TextCNN(2014):句子级 CNN,简单有效的baseline
导出时间:2025/11/24 08:56:13
1、研究背景与动机
背景:深度学习与词向量推动下的句子分类需求
- 2012 年起,深度学习在计算机视觉与语音识别中取得显著进展,促使 NLP 社区探索端到端可学习的表示与模型。与此同时,无监督的词向量(如 word2vec)将高维稀疏词表示映射到稠密语义空间,成为“通用特征提取器”,为上层分类器提供良好输入。
- 卷积神经网络(CNN)最初用于视觉,但很快在语义解析、检索与句子建模等 NLP 任务中显示出效果。如何把 CNN 与预训练词向量结合,用最小的工程与调参成本解决句子级分类(如情感、主客观性、问题类型判别)的问题,成为一个重要且务实的方向。
动机一:用“极简 CNN + 预训练词向量”做强基线
- 论文提出的核心设想是:在预训练词向量之上堆叠单层卷积 + 最大池化 + 全连接的极简结构,尽量不做繁复的结构改造或解析依赖(例如不依赖句法树、不做复杂的 k-max 池化),观察它在多数据集上的基线强度与泛化性。事实证明,这样的模型在几乎不调参的前提下,已能在多项基准上达到或刷新当时的 SOTA,说明预训练词向量确实能作为跨任务的“通用特征”。
动机二:比较“静态 vs. 微调 vs. 多通道”的词表示策略
- 作者系统对比三种策略:
- 静态(static):固定预训练向量,仅训练上层参数;
- 非静态(non-static):在任务上微调词向量;
- 多通道(multichannel):同时保留一份静态向量与一份可微调向量,让卷积核在两路通道上共享,期望在保持通用语义与学习任务特异语义之间取得平衡、并缓解过拟合。
- 这一设计动机源自两个问题:预训练向量是否足够“通用”?微调能带来多少任务收益?能否兼得“通用 + 特定”的优点?
动机三:以最小代价覆盖多样句子分类基准
- 论文在情感分析(MR、SST-1/2)、主客观性(Subj)、问题分类(TREC)、产品评论(CR)、观点极性(MPQA)等多样句法/语义风格的数据集上进行统一实验,强调同一套超参数与简单正则化(dropout + L2)即可获得稳定表现,凸显方法易用、鲁棒、可复用的工程价值。
动机四:呼应“通用特征抽取器”的跨领域趋势
- 作者借鉴了计算机视觉中的经验:用在大型数据上预训练得到的特征,在下游任务上往往“开箱即用”。本工作希望在 NLP 中验证类似结论:预训练词向量 + 简洁 CNN能否成为强大而朴素的通用基线,为后续更复杂模型提供可靠的参照点。
小结
TextCNN 的研究动机并非追求结构复杂度,而是以最小结构复杂度与最少先验处理,系统验证“预训练词向量 + 句子级 CNN”在广泛分类任务上的有效性、可泛化性与可复用性;同时通过静态/微调/多通道三种策略对比,探究如何更好地利用预训练表征来提升句子分类性能。
2、模型的核心创新点总结
(1)极简架构 + 预训练词向量的强大基线
TextCNN 的第一个创新是:它极度简化了模型结构。整个模型只包含:
- 一层卷积层(多个不同尺寸的卷积核);
- 一次 max-over-time pooling 操作(取每个特征图的最大值);
- 一个全连接 softmax 分类层。
这一结构去除了复杂的句法树、循环结构或深层堆叠,仅依靠词向量矩阵卷积实现“n-gram 特征提取”,大幅降低模型复杂度,却在多个任务上超越了当时的复杂模型。这证明了:简单的 CNN + 优质词向量,就能捕捉句子级语义特征
(2)“多通道”词向量机制(Static vs. Non-static vs. Multichannel)
论文提出并系统比较了三种创新的词向量使用方式:
- Static(静态通道):词向量保持固定,仅训练上层 CNN 参数;
- Non-static(可微调通道):词向量可通过反向传播微调;
- Multichannel(多通道):同时保留一份静态向量和一份可微调向量,卷积核在两路上共享。
这种多通道设计(借鉴图像中 RGB 概念)让模型既能保留预训练语义的“通用性”,又能学习特定任务的“专有语义”,在当时是一个重要的创新点
(3)Max-over-time Pooling:自动适应变长句子
模型采用了最大池化(max-over-time pooling)来处理变长输入句子。该方法自动捕捉整句中最显著的局部特征,无需对齐或填充复杂结构。这种“取最大值”的方式在当时被认为是句子全局语义的简洁而有效的提取器
(4)Dropout + L2 正则:稳健训练的关键
Kim 引入了 Dropout 和 L2-norm 限制 的正则化组合,用于防止特征共适应和过拟合。Dropout 在 TextCNN 中首次被系统验证为能显著提升文本分类任务的泛化能力(性能可提升约 2–4%)
(5)“通用词向量”理念的实证验证
TextCNN 的实验表明,直接在 预训练词向量(如 word2vec) 上训练的浅层 CNN,无需复杂结构也能在情感分类、主客观性判断、问题分类等七个任务上取得当时 SOTA。这验证了一个重要观点:
“预训练词向量 + 简单神经网络 = 通用特征提取器。” 这为后续的 BERT、GPT 等“预训练+微调”范式奠定了思想基础
(6)实验设计的系统性与工程可复用性
作者强调所有任务都使用相同的超参数和结构设置,不针对特定数据集调参,凸显模型的鲁棒性和可迁移性。这种“可复用基线”理念在后来成为 NLP 模型评估的重要标准之一。
✅ 简而言之:
TextCNN 的创新在于**“以极简 CNN 验证预训练词向量的强大表达能力”**。
它提出了多通道词向量结构、max pooling 的句子级特征提取、以及简单但有效的正则化策略,使得这一模型成为深度学习 NLP 时代的第一个经典且持久有效的“句子级 CNN 基线”。
3、模型的网络结构
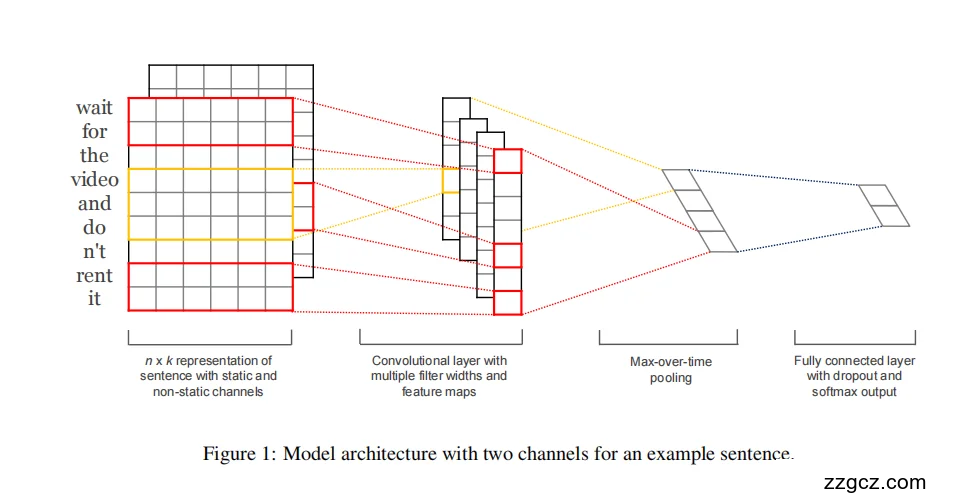
下图展示了 TextCNN 的整体架构(以句子 “wait for the video and don’t rent it” 为例)。整个网络可以分为 四个主要部分:
(1)输入层:词向量表示(Embedding Layer)
- 每个句子被表示为一个大小为 n × k 的矩阵:
- n:句子长度(单词个数);
- k:词向量维度(例如 300 维的 word2vec)。
- 每一行就是一个词的向量表示。
TextCNN 的一个特色是采用了 “两通道(two-channel)”结构:
- 静态通道(static channel):使用预训练词向量,保持固定不更新;
- 非静态通道(non-static channel):同样用预训练词向量初始化,但在训练过程中允许通过反向传播进行微调。
👉 这就像人类在学习中既保留“已有知识”(静态通道),又根据任务调整“理解细节”(非静态通道)。
(2)卷积层(Convolution Layer)
- 卷积层的任务是提取局部 n-gram 特征。
- 模型使用了多个不同大小的卷积核(例如宽度为 3、4、5),每个卷积核可以看作在句子上滑动的窗口:
- ci=f(w⋅xi:i+h−1+b)
- 其中:
- xi:i+h−1:连续 h 个词的拼接;
- w:卷积核参数;
- b:偏置;
- f:非线性激活函数(如 tanh)。
每个卷积核提取出一个特征图(feature map),捕捉到最显著的局部语义模式,例如:
“don’t rent” → 强烈的负面情绪特征。
卷积操作在两个通道上分别执行,然后结果相加,形成多通道融合特征。
(3)池化层(Pooling Layer)
- 在每个特征图上使用 max-over-time pooling(时间维最大池化)。 它的核心思想是:
- 对于一个特征图,只保留其中最重要(数值最大)的特征响应。
这样可以:
- 自动处理不同长度的句子;
- 捕捉整句中“最显著”的关键信息(比如最情绪化的词组);
- 将每个卷积核的输出压缩为一个单一的标量。
最后所有卷积核的最大值拼接成一个向量,作为句子的全局表示。
(4)全连接层与输出层(Fully Connected + Softmax)
- 池化后的句子向量被送入全连接层;
- 使用 Dropout 随机屏蔽部分神经元(通常比例 0.5),以防止过拟合;
- 最终通过 Softmax 层 输出每个类别(如正面/负面、问题类型等)的概率。
(5)整体结构总结
✅ 通俗理解:
TextCNN 就像一个“句子特征扫描仪”:
- 它先把每个词转成语义坐标;
- 用不同大小的“窗口”扫描整句,找到局部特征;
- 从每个扫描通道中挑出“最显眼的信号”;
- 把这些关键信号汇总,判断整句属于哪种情感或类别。
4、模型的核心不足与后续改进方向
(一)模型的核心不足
虽然 TextCNN 以简洁高效著称,但从研究角度看,它仍存在一些局限性。主要体现在以下几个方面:
1. 缺乏序列与上下文建模能力
- TextCNN 仅通过固定窗口卷积核捕捉局部 n-gram 信息,无法建模长距离依赖关系。
- 例如在句子 “Although the plot was weak, the acting was superb.” 中,情感转折词 “although” 的影响范围较长,而 CNN 的固定窗口难以捕捉这种跨句依赖。
- 这使得模型在需要理解复杂语义逻辑或句法结构的任务(如问答、推理)上表现有限。
2. 结构浅,表达能力受限
- TextCNN 通常只使用 单层卷积 + 池化,虽然简单高效,但缺乏层级语义抽象能力。
- 与图像不同,文本语义是非平移不变的,简单卷积无法形成多层语义组合结构。
3. 词向量表示静态,无法动态适应上下文
- 模型输入的词向量是固定的(word2vec / GloVe),同一个词在不同上下文中语义不变。 例如 “bank” 在 “river bank” 和 “bank account” 中意义完全不同,TextCNN 无法区分。
- 因此它在多义词和语境敏感任务上存在明显缺陷。
4. 缺乏可解释性与句法信息
- CNN 的卷积核提取的是统计式模式(pattern),但并不明确哪些词语或短语起关键作用;
- 模型也不利用句法树或依存关系,因此对句法结构较复杂的文本表现不稳定。
(二)后续模型的改进与优化方向
TextCNN 的简单高效使其成为许多后续模型的**“起点基线”**。研究者们从不同角度对其进行了拓展和改进:
1. 深层与多通道 CNN:增强特征表达能力
- DCNN(Dynamic CNN,Kalchbrenner et al., 2014)
- 使用 动态 k-max pooling 替代单一最大池化,可保留多个关键信息片段;
- 通过多层卷积实现层级语义组合,比 TextCNN 更深。 → 改进了句子表示的丰富性,但代价是计算复杂度更高。
- Char-CNN(Zhang et al., 2015)
- 从字符级建模,摆脱词表限制;
- 结合更深层卷积结构增强语言建模能力。
2. CNN + RNN 混合模型:捕捉长程依赖
- CNN-LSTM / RCNN(Recurrent CNN)
- CNN 用于提取局部特征,RNN(如 LSTM、GRU)用于整合上下文;
- 结合两者优势,既保留 CNN 的高效并行性,又具备序列建模能力。 → 对长文本分类、情感分析表现显著提升。
3. Attention 机制:让模型“聚焦关键信息”
- 在 TextCNN 基础上加入 注意力机制(Attention),让模型自动学习“哪些词更重要”。 例如 ABCNN(Attention-Based CNN,Yin et al., 2016) 就在问答匹配任务中显著改进了表现。 → 解决了传统 CNN 对关键语义缺乏敏感度的问题。
4. 上下文动态词向量:替换静态 embedding
- 随着 ELMo(2018)、BERT(2018) 等出现,词向量从静态变为上下文相关表示(contextual embeddings)。
- 这些模型能根据上下文动态调整词的语义;
- CNN 作为特征抽取器可直接接在这些模型上,进一步提升效果。 → “TextCNN + BERT embedding” 已成为轻量但性能优越的组合。
5. 可解释性与轻量化优化
- Capsule Network(胶囊网络)
- 改进 CNN 在语义层次建模和方向性上的不足;
- 能捕捉特征间的“包含”与“关系”。
- LightCNN / FastText(2017)
- 保留 TextCNN 的高效性,同时进一步减少参数量,提高在移动设备上的部署性能。
(三)小结:TextCNN 的历史地位
✅ 总结一句话:
TextCNN 的贡献在于:证明了简单 CNN 就能有效处理文本分类, 而它的不足正好启发了后续研究——如何让模型看得更远(上下文)、想得更深(语义结构)、更聪明(注意力)、更通用(预训练)。