fastText(2016):虽然浅,但作为速度!效果强基线非常实用
1、研究背景与动机
(1)研究背景:当时的两种主流路线
- 代表模型包括 TextCNN(Kim, 2014)、Char-CNN(Zhang & LeCun, 2015)、VDCNN(Conneau et al., 2016)等;
- 它们通过卷积或循环结构自动学习语义特征,性能优异,但训练慢、资源占用高。
在大规模语料(例如十亿词)上训练这些模型往往需要 GPU、长时间运算。
- 例如 SVM、逻辑回归(Joachims, 1998;McCallum, 1998)等;
- 它们简单高效,但依赖手工特征工程(如 TF-IDF、n-gram),在大型输出空间下泛化能力有限。
(2)动机一:找到“快 + 准”兼得的文本分类基线
“深度模型太慢,线性模型太弱。我们能否找到一种方法——像线性模型一样快,却能接近深度网络的准确率?”
- 保持线性模型的高效率(可在普通 CPU 上运行);
- 引入轻量的词嵌入与特征共享机制,提升模型表达力。 他们希望构建一个“简单但强大的文本分类基线”,既能在小任务中快速验证效果,也能在大规模数据中高效部署
(3)动机二:借鉴词向量学习(word2vec)的思路
“既然 word2vec 能学到好的词向量,我们能否直接把 ‘句子 = 多个词向量平均’ 当作分类特征?”
- 每个单词查表取 embedding;
- 将句子所有词的向量取平均(类似 CBOW 模型);
- 输入线性分类器(softmax)预测标签。
“fastText = CBOW + 分类头”。
(4)动机三:解决大规模分类的计算瓶颈
- 分层 softmax(hierarchical softmax):用霍夫曼树降低计算复杂度,从 O(kh) → O(h log k);
- n-gram 特征 + 哈希技巧:在保持速度的同时捕捉部分词序信息,不依赖复杂的卷积结构。
fastText 能在 十分钟内训练十亿词语料,并在 1 分钟内分类 50 万句子到 31 万类标签,同时准确率接近 CNN、RNN 等深度模型
(5)动机四:工程实用性与可复现性
- 模型结构极其简单(可一页代码实现);
- 在 CPU 上运行即可完成训练与推理;
- 方便与其他模型进行公平比较。
“在深度学习时代,构建一个既快又不‘太傻’的文本分类模型。”
2、模型的核心创新点总结
总体概述
(1)词嵌入 + 线性分类的一体化结构
- 每个词都有一个可学习的向量表示(类似 word2vec 的 lookup table);
- 整个句子的表示是这些词向量的 平均(或加权平均);
- 然后送入一个 线性分类层(softmax) 进行预测。
(2)引入 N-gram 特征 —— 捕捉局部词序信息
- 把词序列中连续的词组当成新的“词特征”;
- 用哈希技巧(feature hashing)将 n-gram 高效映射进固定维度空间;
- 不需要复杂的卷积或循环结构就能捕捉顺序信息。
(3)分层 Softmax(Hierarchical Softmax)—— 大规模分类提速关键
- 把类别组织成一棵二叉树;
- 每次预测时只需从根到叶路径上的概率乘积;
- 复杂度降低到 O(hlogk)O(h \log k)O(hlogk)。
(4)极致的工程优化 —— 简单架构但极快训练
- 不依赖 GPU;
- 采用线性递减学习率;
- 用稀疏更新优化大词表训练。
在相似准确率下,fastText 比深度 CNN 或 RNN 快 数千至上万倍。 例如在 Yelp 和 Amazon 数据集上:
- fastText 训练 1 轮仅需几秒;
- VDCNN、Char-CNN 训练一轮需数小时甚至数天
✅ 小结:fastText 的五大创新
创新点
| 通俗理解
| 带来的好处
|
词嵌入 + 线性模型
| 把“词袋”变成“语义袋”
| 保留语义、训练仍快
|
N-gram 特征
| 简单地加入词序信息
| 提升语义表达能力
|
分层 Softmax
| 用树结构加速分类
| 支持大规模多类别
|
多线程 + 异步优化
| 工程层面极度高效
| CPU 训练即可完成
|
低秩参数共享
| 共用底层语义空间
| 改善稀疏类别泛化
|
🌍 一句话总结
fastText 的“创新”是让简单的模型变聪明,让高效的模型变更强。 它不是靠堆叠深层结构取胜,而是靠 巧妙的结构与工程优化,在“速度 × 准确率”之间取得了最优平衡。 因此,它成为 NLP 实践中最常用、最可靠的轻量级强基线模型。
3、模型结构与运行原理
🔍 一句话概览: fastText 是一个“浅层神经网络”,整体结构就像一个只有 2 层的分类器: Embedding 层 → 句子平均层 → Softmax 输出层。
它的核心思路是:用词向量取代手工特征,用平均取代复杂序列建模。
(一)整体结构示意(对应论文 Figure 1)
输入文本 → 嵌入层(Embedding) → 句子向量(平均) → 输出层(Softmax)
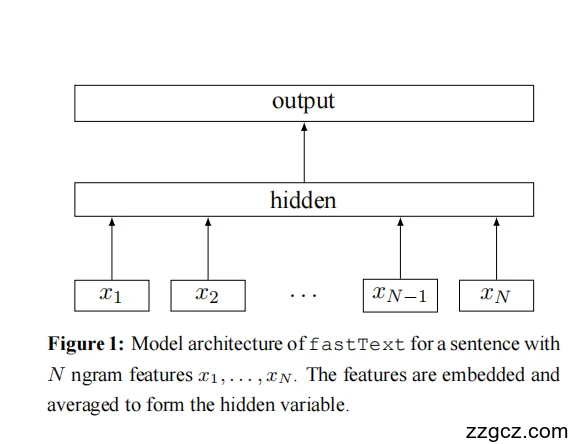
(二)分层讲解
1️⃣ 输入层:词嵌入 (Embedding Layer)
- 每个单词 wiw_iwi 被映射成一个向量 vi∈Rdv_i \in \mathbb{R}^dvi∈Rd。
- 这些词向量可以是随机初始化的,也可以从预训练(如 word2vec)加载。
- 对整句话(或文档),我们取所有词的平均:
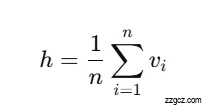
💡 直观理解: 把每个词看成一块拼图,平均操作相当于“融合所有词的语义重心”,得到句子的整体意思。
2️⃣ 特征增强:加入 n-gram 信息
- 每个连续的词组(例如 bigram “not good”)也作为一个“伪词”;
- 利用 哈希技巧(hashing trick) 把它映射到嵌入表中;
- 然后和普通词一起取平均。
💡 举例: “I don’t like this movie” → 普通词向量 + bigram “don’t like”, “like this”, “this movie”。
这样模型就能捕捉到“否定+情感词”的组合特征,而无需复杂的 CNN。
3️⃣ 输出层:Softmax 分类层
- W 是分类权重矩阵(每一行对应一个类别);
- y 是输出的类别分布(例如正面/负面)。
4️⃣ 提速机制:分层 Softmax(Hierarchical Softmax)
- 构建一棵 霍夫曼树(Huffman tree);
- 每个类别是叶节点;
- 模型预测时只需沿着根到叶的路径计算概率。
💡 类比: 就像猜一个单词时,先问“它是名词吗?”→“是动物吗?”→“是狗吗?” 一步步二分决策,大幅减少计算量。
(三)训练与推理过程
- 将每个文本分词;
- 查词向量表(包括 n-gram 向量);
- 计算平均向量;
- 前向预测 + 反向传播;
- 采用 SGD + 多线程 更新参数。
- 只需查词表、平均向量、乘权重、softmax;
- 无需深层结构或 GPU;
- 可在 CPU 上毫秒级完成
4、模型的优势、不足与改进方向
(一)模型优势:“以简单取胜”的极致设计
1️⃣ 速度极快,资源占用极低
- fastText 最大的优势是快:
- 训练阶段完全基于 CPU,多线程 + 分层 Softmax;
- 几分钟可处理上亿样本;
- 预测阶段仅需查词表 + 求平均 + 线性变换。
- 在论文实验中,它比 CNN、RNN 快 1000~10000 倍,而准确率相差不超过 1–2%。
💡 典型应用场景:海量短文本分类(如新闻、评论、广告标签、搜索意图),能快速部署在工业系统中。
2️⃣ 结构简单,可快速复现
- 模型结构仅两层(嵌入层 + 分类层),参数少、代码短;
- 无需 GPU、句法树或复杂预处理;
- 超参数极少(维度、学习率、n-gram 数量),默认配置即能获得稳定性能。
3️⃣ 利用 n-gram 特征,保留局部词序信息
- 通过简单的 n-gram hashing,模型在保持线性速度的同时获得了局部语法感知;
- 对否定词、短语搭配、常见情感结构等表现明显优于传统 BoW(Bag-of-Words)模型。
4️⃣ 可扩展到超大类别空间
- 通过 分层 Softmax(hierarchical softmax),计算复杂度从 O(k) 降为 O(log k);
- 能处理数十万甚至百万级标签任务;
- 特别适合新闻主题分类、多标签广告检索等工业任务。
5️⃣ 泛化能力好,可迁移性强
- 模型的嵌入矩阵(词向量)可复用;
- 对小样本任务同样有效;
- 在多语言、多领域数据集上均表现稳定。
(二)模型不足:“浅层的代价”
1️⃣ 缺乏上下文依赖建模
- fastText 的句子表示是 简单平均;
- 无法理解词语的上下文关系与语序逻辑;
- 对于复杂句子(如反讽、长句、逻辑转折)表现力有限。
例子: “I thought the movie would be great, but it was awful.” fastText 无法正确捕捉 “but” 的转折语义。
2️⃣ 无法建模长距离依赖
- 平均操作会平滑所有词信息;
- 导致关键信号(如情感词、主语谓语关系)被稀释;
- 在需要句法层次理解的任务(如问答、自然语言推理)上表现较差。
3️⃣ 语义歧义问题未解决
- 词向量是静态的,同一个词在不同语境下意义相同;
- 无法区分多义词(如 “bank” 在金融 vs 河岸语境中的不同含义)。
4️⃣ n-gram 仍属局部特征
- n-gram 技巧虽保留部分顺序,但仍是固定窗口;
- 无法捕捉句法结构或句子层次信息;
- 对复杂语言结构(如从句、省略句)能力不足。
(三)与 TextCNN 的对比分析
对比维度
| fastText(2016)
| TextCNN(2014)
| 对比总结
|
模型深度
| 极浅(2层:Embedding + Softmax)
| 较浅(卷积 + 池化 + 全连接)
| fastText 更简单、速度更快
|
特征提取方式
| 平均池化(全局)
| 卷积 + 最大池化(局部特征)
| TextCNN 能捕捉更多上下文特征
|
词序感知
| 通过 n-gram 间接实现
| 通过卷积窗口直接建模
| TextCNN 的顺序建模更自然
|
计算速度
| 极快(CPU 级别)
| 较慢(需 GPU 支持)
| fastText 明显优势
|
参数量
| 极少(百万级)
| 较多(千万级)
| fastText 更轻量
|
表现任务
| 短文本、大规模分类
| 中等长度句子、语义建模
| 各有适用场景
|
泛化能力
| 稳定,易迁移
| 表达力强,需调参
| fastText 适合基线与快速验证
|
结构可扩展性
| 弱(难叠层)
| 可拓展为深层 CNN
| TextCNN 研究潜力更高
|
💬 简而言之:
- TextCNN:特征提取更强,表达力高;
- fastText:速度更快,适合大规模任务。
fastText 是“实用派”;TextCNN 是“表达派”。
(四)后续改进与发展方向
- 例如 Attentive fastText(2018),在平均时引入权重分布,让模型更关注关键信息。
- 使用上下文相关的嵌入(ELMo、BERT)替代静态 word2vec,使模型能理解语境。
- 将 fastText 融入层次分类、多标签任务中;
- 使用共享嵌入层减少多任务间参数冗余。
- Facebook 后续推出了 fastText 库(C++ 实现);
- 支持多语言、在线学习、子词(subword)建模(解决未登录词 OOV 问题)。
✅ 总结一句话
fastText 是“速度与简洁的极致代表”,是深度学习时代最成功的浅层模型之一。
它告诉我们:
- 不一定非要深才强;
- 合理的嵌入、简洁的结构、巧妙的工程优化,也能在实践中表现惊人。
它与 TextCNN 的关系,就像“小巧的快刀”与“厚重的砍刀”—— 一个追求高效,一个追求表达力,各自代表了不同方向的优秀基线。