ERNIE(2019):知识增强预训练
1、研究背景与动机
🌍 一、研究背景:从“词向量”到“知识理解”
BERT 虽然懂语言,但不懂“世界”。
“马云是阿里巴巴的创始人。” “阿里巴巴是一家中国公司。”
“马云是中国企业家。”
🧠 二、动机核心:让模型“懂知识”
在语言模型中融入真实世界的结构化知识,让机器不仅懂语言,还懂常识。
1️⃣ BERT 的切词方式打碎了实体语义
- BERT 使用 subword 分词(如 WordPiece / BPE),
“北京大学”会被切成
[北][京][大][学]; - 结果导致模型难以识别“北京大学”是一个完整实体。
即:“北京大学” 整体遮盖,而不是遮一个“京”字。 模型由此学习到更稳固的“知识单元表示”。
2️⃣ BERT 不了解词语背后的概念与层级关系
- 例如“苹果”既可以是水果,也可以是公司;
- 纯上下文模型很难区分。
3️⃣ BERT 的 Mask 学习目标太“随机”
- BERT 只随机遮盖 token;学习目标碎片化,缺乏高级语义层次;
- 无法建模句子、篇章乃至跨句逻辑。
- 词级(Word-level)
- 实体级(Entity-level)
- 短语/句子级(Phrase-level) 使模型逐步掌握从词到句、再到知识层的语言理解。
⚡ 三、研究动机总结
问题
| BERT 的局限
| ERNIE 的动机
|
语义碎片化
| Subword 打碎实体
| 引入实体级 Mask 保留完整语义
|
缺乏世界知识
| 不理解实体与关系
| 结合知识图谱融入现实知识
|
理解层次浅
| 只做词级 Mask
| 多层次 Mask,学习结构化语义
|
✅ 四、一句话总结
ERNIE 的研究动机: 在 BERT 的语言理解基础上,引入知识图谱与层次化 Mask,让模型“既懂语言,也懂世界”。
BERT 读懂句子,ERNIE 读懂常识。
2、模型的核心创新点总结(含知识融合策略与多级 Mask 机制)
一、总体思路:从“词的共现”到“知识的融合”
将语言的表层语义 与 世界的结构化知识融合在一起。
二、创新点一:知识增强的多粒度 Mask 机制
1️⃣ 词级 Mask(Word-Level Masking)
- 类似于 BERT 的随机词遮盖;
- 让模型学会基本语法与上下文语言规律;
- 比如:“马云创办了 [MASK]” → 模型预测“阿里巴巴”。
2️⃣ 实体级 Mask(Entity-Level Masking)
- 通过实体链接(Entity Linking),识别文本中的命名实体(如人名、地名、机构等);
- 遮盖整个实体单元,而非子词: 例如:“[MASK] 是阿里巴巴的创始人。” → 模型需利用知识图谱推测“马云”。
- 模型学到“实体是整体的概念”;
- 掌握实体之间的语义关系(如“马云—创始人—阿里巴巴”)。
3️⃣ 短语 / 句子级 Mask(Phrase / Sentence-Level Masking)
- 随机遮盖更大语义单元(如子句或整句);
- 模型需根据上下文重建被遮盖的句子,学习篇章层语义关联。
- 让模型学到“句子之间”的逻辑关系与上下文一致性;
- 在问答、摘要、阅读理解等任务中尤为有用。
层次
| 学习目标
| 学到的能力
|
词级 Mask
| 填词预测
| 基础语言语法
|
实体级 Mask
| 实体识别与关系建模
| 世界知识与常识
|
句子级 Mask
| 语义预测与逻辑关系
| 篇章理解与推理
|
ERNIE = 把“语言理解”提升为“知识理解 + 逻辑理解”。
🧩 三、创新点二:知识融合策略(Knowledge Integration)
1️⃣ 实体对齐(Entity Alignment)
- 模型通过自动实体链接(Entity Linking), 将文本中提到的实体对齐到**知识图谱(如百度百科 / Wikidata)**中的节点。
- 这样,“马云”“阿里巴巴”不仅是词串,还对应知识图谱中的对象:
马云 → 实体ID:Person#123阿里巴巴 → Organization#456关系:创始人 (founderOf)- 模型可从图谱中读取额外特征(实体类型、上位概念、关系边)。
2️⃣ 知识嵌入融合(Knowledge Embedding Integration)
- 将实体的语义向量(从知识图谱学习)与词的上下文表示结合;
- 通过共享注意力层(Shared Attention Layer)让模型在“文本语义”和“知识语义”间相互补充。
3️⃣ 动态知识感知(Knowledge-Aware Context Encoding)
- 模型在每个 Transformer 层中动态调整注意力权重;
- 当输入中包含知识实体时,模型会更多关注实体相关上下文;
- 实现“读句子时带着常识去理解”的效果。
四、创新点三:多阶段预训练(Multi-Stage Pretraining)
阶段
| 学习内容
| 对应 Mask
|
阶段 1
| 基础语言结构
| 词级 Mask
|
阶段 2
| 实体识别与语义关系
| 实体级 Mask
|
阶段 3
| 篇章逻辑与语义一致性
| 句子级 Mask
|
五、实验验证的结果要点(简述)
- 在 阅读理解(CMRC 2018)、自然语言推断(XNLI)、语义相似度(LCQMC) 等任务上,ERNIE 全面超越 BERT;
- 在中文任务中优势尤其明显;
- Mask 实验表明:实体级 Mask 比随机词 Mask 更有信息效率;
- 模型在需要常识和世界知识的任务中表现尤为突出。
六、一句话总结
ERNIE 的核心创新:
- 提出多粒度 Mask(词、实体、句子),实现从语言到知识的层次化学习;
- 引入知识图谱实体链接与嵌入融合,让模型在训练中具备现实世界的常识与关系感知;
- 采用多阶段训练,使语言理解逐步演化为“知识理解”。
BERT 学语言,ERNIE 学知识。它把“读句子”升级为“读世界”。
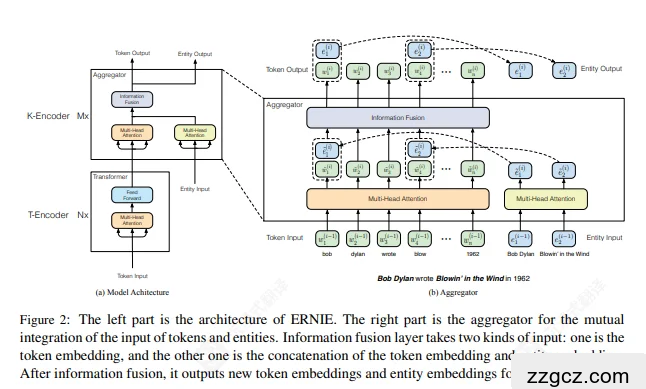
3、模型结构与运行原理(配图 + 模块化讲解)
总体思路:“双路编码 + 逐层对齐融合” 左侧是整体架构;右侧是“Aggregator(信息融合器)”,用于让**词(token)与实体(entity)**两条通道在每一层相互交换信息
0)输入与对齐(Token ↔ Entity)
- 文本先切成 token 序列 {w1,…,wn};
- 通过实体链接把其中可识别的 mentions 对齐到知识图谱实体序列 {e1,…,em};并把实体对齐到其 首个 token(图中虚线箭头所示)。论文显式给出了这种对齐记号 f(w)=e
- 因为不是每个词都有实体,m 不一定等于 n
1)双路编码:T-Encoder 与 K-Encoder
1.1 词路(T-Encoder)
- 结构:标准 Transformer Encoder 堆叠 NNN 层(多头自注意力 + 前馈层);
- 作用:像 BERT 一样从上下文中学习 token 的语义表示
1.2 实体路(K-Encoder)
- 结构:面向实体序列的编码器,包含多头注意力与前馈块,堆叠 MMM 层;
- 作用:在知识图谱实体之间建模关系,得到 entity 表示
图中左侧标注 T-Encoder (Nx)、K-Encoder (Mx) 即表示两条通道各自堆叠的层数 论文给出的一个规模是 N=6、M=6(Base 设置)
2)聚合器(Aggregator):层内“互相对话”
2.1 自注意力更新(各自先消化)
- 底部的两个 Multi-Head Attention 分别对 token 序列与entity 序列做自注意力,更新各自的上下文表示(黄色两块)
2.2 信息融合(Token↔Entity 交互)
- 顶部的 Information Fusion 层把两路信息对齐并融合:
- 输入一:纯 token embedding;
- 输入二:token embedding 与其对齐的 entity embedding 的拼接;
- 输出:新的 token 表示 与 entity 表示,作为下一层的输入
直观理解:每层都让“词表示”参考“实体知识”,也让“实体表示”反过来看上下文,从而逐层强化语言与知识的对齐。
3)层间迭代与顶层输出
- 如此 (自注意力 → 信息融合) 的两个步骤会在 N/M 层上反复迭代;
- 顶部得到 Token Output 与 Entity Output 两路表征,供预训练或下游任务使用
4)预训练目标(和结构如何配合)
- ERNIE 的预训练是多任务:MLM(掩码语言建模) + NSP + dEA(面向实体的去噪自编码);
- 训练语料以 Wikipedia 与 Wikidata 对齐,构造成既含 subword 又含 实体标注的序列;论文统计了约 4.5B 子词与 140M 实体
- 其中 实体嵌入 可用图谱上游模型(如 TransE)初始化,并与 Transformer 共同训练/融合
因为每层都做 Token↔Entity 交互,MLM 能借助实体知识补全被遮盖词;dEA 则直接训练实体表征的鲁棒性;两者协同提升“语言 × 知识”的统一表征。
5)与 BERT 的差异点(从结构视角快速对比)
方面
| BERT
| ERNIE
|
输入
| 只有 token
| token + 对齐的 entity(来自 KG)【P19-1139】
|
主干
| 单路 Transformer
| 双路编码(T/K)+ 每层聚合器【P19-1139】
|
融合
| 无显式知识通道
| Information Fusion:token 与 entity 拼接/融合【P19-1139】
|
预训练
| MLM + NSP
| MLM + NSP + dEA(实体去噪)【P19-1139】
|
6)一句话流程图(文字版)
文本 → 分词 & 实体链接 → [T-Encoder(词)] 与 [K-Encoder(实体)] 并行编码
↓(各自自注意力)Aggregator:Information Fusion(词↔实体)
↓(输出新 token/entity 表示)
重复 N/M 层 → 顶层 Token/Entity 表示
↓
预训练任务:MLM / NSP / dEA(或下游微调)
4、模型的优势、不足与改进方向
🌟 一、模型的主要优势
1️⃣ 知识增强:让模型“懂世界”
- 与 BERT 最大不同点是:ERNIE 不仅学习语言形式,还整合了知识图谱信息;
- 通过 实体对齐 + 实体级 Mask,模型能学习“谁是什么”“谁与谁相关”的现实关系;
- 这种“知识增强表示”让模型在需要常识或实体理解的任务(如问答、阅读理解、关系抽取)中表现显著更优 。
✅ 优势关键词:语言 × 知识融合
2️⃣ 多粒度 Mask 策略:层次化理解语言
- ERNIE 的多层 Mask(词级、实体级、句子级)使模型能从不同语义层面捕获信息;
- 这种分阶段 Mask 训练让模型逐步学习: 语法 → 实体语义 → 篇章逻辑;
- 比 BERT 的随机词遮盖更高效、更语义一致。
✅ 优势关键词:分层学习语义
3️⃣ 多阶段训练:渐进式知识注入
- 训练分为多个阶段,从纯语言到实体知识,再到篇章理解;
- 每一阶段都建立在前一阶段的语义基础上;
- 实验证明:这种“渐进式预训练”显著提升了模型的稳定性与收敛速度 。
✅ 优势关键词:逐步增强理解
4️⃣ 在中文任务上表现突出
- 由于 ERNIE 的实体识别和知识库整合依托百度百科 / 知识图谱, 在中文阅读理解、命名实体识别、自然语言推断等任务上全面超越 BERT;
- 对中文多义词(如“苹果”=水果/公司)的区分能力尤其强。
✅ 优势关键词:中文优势显著
⚠️ 二、模型的不足与局限
1️⃣ 知识依赖性强
- 需要高质量的知识图谱(如百科实体链接), 若知识库不完整或存在噪声,会直接影响效果;
- 不同语言或领域(医学、法律)下迁移困难,因为知识图谱需要重新构建。
⚠️ 局限关键词:知识域依赖
2️⃣ 架构复杂,训练成本高
- ERNIE 需要额外的实体链接模块和知识嵌入通道;
- 比单一 Transformer 结构的 BERT 训练更耗算力;
- 同时,实体标注/对齐步骤使得大规模预训练流程更复杂。
⚠️ 局限关键词:计算开销大
3️⃣ 知识更新困难
- 模型训练完成后,内部“知识”是静态的;
- 当现实世界发生变化(如公司更名、新人物出现)时,模型无法自我更新;
- 需要重新训练或外部检索增强(retrieval-augmented)机制来弥补。
⚠️ 局限关键词:静态知识问题
4️⃣ 知识融合方式相对浅层
- 实体嵌入与文本嵌入的融合多为拼接或加权平均;
- 缺乏深层语义推理或动态知识选择机制;
- 难以捕捉复杂的知识图谱结构(如多跳推理)。
⚠️ 局限关键词:融合深度有限
🔧 三、改进方向与后续发展
1️⃣ 持续知识学习(Continual Knowledge Learning)
- 后续 ERNIE 2.0(2019) 提出了“持续学习(Continual Learning)”框架, 把知识注入拆分为多个子任务(如语法、关系、语义匹配), 模型可动态增量学习新知识,无需完全重训。
🧩 改进关键词:动态知识注入
2️⃣ 知识检索增强(Retrieval-Augmented Models)
- 新一代模型(如 RAG、REALM、K-BERT)将外部知识库或检索器与语言模型结合, 训练时动态查询相关知识,而非将全部知识硬编码;
- 这种方式解决了 ERNIE 的“知识更新慢”问题。
🧩 改进关键词:可更新知识
3️⃣ 跨语言与跨模态知识融合
- ERNIE-M(2021)扩展到多语言场景;
- ERNIE-ViL(2021)将文本与图像知识联合建模,用于视觉问答与多模态推理;
- 说明知识增强思路可以跨越语言与模态边界。
🧩 改进关键词:多语言 & 多模态扩展
4️⃣ 知识结构建模与推理增强
- 后续研究(如 K-BERT、CoLAKE、KEPLER)尝试在 Transformer 内部显式建模知识图谱结构;
- 引入图注意力(Graph Attention)或关系编码(Relation Embedding)以提升逻辑推理能力;
- 让模型能“像人一样”在知识网络中跳跃推理。
🧩 改进关键词:结构化推理