实证性能革命
- 在 11 项 NLP 任务(如 GLUE、SQuAD、SWAG 等)上刷新 SOTA;
- 比 GPT、ELMo 提升幅度高达 10–20 个百分点;
- BERT 预训练模型(如
bert-base-uncased)成为后续众多模型的通用“起点”。
⚠️ 二、模型的主要不足与局限性
1️⃣ 预训练成本极高
- BERT-Base 使用了 16 个 TPU,训练 4 天以上;BERT-Large 更是 340M 参数;
- MLM 训练时仅 15% token 被预测,效率偏低;
- 对计算资源要求极高,学术界和中小企业难以复现原始训练。
2️⃣ Mask 机制导致训练/预测不一致
- 在预训练时,模型看到
[MASK]符号,但在微调或推理时不会出现; - 这种 Train–Test Gap(训练–测试不匹配) 会影响模型泛化;
- 后续模型(如 RoBERTa)完全取消了 NSP,并通过更大语料和动态 Mask 改进了效果。
3️⃣ 输入长度限制(最多 512 个 token)
- Transformer 的注意力机制是二次复杂度 O(n2)O(n^2)O(n2),序列一长就爆显存;
- 因此 BERT 无法处理长文档、长对话或整篇论文;
- 后续如 Longformer、BigBird、Transformer-XL 针对这一问题做了改进。
4️⃣ NSP 效果有限
- 后续实验证明 NSP 并非总是提升性能;
- 某些任务(如句对匹配)中 NSP 信号过弱;
- 许多改进模型(如 ALBERT、RoBERTa)直接移除 NSP,而用句间连续性学习替代。
5️⃣ 模型可解释性弱
- BERT 是“黑箱式” Transformer;
- 注意力权重虽可视化,但并不等于因果解释;
- 很难解释模型“为什么”做出某个判断。
🔧 三、后续改进与优化方向
1️⃣ 结构优化类
改进模型
| 特点
|
RoBERTa (2019)
| 移除 NSP、更大批次、更长训练、更动态 Mask,性能显著提升
|
ALBERT (2019)
| 参数共享 + 分解嵌入矩阵,参数减少 10 倍但性能相近
|
DistilBERT (2019)
| 通过知识蒸馏减小模型体积,保留 95% 性能仅需 60% 速度
|
ELECTRA (2020)
| 用“替换词检测”取代 MLM,极大提升训练效率
|
DeBERTa (2021)
| 解耦位置与内容注意力,进一步提升性能
|
2️⃣ 长文本扩展类
- Longformer / BigBird / Transformer-XL / Reformer 通过稀疏注意力或记忆机制降低复杂度,使 BERT 能处理几千词的长序列。
3️⃣ 多模态与跨语言扩展
- VisualBERT、VL-BERT、XLM-R、mBERT 等将 BERT 推向图像理解、多语言和跨模态领域;
- 实现了从文本到图像、音频、视频的统一表征学习。
⚖️ 四、与 ELMo、GPT 的对比总结
对比维度
| ELMo (2018)
| GPT (2018)
| BERT (2019)
|
主体结构
| Bi-LSTM
| Transformer Decoder(单向)
| Transformer Encoder(双向)
|
训练方式
| 双向语言模型(拼接左右)
| 自回归(左→右)
| MLM + NSP(双向)
|
预训练目标
| 预测下一个词
| 预测下一个词
| 随机遮盖词 + 判断句子关系
|
上下文信息
| 左右拼接、非深度交互
| 单向(左)
| 深度双向(层内融合)
|
表示粒度
| 词级嵌入
| 句级上下文
| 通用上下文表征
|
微调方式
| 特征抽取
| 任务微调
| 全参数微调(统一框架)
|
可扩展性
| 较弱
| 中等
| 极强
|
性能表现
| 中等
| 优
| 最优(NLP革命)
|
BERT 的优势: 真正的双向语境理解 + 统一预训练框架 + 强泛化性能; 不足: 训练成本高、输入受限、部分任务目标设计冗余; 改进方向: 更高效、更轻量、更长文本、更多模态的通用语言模型。
5、模型的应用与影响(含在 NLP 各任务上的表现与后续生态)
🌍 一、BERT 的应用核心理念:
“一个模型,通吃所有任务。”
- 情感分析要用 RNN;
- 命名实体识别(NER)要用 CRF;
- 阅读理解(QA)要设计复杂的匹配网络。
通过“预训练 + 微调”机制,只需更换任务头(output layer),就能迁移到几乎所有语言理解任务。
📘 二、BERT 在主要 NLP 任务上的表现与机制
1️⃣ 文本分类(Sentiment / Topic Classification)
- 机制:使用
[CLS]向量作为整句语义表示,接 softmax 分类。 - 数据集:SST-2, IMDb, Yelp, AG News 等。
- 表现:
- 相比传统 CNN/LSTM 提升 4–10 个百分点;
- 对小数据任务尤为有效(因为语言知识已在预训练中学到)。
- 应用场景:舆情分析、评论情感判断、垃圾文本检测。
2️⃣ 自然语言推理(NLI / MNLI)
- 机制:输入为句对
(premise, hypothesis),通过[SEP]分隔;[CLS]向量代表句对关系。 - 数据集:MNLI, SNLI。
- 表现:
- 首次在 GLUE 榜单上超过人类平均水平(MNLI ~86%)。
- 证明了 BERT 能理解句间逻辑关系。
- 应用场景:智能问答、事实验证、对话一致性分析。
3️⃣ 命名实体识别(NER)与序列标注
- 机制:BERT 输出每个 token 的上下文表示,接一个分类层(或 CRF)预测标签。
- 数据集:CoNLL-2003。
- 表现:
- 精确率 / 召回率显著提升;
- 对词义歧义、上下文依赖的实体识别更强。
- 应用场景:信息抽取、医疗报告分析、金融实体识别。
4️⃣ 阅读理解(Machine Reading Comprehension)
- 机制:输入
(Question, Passage),模型预测答案在段落中的起始与结束位置。 - 数据集:SQuAD 1.1 / 2.0。
- 表现:
- BERT 首次在 SQuAD 1.1 超越人类表现(F1 = 93.2 vs human 91.2);
- 在 2.0 版本(含不可回答问题)仍大幅领先。
- 应用场景:智能客服、知识问答系统、教育阅读理解。
5️⃣ 句子匹配与检索(Sentence Pair Matching / Semantic Search)
- 机制:利用
[CLS]表示句对语义相似度,可通过向量余弦或分类判断。 - 任务:STS-B、QQP、MRPC。
- 表现:
- 语义匹配准确度提升显著;
- 被广泛用于检索、语义索引、FAQ 匹配系统。
6️⃣ 其他任务扩展
任务类型
| 示例任务
| BERT 的作用
|
问答生成 / 对话系统
| SQuAD, CoQA
| 提取与理解关键信息
|
摘要生成 / 信息压缩
| CNN/DailyMail
| 作为文本理解模块结合生成模型
|
语义检索 / 搜索排序
| Passage Ranking, Sentence Embedding
| 提供上下文敏感表示
|
机器翻译 / 多语言理解
| XNLI, XQuAD
| 跨语言预训练(mBERT, XLM-R)
|
代码 / 医学 / 法律文本分析
| CodeBERT, BioBERT, LegalBERT
| 领域特化模型,表现超越传统词向量
|
🚀 三、性能影响:NLP 基准全面刷新
- GLUE 总得分:由 80 提升到 82.1(首次超过人类平均)。
- SQuAD v1.1:F1 = 93.2;SQuAD v2.0:F1 = 83.1。
- SWAG(句子填空推理):准确率 86.3%。