HAN 分层注意力(2016):词→句→文档的层级表示,长文档分类经典
导出时间:2025/11/24 08:56:33
1、研究背景与动机
🧩 一、问题背景:从句子到文档的“理解鸿沟”
在自然语言处理中,文本分类(Text Classification) 是最基础、最重要的任务之一。
目标是:把一段文字(如一条评论、一篇新闻、一封邮件)分到正确的类别,比如:
- 电影评论 → “正面 / 负面”
- 新闻 → “科技 / 体育 / 政治”
- 邮件 → “正常邮件 / 垃圾邮件”
然而,传统方法和早期深度学习模型在面对“长文档”时都有明显局限:
- 传统线性模型(如 SVM 、LogReg)
- 把文档表示为 n-gram 词频向量;
- 忽略了词序与上下文语义;
- 各词的“重要程度”被平均对待。
- 早期神经网络模型(CNN、RNN)
- CNN 善于捕捉局部 n-gram 特征,但难以处理长距离依赖;
- RNN /LSTM 虽能记忆上下文,但当文档过长时梯度会衰减,计算量暴增。
- 无法显式建模“句子之间的逻辑结构”。
于是出现了一个核心问题:
机器怎样像人一样,理解“一篇文章”而不只是“一串词”?
🧠 二、研究动机:让模型“分层理解”文档
论文作者(卡内基梅隆大学 + 微软研究院)提出一个直觉:
“文档本身是层次化的结构—— 词组成句子,句子组成文档。 模型也应该按同样的层次来理解。”
换句话说,人类在读文章时的思维方式大致是:
- 先理解每个词的含义;
- 再抓住句子里的重点;
- 最后整合整篇文档的核心。
因此,模型也应当先提炼句子表示,再汇总成文档表示,而不是把整篇文章当作单一序列喂进 RNN。
这就是 “分层表示(Hierarchical Representation)” 的核心思想。
🔦 三、核心洞察:并非所有词、所有句子都同样重要
论文中用一个 Yelp 评论举例:
“Pork belly = delicious. Scallops? I don’t even like scallops, and these were amazing.”
- 在整篇评论中,第一句和第三句信息量最强;
- 而在这些句子里,“delicious”、“amazing” 才真正决定了情感极性。
于是作者意识到:
模型不仅要知道“结构”,还要学会“聚焦”—— 让模型自动关注最重要的词和句子。
这就引出了论文第二个关键思想:
注意力机制(Attention Mechanism)。
它让模型在生成表示时,能够为不同词和句子分配不同的权重,实现“选择性理解”。
例如:
- 在情感分析任务中,模型会更关注 “delicious”、“terrible”;
- 在主题分类任务中,会聚焦 “browser”、“zebra”等核心词。
🚀 四、研究目标:从“词注意力”到“句注意力”的层次化网络
基于以上动机,作者提出了 HAN(Hierarchical Attention Network):
- 设计两级结构:
- 词级编码 + 注意力 → 生成句子向量;
- 句级编码 + 注意力 → 生成文档向量。
- 模型可端到端训练;
- 同时具备:
- 结构化建模能力(捕捉层次关系);
- 可解释性(能可视化哪些词/句影响了预测)。
📚 五、总结:从“全局平均”到“有重点的层次理解”
阶段
| 方法
| 存在问题
| HAN 的改进
|
传统方法
| n-gram + SVM / LR
| 稀疏、高维、无语义
| 引入词嵌入表示语义
|
TextCNN / RNN
| 捕捉局部或序列信息
| 无法处理长文档、无显式结构
| 分层建模词→句→文档
|
注意力机制前
| 每个词权重相同
| 信息被平均稀释
| 引入注意力聚焦重要词句
|
HAN(2016)
| 层次结构 + 双级注意力
| —
| 捕捉上下文、增强解释性
|
✅ 一句话总结:
HAN 的诞生动机是解决“长文本无法被模型层次理解”的问题。 它通过“词 → 句 → 文档”的分层建模结构,结合注意力机制,使模型能像人一样, 先理解局部,再整合全局,最终聚焦于文本中最有意义的部分
2、模型的核心创新点总结
🌟 总体思路:从“平面注意”到“层级注意”
HAN 的核心创新,是首次提出将“层次结构 + 注意力机制(Attention)”结合到一起,用于长文档分类任务。
模型通过模拟人类的阅读方式——词 → 句 → 文档,逐层提取信息、逐层聚焦重点,从而在性能与可解释性之间取得平衡
(1)层次化文档表示(Hierarchical Representation)
💡 创新点:
HAN 将文档建模为两层结构:
- 词层(Word level):通过双向 GRU(Bi-GRU)提取上下文语义;
- 句层(Sentence level):再用另一层 Bi-GRU 处理句子序列。
这样,模型不再直接把整篇文章当作一长串词来处理,而是:
“先理解每个句子的语义,再理解句子之间的关系。”
🚀 优点:
- 模型能捕捉局部与全局的语义层次;
- 长文档处理效率更高,梯度传播更稳定;
- 显式保留了文本结构信息(符合自然语言的层次逻辑)
(2)双级注意力机制(Hierarchical Attention)
💡 创新点:
论文首次引入 “两级注意力机制”:
- 词级注意力(Word-level Attention) → 判断每个词在句子中的重要性。
- 句级注意力(Sentence-level Attention) → 判断每个句子在文档中的重要性。
最终的文档表示是加权求和:
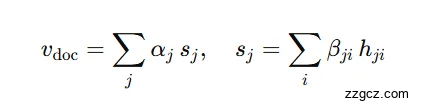
其中:
- hji:第 j 个句子的第 i 个词的隐藏状态;
- βji:词级注意力权重;
- αj:句级注意力权重
🚀 优点:
- 不同层次的注意力使模型聚焦关键信息;
- 支持可视化(哪些词/句子起关键作用);
- 显著提升了模型可解释性。
(3)双向 GRU 编码器(Bi-GRU Encoder)
💡 创新点:
相比 LSTM,作者选用 双向 GRU(Bidirectional GRU) 来编码上下文:
- GRU 结构更轻量,计算更快;
- 双向结构(前向 + 后向)能整合前后语义;
- 有利于捕捉句子中词与词之间的依赖关系。
这让 HAN 在保持精度的同时,能高效建模词间上下文依赖和句间逻辑关系
(4)引入可视化注意力 —— 让模型“可解释”
💡 创新点:
HAN 的注意力权重不仅参与计算,还能直接用热力图可视化:
- 哪些词在句子中被赋予了高权重;
- 哪些句子在整篇文档中最重要。
这使得模型的决策过程更加透明,人们能看到模型“为什么这样分类”。
这是深度学习文本模型中首次系统地实现可解释性可视化
(5)端到端可训练的层次结构(End-to-End Hierarchical Model)
💡 创新点:
与以往多阶段模型(如先用句子编码器再拼接)不同,HAN 的词层和句层注意力是联合训练的。
整个网络端到端优化,自动学习:
- 哪些词对句子分类有贡献;
- 哪些句子对文档分类更重要。
这使得 HAN 能自动发现文本的语义结构,而非依赖人工特征或句法树。
(6)性能与泛化优势
在多个基准任务(Yelp Review、Yahoo Answers、IMDB)上,HAN 显著优于 TextCNN、LSTM、Doc2Vec 等模型:
- 在 长文档任务 上表现尤为突出;
- 在 相似长度文本 上保持高效;
- 注意力层帮助模型在多语言任务中也能泛化良好
3、模型结构与运行原理(含图解 + 流程讲解)
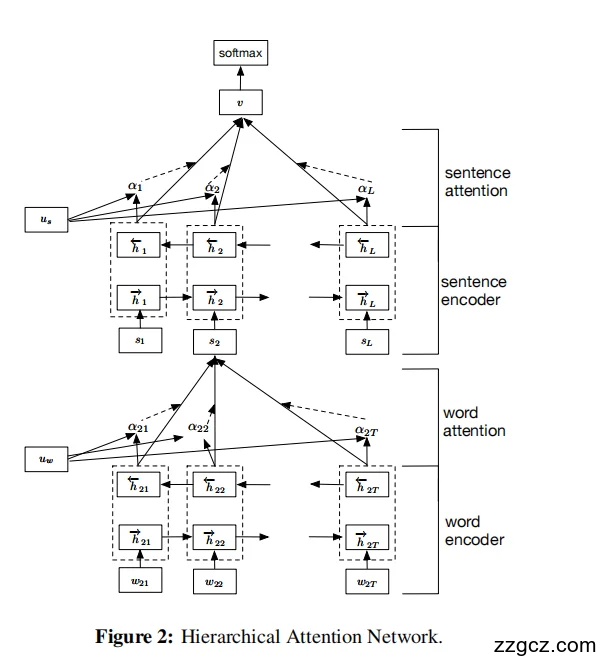
(1)词层:Word Encoder + Word Attention

(2)句层:Sentence Encoder + Sentence Attention

(3)分类与训练

(4)把 Figure 2 对上流程(速查)

(5)为什么这样设计有效?(要点回顾)
- 层次结构映射了“词→句→文档”的天然组织形式,避免把长文档当作超长序列硬吃;
- 双级注意力让模型聚焦重要词与重要句,并且权重依上下文变化(同一个词在不同语境权重不同),同时带来可解释性;
- 在 6 个大规模数据集上,HAN 显著优于 LSTM、CNN 等常见架构,尤其擅长长文档分类
4、模型的优势、不足与改进方向(含与 TextCNN / fastText 对比)
🌟 一、模型优势:层次化 + 注意力,让模型像“人”一样读文章
HAN(分层注意力网络)在文本分类任务中取得突出效果,核心优势可总结为以下几点:
1️⃣ 层次化结构,更符合自然语言的组织规律
- HAN 模型尊重了文本的天然结构:词 → 句 → 文档;
- 先在词层面建模,再在句层面整合,既捕捉局部语义,又保留整体逻辑;
- 这种“自下而上”的建模方式能有效处理长文档,避免 RNN 对超长序列的梯度消失问题
💬 通俗理解: 人读文章不是从第一个词读到最后一个词,而是先理解每个句子,再归纳句间关系。HAN 就模仿了这种过程。
2️⃣ 双重注意力机制(word-level & sentence-level attention)
- HAN 的最大创新之一是 双层注意力机制:
- 词注意力:挑出每个句子中的关键信息词;
- 句注意力:聚焦整篇文档中最关键的句子。
- 这样模型能自动判断 “哪些词/句最重要”,从而实现“重点理解”而非平均处理。
💡 与传统模型不同,HAN 不再“平等对待所有词”,而是让模型自主分配注意力权重,大幅提升语义提取的精准度。
3️⃣ 模型具有可解释性
- 注意力权重可以可视化,直观显示:
- 哪些词/句影响了模型的最终决策;
- 模型是如何“聚焦重点”的;
- 这使 HAN 成为最早兼顾性能与可解释性的神经文本模型之一
📊 实际中研究者会用颜色或热力图展示词的注意力权重,帮助分析模型理解逻辑。
4️⃣ 优异的性能表现与泛化能力
- 在多个长文档数据集(如 Yelp Reviews、IMDB、Yahoo Answers)上,HAN 明显优于 LSTM、CNN、Doc2Vec 等方法;
- 在较短文本上也保持了竞争力;
- 同时模型可以端到端训练,不依赖手工特征或句法树
5️⃣ 工程与概念兼容性强
- 结构清晰,易于扩展、可与 Transformer 或预训练模型结合;
- 已成为“长文档建模”的基础框架,被广泛用于:
- 论文摘要分类;
- 新闻主题建模;
- 法律文书/医疗报告分析;
- 对话与多段落推理。
⚠️ 二、模型的不足与局限性
尽管 HAN 设计巧妙,但在更复杂的 NLP 场景中仍存在不足:
1️⃣ 上下文依赖仍有限
- 词和句的编码依旧依赖于 GRU 的局部上下文;
- 对特别长的篇章(如数百句的文档)仍难捕捉跨段落逻辑;
- 注意力机制本身无法建立“全局依赖”(与 Transformer 相比劣势明显)。
2️⃣ 注意力权重并不总是“真正解释性”
- 虽然可视化易懂,但注意力值高不一定代表该词确实影响了预测;
- 后续研究(如 Jain & Wallace, 2019)指出:注意力可视化 ≠ 因果解释;
- 因此 HAN 的“可解释性”更像是一种启发式可视化,而非严格可解释模型。
3️⃣ 参数量相对较大,训练成本较高
- 相比 fastText(仅线性层)或 TextCNN,HAN 结构复杂、计算多;
- 双层 Bi-GRU + 双层注意力会导致训练耗时明显上升;
- 对 GPU/显存有一定要求,不适合极大规模在线系统。
4️⃣ 依赖句子分割质量
- 模型的“句级编码”依赖句子边界;
- 若文本中句号/换行标注不准确,会直接影响句层语义建模;
- 对非标准语料(如社交媒体、对话文本)鲁棒性略差。
🔧 三、后续改进方向与扩展研究
HAN 的提出奠定了“层次注意力”的方向,后续许多工作都基于此进行改进:
1️⃣ 结合 Transformer(Self-Attention)替代 GRU
- Hi-Transformer / Hierarchical BERT / Longformer 等模型将层次思想与自注意力融合;
- 改进了长依赖建模与全局信息捕获能力;
- 大幅提升长文本任务表现。
2️⃣ 动态注意力与多头机制
- 改进原始单向注意力为多头层次注意力(Multi-head Hierarchical Attention);
- 可捕捉多种语义关系(主题、情感、实体间逻辑等)。
3️⃣ 融合预训练语言模型
- 近年来,很多研究直接将 HAN 与 BERT/ERNIE 结合:
- 用 BERT 生成词或句子嵌入;
- 用 HAN 进行句间建模;
- 结合了预训练语义 + 层次逻辑的优势。
4️⃣ 面向多模态与跨语言扩展
- HMAN(Hierarchical Multimodal Attention Network):在文本 + 图像任务中引入分层注意力;
- HAN-X:扩展到多语言新闻、社交媒体、法律文档,增强语言迁移能力。
5️⃣ 应用于可解释性与可视分析
- 在新闻摘要、舆情分析、医疗报告中,HAN 的注意力热图被用于辅助人类专家理解模型决策;
- 成为“可视可解释 AI (XAI)” 的代表性模型之一。