DETR(2020):Transformer 检测开山之作,端到端目标检测,算法创新的起点
导出时间:2025/11/23 20:27:37
1、研究背景和动机
(1)传统目标检测方法的套路
在 DETR 出现之前,主流的目标检测方法(例如 Faster R-CNN、YOLO、SSD 等)大多遵循一个固定套路:
- 候选区域/锚框(anchor):在图像上先生成一大堆“假设框”。
- 特征提取:用 CNN 提取图像特征。
- 分类 + 回归:在这些候选框上判断是什么类别,并精修框的位置。
这种方式虽然效果好,但有几个问题:
- 设计复杂:需要手工设置锚框的大小、长宽比,调参麻烦。
- 后处理繁琐:需要 Non-Maximum Suppression(NMS,非极大值抑制)来去掉重叠框。
- 整体像“流水线”:由多个独立的模块拼起来,不是端到端的学习。
(2)NLP 中 Transformer 的启发
在自然语言处理领域,Transformer 模型大获成功,它可以:
- 直接基于“注意力机制”学习全局关系;
- 把输入看作一个序列进行建模,而不依赖局部的卷积或手工先验。
研究者们就想:
👉 能不能用类似的方式,把目标检测也变成一个“序列到序列”的任务?
- 输入:图像特征序列;
- 输出:目标的集合(目标类别 + 位置)。
(3)DETR 的核心动机
于是,Facebook AI(Meta AI)团队提出了 DETR(2020),它的动机就是:
- 去掉锚框:不再需要复杂的 anchor 设置。
- 去掉 NMS:让模型自己学会“一次性”输出目标集合。
- 端到端训练:输入图像 → 输出检测结果,中间不再是多个手工模块拼接。
- 统一视角:把目标检测问题看作一个直接的序列预测任务,借助 Transformer 的强大全局建模能力来完成。
简单来说,DETR 想解决的问题是:
❌ 传统检测器复杂、繁琐、靠手工经验;
✅ DETR 追求简洁、优雅、端到端。
2、DETR 的核心创新点总结
把目标检测问题变成“序列到序列”的任务
传统目标检测模型(比如 Faster R-CNN、YOLO)通常要用到 锚框(anchor boxes)、候选区域 或者一些额外的设计来预测物体的位置。
而 DETR 的思路很不一样:它直接把目标检测当作一个“翻译问题”。
- 输入:一张图片。
- 输出:一串“描述”,每个描述对应图片里的一个物体(位置 + 类别)。 这就像把“图像语言”翻译成“物体语言”。
用 Transformer 来建模全局关系
以往的卷积神经网络(CNN)擅长捕捉局部特征,但对全局的物体关系理解不够强。
DETR 使用了 Transformer 的自注意力机制(self-attention),能同时关注图像的所有区域,从而更好地理解:
- 哪些像素属于同一个物体;
- 不同物体之间的位置关系;
- 背景和前景的区分。
这让 DETR 在复杂场景(例如多个物体重叠、相互遮挡)时表现更好。
引入“物体查询(object queries)”的概念
DETR 在 Transformer 解码器中使用了一组 固定数量的“查询向量”,每个查询会去“询问”图像里是否有对应的物体。
- 类似于一个侦探小组,每个侦探负责去发现一个可能的物体。
- 最终每个查询会输出一个预测框(bounding box)和类别。
这种设计 避免了锚框的复杂设定,简化了检测流程。
使用集合匹配(Set Matching)训练方式
DETR 引入了 匈牙利匹配(Hungarian Matching),在训练时把预测的物体结果和真实标注一一对应。
- 这样模型学到的就是“集合到集合”的匹配,而不是像传统方法那样在一堆候选框里挑选。
- 结果是 预测更直接、更稳定,并且减少了后处理步骤(例如 NMS 非极大值抑制)。
总结
DETR 的核心创新点就是:
- 把目标检测改造成序列预测问题,用 Transformer 来解决;
- 全局建模能力,能更好地理解复杂场景;
- 物体查询机制,无需锚框,预测更简洁;
- 集合匹配训练,避免冗余预测,结果更清晰。
一句话总结:DETR 用 Transformer 把目标检测变得更“端到端”、更干净、更优雅。
3、模型的网络结构
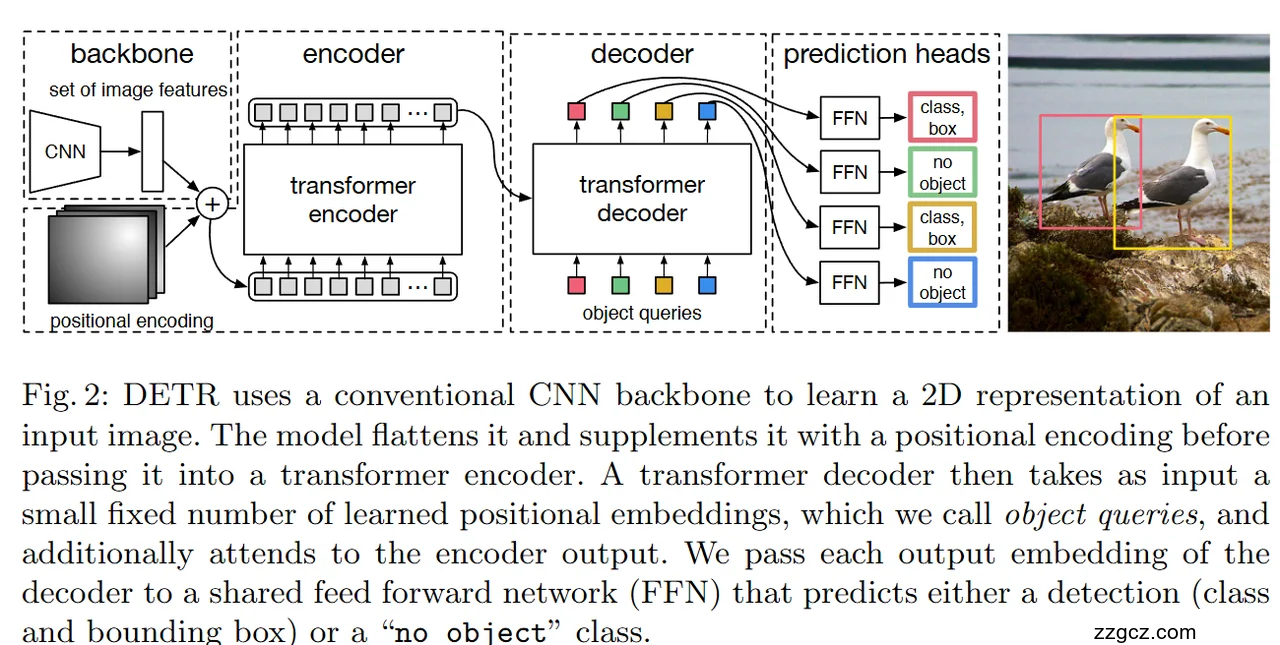
下面按图中从左到右的流程,把 DETR 的整体结构拆开讲清楚:
① Backbone:CNN 特征提取
- 作用:把输入图片变成一个二维的高层语义特征图(feature map)。
- 形式:常用 ResNet 等 CNN。输出尺寸相对原图下采样(例如步幅 32),通道数较大(C)。
- 结果:得到大小约为
C × H' × W'的特征图(H'、W' 是下采样后的高宽)。
② Positional Encoding:位置编码并展开为序列
- 为什么要加:Transformer 不知道“哪块特征在图像的哪个位置”,位置编码提供绝对/相对位置信息。
- 怎么做:对二维特征图每个格子注入一个 2D 的正弦余弦位置编码,然后与特征相加。
- 展平:把
H' × W'的二维网格 flatten 成长度为N = H'×W'的序列,每个位置是C维向量。
- 到这里,我们把一张图变成了带位置的特征序列。
③ Encoder:Transformer 编码器(全局建模)
- 输入:上一步的特征序列(带位置编码)。
- 结构:多层自注意力(Multi-Head Self-Attention)+ 前馈网络(FFN)。
- 关键点:自注意力让每个位置都能“看见”全图的其他位置,学到跨区域的依赖与关系。
- 输出:与输入等长的序列(通常称为 memory),携带了更强的全局上下文。
④ Object Queries:可学习的“物体查询”向量
- 是什么:一组固定数量(比如 100 个)的可学习向量,图里五颜六色的小方块就是它们。
- 直观理解:把它们看作若干个“检测插槽”或“侦探”,每个查询负责去图里寻找一个可能的目标。
- 为什么需要:代替传统检测里的锚框/候选框;模型直接输出一个固定大小的集合。
⑤ Decoder:Transformer 解码器(查询 × 图像特征)
- 输入:上面的 object queries(作为查询 Q)以及编码器的输出 memory(作为键 K、值 V)。
- 机制:
- 自注意力:查询之间相互交互,避免重复、学到去重与分工。
- 交叉注意力:每个查询去“关注”编码器输出的图像特征,决定自己代表哪个物体/区域。
- 输出:与查询数相同的向量集合(每个查询对应一个输出嵌入)。
⑥ Prediction Heads:共享的预测头
- 做什么:把每个解码器输出嵌入,送入同一套(权重共享)的前馈小网络(图中多块 FFN 只是表示多次调用)。
- 输出两类结果:
- 分类:目标类别的概率分布,包含一个特殊的 “no object” 类(表示这个查询没有匹配到任何物体)。
- 边框回归:预测框参数(通常是中心点
(cx, cy)和宽高(w, h),常用 Sigmoid 约束到 0–1)。
由于查询个数是固定的(如 100),模型每次都会输出 100 个“候选”,其中一部分会被判为 no object,剩下的就是最终检测结果,无需 NMS 之类的后处理。
一图读懂(与你图的对应关系)
- backbone:左侧 CNN 模块 → 产生 2D 特征。
- positional encoding:左下角“positional encoding” 与特征相加。
- encoder:中左的 transformer encoder → 产生全局上下文的 memory。
- decoder + object queries:中间的 transformer decoder 下面彩色方块是 queries;弧线表示查询与 memory 的交互。
- prediction heads:右边多次重复的 FFN → 对每个查询分别输出 “class, box” 或 “no object”。
4、模型的缺陷与不足
1. 收敛速度慢
DETR 在训练时往往需要更长的周期才能达到较好的性能。
- 原因:模型中的查询(object queries)在初始阶段没有任何位置信息或先验,只能从零开始学习。
- 形象化理解:这就像派出一组“新手调查员”去寻找物体,但他们没有任何提示,只能在整张图片里盲目搜索,所以需要很长时间才能熟悉任务。
对小目标检测效果差
DETR 主要依赖单一尺度的特征图,分辨率较低,小物体信息容易丢失。
- 原因:下采样导致小物体特征模糊,加之全局建模机制没有显式的多尺度偏置。
- 形象化理解:就好比我们只用“远景相机”观察画面,很容易忽视角落里的小昆虫或远处的小鸟。
计算复杂度高
编码器采用全局自注意力,每个位置都要和所有其他位置进行交互,复杂度近似于图像像素数的平方。
- 形象化理解:这类似于一个会议,每个成员都要和所有其他成员逐一交流一次,信息全面但效率极低。
固定数量的预测限制
DETR 的预测数量由查询个数决定(如 100 个),如果场景中实际目标数量接近或超过这个上限,就可能出现漏检。
- 形象化理解:这就像你只派出固定数量的调查员去记录画面里的物体,即使画面里物体更多,也最多只能报出 100 个。
定位学习难度大
DETR 直接让模型输出边界框的中心点与宽高,没有传统方法中的锚框作为参考。
- 结果:早期训练阶段模型经常给出不稳定或偏差很大的预测框。
- 形象化理解:相当于让一个新人直接凭空画出“物体框”,缺少初始参考点,容易画偏。
5、后续模型核心改进方向:多尺度(像多镜头) + 稀疏/可形变注意(只看重点) + 给查询线索/粗框(不瞎跑)。
下面按“问题 → 改法 → 直白理解 → 效果”来讲。
A. 小目标差/训练慢/算力重 → Deformable DETR:只看重点 + 多镜头
- 改法:
- 用多种尺寸的特征(像广角 + 长焦多镜头)。
- 注意力不再看整张图,而是围绕若干参考点抽样少量位置(可形变注意力)。
- 理解:拿着手电筒只照“可能有东西”的地方,而不是把整个球场都照亮。
- 效果:训练快很多、小目标也更稳,计算开销明显下降。
- 两阶段版本:先用“粗筛”找一批可能的框,再交给解码器精修(更稳)。
B. 没线索/定位不稳 → 给查询加“起始线索/粗框”
- Conditional DETR:把“你要找什么”(内容)和“去哪儿找”(位置提示)分开,侦探先有方向。
- DAB-DETR(动态锚框):每个侦探自带一个粗框当起点,随着层数一步步细化。
- Anchor-DETR:用预先布好的规则锚点当起点。
- 效果:侦探不再瞎转圈,更快收敛、定位更准。
C. 学习难/正样本少 → DN-DETR / DINO:先做“带答案的练习题”
- DN-DETR(去噪训练):把真实标注稍微打乱(加噪)当作额外练习题喂给模型,让它先学会把噪声改回真值。
- 理解:先用“答案在旁边”的题热身,再做真正的考试题。
- DINO:把上面的好点子打包升级(去噪 + 动态锚框 + 多尺度 + 更强数据增广 + 一对多辅助监督),成为更强的“通用好用版”。
- 效果:训练更稳更快,准确率显著提升。
D. 工程化/上设备/追速度 → RT-DETR 等
- 做法:轻量骨干、窗口/稀疏注意力、并行友好设计。
- 效果:在保持不错精度的同时,实时推理更容易。