RoBERTa(2019):BERT 改进版,更强的微调表现
导出时间:2025/11/24 08:56:52
1、研究背景与动机(通俗版)
背景痛点:BERT 很强,但“到底强在啥”不清楚。
- 2018–2019 年,各类预训练方法(ELMo、GPT、BERT、XLNet、XLM…)层出不穷,但横向比较困难:训练成本高、各家用的私有/大小不同的数据、超参设置差异巨大,导致“谁更好”为时难判。
- 论文作者重做 BERT 预训练,发现 BERT 实际“被低训练”(undertrained),很多后续方法的领先,可能是训练和数据配方而不是新目标/新结构本身带来的。
核心动机:做一次“配方层面”的系统复刻与优化
- 量化训练细节影响:系统评估关键超参与数据规模对下游效果的贡献,澄清“改模型 vs. 改配方”的边界。
- 提出更稳健的 BERT 训练食谱:在不改架构、不改 MLM 目标前提下,把训练做“到位”,验证仅靠更好的训练策略就能匹配/超过后续许多方法。
- 控制数据因素、给出公开可复现基线:收集并开放 CC-NEWS 等大规模公开语料,与 BOOKCORPUS+WIKI 组合,控制“数据量/多样性”这个变量,避免私有数据带来的不公平比较。
具体改进思路(动机对应做法)
- 训练更久、批更大、数据更多:BERT 之前的训练轮数/批大小偏小;扩大训练步数与batch、把数据量从 ~16GB 提升到 ~160GB,观察下游实打实提升。
- 去掉 NSP:实证发现去除 Next Sentence Prediction 后,配合合适的输入打包(FULL/DOC-SENTENCES),下游更好或持平,质疑 NSP 的必要性
- 动态掩码(dynamic masking):而非一次性静态掩码,训练过程中每次重新采样 MASK 图案,提高学习效率与覆盖度。
- 更长序列训练:更多用满 512 token 的样本,让模型在预训练阶段就习惯长上下文。
- 更通用的分词:采用byte-level BPE(50K),减少依赖手工规则,统一编码方案,便于跨域/跨语料扩展(效果差异很小但工程更稳)。
期望达成的研究目标
- 给出一套**“鲁棒优化”的 BERT 训练流程(RoBERTa),证明在相同架构与 MLM 目标下,仅靠更好的训练与数据配方即可重夺/刷新 SOTA**(GLUE、SQuAD、RACE)。
- 还原客观对比:把“模型设计收益”和“训练/数据收益”拆开,为后续工作提供公平、可复现的对照基线与开源实现。
一句话动机
RoBERTa 的出发点不是换架构,而是把 BERT 的“训练与数据配方”做到位,重新定义一个更强、更可复现的预训练基线。
2、模型的核心创新点(训练改动 + 主要实验结论)
RoBERTa 的思想:不改架构与目标(仍是 BERT 的 Transformer+MLM),而是把**训练与数据“配方”**做到位,由此显著提升下游效果。
一)训练与数据层面的关键改动
- 更久、更大的预训练
- 更长步数(从 100k → 300k → 500k)与更大 batch;在控制数据不变时就能带来明显增益。
- 论文给出大规模预训练超参(例如 RoBERTa-Large:24 层、1024 隐层、16 头、batch size=8k、max steps=500k 等)。
- 更多、更公开的训练语料
- 在 BOOKCORPUS+WIKI 基础上,加入 CC-NEWS 等额外公开数据,总量达到 ~160GB 文本;训练数据更大、更多样。
- 移除 NSP,并改造输入打包方式
- 对比四种输入:原始 SEGMENT-PAIR+NSP、SENTENCE-PAIR+NSP、去 NSP 的 FULL-SENTENCES 与 DOC-SENTENCES。
- 结论:去掉 NSP 并按文档连续采样(DOC/FULL-SENTENCES)匹配或优于原始 BERT;单独用“句对”输入反而变差。
- 动态 Masking(Dynamic Mask)
- 不再一次性静态生成遮盖位置,而是训练过程中每次重新采样遮盖模式,提高学习覆盖度。
- 更长序列训练
- 预训练阶段更频繁地使用 512-token 的长序列,让模型从一开始就学长程依赖(与 BERT 中多数步只用 128 的策略相对)。
二)主要实验结论(对哪些改动“有效”的证据)
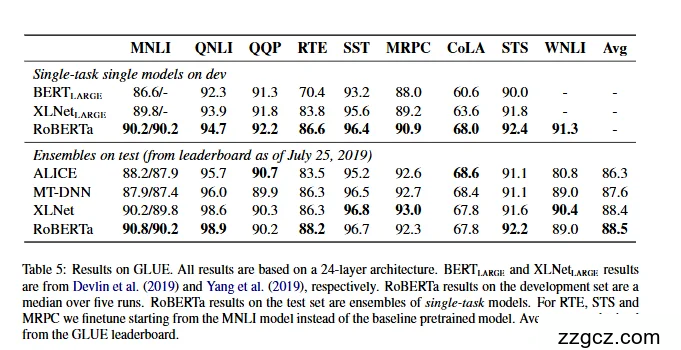
- “去 NSP + 连续句”更好
- 在相同(BOOKCORPUS+WIKI)数据与 1M 步训练下,DOC-SENTENCES(无 NSP)优于原始 BERT-BASE;使用单句对的 SENTENCE-PAIR 反而降低表现。
- 数据量与训练步数越多越好
- 把数据扩展到 ~160GB 并把步数从 100k→300k→500k,GLUE/SQuAD/RACE 全面提升,且 300k/500k 多数任务超过 XLNet-Large;甚至还未观察到过拟合。
- 下游基准的 SOTA 表现
- SQuAD v2.0 上,单模型 RoBERTa 在 dev 集 超 XLNet 0.4 EM / 0.6 F1,且不依赖额外数据增强。
- RACE 阅读理解测试集:RoBERTa 83.2%,高于 BERT-Large (72.0) 与 XLNet-Large (81.7)。
- GLUE:开发集对比表明,随着“加数据/更久训练”,多项子任务继续上升(见表 8)。
- “复刻 + 优化”即可回到/超过后续方法
- 论文强调:在不改架构与目标的前提下,通过上述“食谱”调整即可匹配或超过后续多种 post-BERT 方法,说明很多领先来自训练/数据因素。
三)一句话总结(给记忆用)
RoBERTa = BERT 的“训练食谱大升级”:更久/更大/更多数据 + 动态 Mask + 去 NSP + 长序列与合理打包 → 稳健提升微调效果并重夺多项 SOTA。
3、模型的优势、不足与改进方向
🌟 一、模型的主要优势
RoBERTa 的名字来自 “Robustly optimized BERT approach”,也就是“更稳健、更彻底优化的 BERT”。
它的最大亮点不是架构创新,而是把 BERT 的训练机制做到极致。这带来了几个核心优势👇
1️⃣ 性能全面超越 BERT 与同期模型
- 在 GLUE、SQuAD、RACE 等基准上,RoBERTa 显著超过 BERT,甚至在部分任务上超过 XLNet;
- 例如:RACE 阅读理解准确率提升至 83.2%(vs BERT-Large 的 72.0),SQuAD v2.0 上也领先。
- 论文指出:改训练,不改架构,就能提升 3–5%,说明优化的潜力巨大 。
2️⃣ 移除 NSP 提升泛化能力
- BERT 的 “Next Sentence Prediction (NSP)” 被证明并非必要;
- RoBERTa 通过 “DOC-SENTENCES” 连续采样策略完全去掉 NSP,反而让模型更稳、更好;
- 结果表明:模型仍能捕捉句间关系,不再受冗余任务干扰 。
3️⃣ 动态 Masking 让模型更聪明
- BERT 使用“静态遮盖”,RoBERTa改为“动态遮盖(Dynamic Masking)”: 每次训练重新随机选择被遮盖的词,增强模型对不同语境的适应性;
- 动态 Mask 提升了训练样本的多样性,使模型学得更“通用” 。
4️⃣ 数据与训练规模大幅扩充
- 训练语料从 BERT 的 ~16GB → 扩展到 160GB(10倍!);
- 训练步数增加到 500k,批大小增至 8k;
- 这些使模型在大规模场景中稳定收敛、不早饱和,提升了语言理解的广度 。
5️⃣ 模型更鲁棒、可复现性更强
- 论文系统评估了每个超参数对性能的影响, 给出了可公开复现的训练流程与数据组合;
- 这让 RoBERTa 成为后续研究的**“标准预训练基线”**。
⚠️ 二、模型的不足与局限
虽然 RoBERTa 让 BERT 重回 SOTA,但它依然存在明显问题:
1️⃣ 训练代价极高
- 使用 160GB 数据、8k batch、500k 步;
- 对硬件与能耗要求极高,普通研究者难以复现;
- 没有提出任何结构性降本方案,仅优化训练。
2️⃣ 模型仍为 Encoder-only 架构
- 只适用于语言理解类任务(NLU),无法直接进行文本生成;
- 对开放式问答、摘要、对话生成等任务仍需其他模型(如 GPT、T5)。
3️⃣ 长文本建模能力有限
- 仍然使用标准 Transformer,最大输入长度 512 token;
- 无法高效处理长文档或多轮对话。
4️⃣ 改进主要是“工程层面”
- 没有提出新的学习目标或架构创新;
- 本质上是 “BERT 的重训 + 经验总结”,对理论推动有限;
- 在“为什么有效”上缺乏深入分析(更多是经验优化)。
🔧 三、后续改进方向与发展趋势
RoBERTa 的成果促使 NLP 研究进入了“更大、更久、更聪明训练”的阶段,也直接催生了多个方向的改进:
1️⃣ 结构优化:轻量与高效
模型
| 改进方向
|
ALBERT (2019)
| 参数共享 + 嵌入分解,减少参数 10 倍
|
DistilBERT (2019)
| 知识蒸馏,压缩模型至 60% 大小,保留 95% 性能
|
ELECTRA (2020)
| 改进 MLM 目标,用“替换词检测”大幅加速训练
|
这些模型在保留 RoBERTa 表现的同时,显著降低训练与推理成本。
2️⃣ 任务扩展:跨语言、多模态
- XLM-R (2020):在 RoBERTa 框架下进行多语言预训练(100 种语言);
- VisualBERT / VL-BERT (2020):结合图像与文本输入,扩展到多模态理解任务。
3️⃣ 长文本与稀疏注意力
- Longformer / BigBird (2020) 在 RoBERTa 基础上改造注意力结构;
- 将复杂度从 O(n2)降为 O(n),支持几千词长度的输入;
- 有效解决了“RoBERTa 无法处理长文档”的问题。
4️⃣ 预训练范式演化
RoBERTa 的“只调训练配方”理念影响深远,直接启发了:
- GPT-2/3:更长训练、更大语料;
- T5:统一“文本到文本”框架;
- DeBERTa / SpanBERT:针对 Masking 策略进一步改良;
- 这些都延续了 RoBERTa 的核心精神——优化训练细节比改架构更重要。
✅ 四、一句话总结
RoBERTa 的优势: 训练彻底、数据更大、性能更强、复现更稳; 不足: 成本高、仅限理解任务、理论创新有限; 改进方向: 向高效(ALBERT)、轻量(DistilBERT)、多语言(XLM-R)与长文本(Longformer)演化。