DINO (2022):基于改进的去噪锚框的DETR用于端到端目标检测,改进版 DETR,学术界基线,入门最后一站
导出时间:2025/11/23 20:29:55
1、研究背景与动机
一、研究背景
- 传统目标检测方法的局限
- 早期的目标检测主要依赖 卷积神经网络(CNN),例如 Faster R-CNN、YOLO、RetinaNet 等。
- 这些方法往往依赖 人工设计的组件,如:
- 锚框(anchor boxes):需要人为设定不同大小和比例的候选框。
- 非极大值抑制(NMS):用于去除重复预测框。
- 这种设计虽然效果不错,但人工成分较多,难以做到真正的端到端学习。
- DETR 的出现
- 2020 年,Facebook 提出了 DETR (DEtection TRansformer)。
- 最大的创新:
- 把目标检测转化为 集合预测问题,利用 Transformer 直接预测物体的类别和位置。
- 不需要锚框设计和 NMS,是真正的端到端检测器。
- 但是,DETR 也有明显问题:
- 收敛速度很慢:训练需要数百个 epoch 才能达到较好效果。
- 查询(query)含义不清晰:难以稳定学习到好的检测能力。
- 改进的 DETR 系列
- 为了克服 DETR 的缺点,研究者提出了许多改进:
- Deformable DETR:引入可变形注意力机制,加快训练。
- DAB-DETR:把查询设计成 动态锚框,更直观地对应目标位置。
- DN-DETR:加入 去噪训练(denoising training),加速收敛并增强稳定性。
- 尽管这些改进提升了性能,但 DETR 系列整体表现仍然落后于一些经过高度优化的传统检测器(如 Swin Transformer + HTC++ 框架)。
- 为了克服 DETR 的缺点,研究者提出了许多改进:
二、研究动机
- 解决 DETR 类模型的两个核心问题
- 性能差距:在 COCO 数据集上,最好的 DETR 类模型仍低于 50 AP,而经典检测器可以轻松超过。
- 可扩展性不足:缺少在更大主干网络(如 Swin Transformer)和更大数据集(如 Objects365)上的系统研究。
- 研究目标
- 让 DETR 类模型既快又准,缩小与优化版 CNN 检测器之间的差距。
- 探索可扩展性:证明 DETR 类模型不仅能在小规模实验中有效,也能在大模型和大数据下达到 SOTA(state-of-the-art)。
- 核心思路
- 结合 DAB-DETR(动态锚框) 和 DN-DETR(去噪训练) 的优势。
- 引入 新的改进:
- 对比去噪训练(Contrastive DN):解决重复预测、提升小目标检测效果。
- 混合查询选择:更好地初始化锚框,提高查询质量。
- 向前看两次机制:让后续层的预测信息反过来优化前面层的学习。
✅ 总结一句话:
DINO 的动机就是 —— 在 DETR 的端到端检测优势基础上,通过新的训练策略和查询机制,解决训练慢、性能差、扩展性不足的问题,让基于 Transformer 的检测器真正能在大规模任务中超越传统 CNN 检测器
2、DINO 的核心创新点
一、对比去噪训练(Contrastive Denoising Training,CDN)
- 传统 DN-DETR 问题 DN-DETR 在训练时会往真实标注框(GT box)里加噪声,然后训练模型去“还原”它。 → 好处:能加速收敛,让模型学会利用邻近的锚点预测目标。 → 问题:模型容易“混淆”,多个相邻锚点可能都预测到同一个物体,导致重复框。
- DINO 的改进
提出 对比去噪训练:
- 每个 GT 框生成两种锚点:
- 正样本(小噪声) → 期望预测目标。
- 负样本(大噪声) → 期望预测“无目标”。
- 这样训练能让模型学会区分“哪个锚点是真的在目标上,哪个只是干扰”。
- 每个 GT 框生成两种锚点:
- 直观类比 就像学生做题:给他两道相似的题,一道是真题,一道是陷阱题。训练后,他能更快学会“不要被迷惑”,答案更准确。
二、混合查询选择(Hybrid Query Selection)
- 传统 DETR 的问题
- DETR 里的查询(query)是“凭空学来的向量”,缺乏空间信息。
- Deformable DETR 改进后,可以从编码器输出中选 top-K 特征来初始化,但可能引入模糊信息(比如选到的特征可能覆盖多个目标)。
- DINO 的改进
提出 混合查询选择:
- 位置查询(positional query) → 用编码器输出的 top-K 特征来初始化,提供空间先验。
- 内容查询(content query) → 保持可学习,不直接用 top-K 特征,以避免歧义。
- 直观类比
好比侦探破案:
- “位置查询”就像根据监控录像先锁定几个可疑地点。
- “内容查询”则是调查员凭经验继续深挖。
- 两者结合,既有空间线索,又保留学习自由度。
三、向前看两次(Look Forward Twice,LFT)
- 传统方法:Look Forward Once
- 在 Deformable DETR 中,解码器逐层 refine 框,但梯度只从当前层往前传,前面层无法利用后面 refine 的信息。
- 结果 → 早期层学得不够好。
- DINO 的改进
- 提出 向前看两次:
- 每一层的参数更新,不仅依赖本层的预测,还能利用 下一层 refine 后的预测。
- 等于“前一层能从后一层学经验”。
- 提出 向前看两次:
- 直观类比
就像写作文:
- 以前的方法是“写完初稿→改稿→定稿”,但初稿没机会学到后面怎么修改。
- DINO 的方法是“初稿在修改过程中也能看到老师的修改意见”,所以写得越来越准。
四、总结
DINO 的三大核心创新点可以用一句话概括:
- 对比去噪训练 → 让模型学会“分辨真伪锚点”,避免重复预测。
- 混合查询选择 → 把空间线索与可学习内容结合,初始化更合理。
- 向前看两次 → 利用后续层的经验指导前面层,提升框预测精度。
最终效果:训练更快、检测更准,尤其在小目标和大规模预训练场景下,DINO 超越了传统 CNN 检测器
3、模型的网络结构
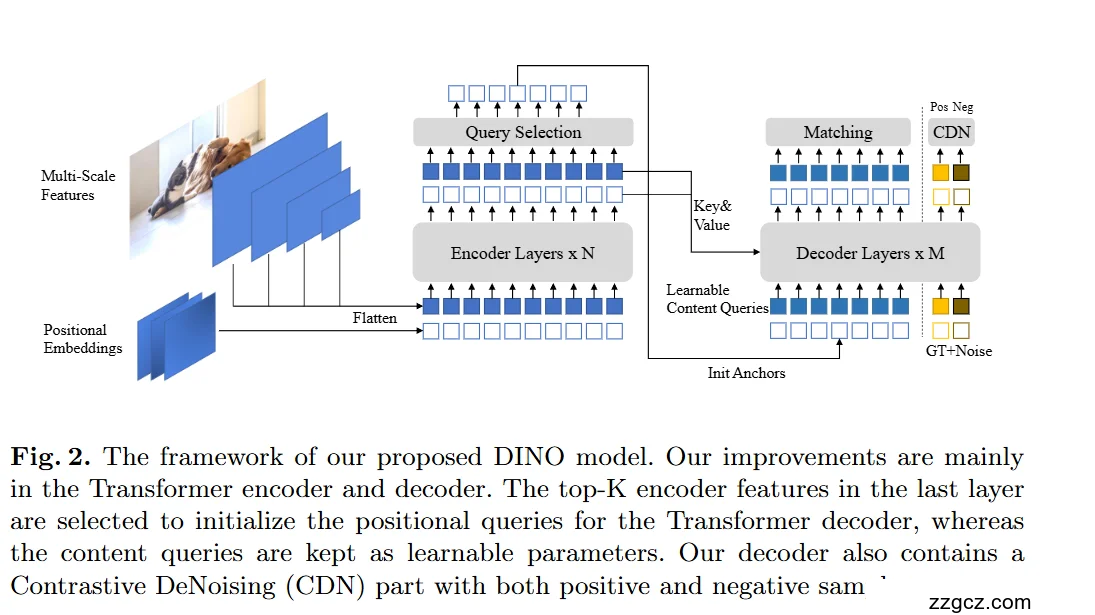
DINO 网络结构(按图自左向右)
- Backbone 多尺度特征 + 位置编码
- 用 ResNet/Swin 等主干抽取 多尺度特征(通常是 4~5 个尺度的金字塔)。
- 对各尺度特征 Flatten 后,加上 Positional Embeddings(位置编码),作为 Transformer 的输入 token。
- Transformer Encoder(×N 层)
- 编码器对多尺度 token 做特征增强(论文实现采用 Deformable Attention,在参考框附近稀疏采样,效率高)。
- 编码器输出作为 Key/Value 提供给后续解码器使用。
- Query Selection(查询选择)
- 在最后一层编码器输出上,选出 top-K 的位置(根据一个轻量的 scoring 头/客观性得分),作为解码器“位置查询”的初始化;这些位置被显式表示成 锚框(anchor box / reference box)。
- 内容查询(Content Queries)仍是可学习参数,不直接用编码器特征初始化——避免把含糊的局部内容直接灌进解码器。
- 这叫 混合查询选择:位置来自图像、内容保持可学习。图中蓝色方块上方的「Query Selection」和右下角的 Init Anchors 箭头对应这一过程。
- Transformer Decoder(×M 层)
对每一层,解码器执行:
- 自注意力:不同查询(候选目标)之间交互,抑制重复、分工协作。
- 交叉注意力:以查询自带的参考框为中心,在编码器特征上做可变形采样聚合证据。
- 预测头:输出
- 分类 logits(含 no-object 类别),
- 边框回归 偏移量(对当前参考框进行 refine)。
- 迭代细化:本层回归出的偏移量更新参考框,供下一层继续 refine(图中解码器层堆叠与向前箭头)。
直观上:每个查询就是“一个候选目标”。它带着一个“我大概在这儿”的锚框去对图像问讯,层层细化,框越来越准。
- Matching(集合匹配分配)
- 在主分支(蓝色查询)上,使用 Hungarian 匹配 将最终预测与 GT 一一对应,计算集合损失(分类:Focal Loss;回归:L1 + GIoU),并在每层都加辅助损失促收敛(图中「Matching」)。
- CDN:对比去噪分支(只在训练时启用)
- 右侧黄色的 CDN(Contrastive DeNoising)会在 GT 上注入两档噪声生成额外查询:
- 正样本(Pos):小噪声,目标是重建对应 GT 框与类别;
- 负样本(Neg):较大噪声,目标是预测 no-object。
- 这些带噪查询与主分支共享同一个解码器,共同训练;通过“正负对比”,模型学会区分“哪个锚是真命中的、哪个只是近邻干扰”,显著减少重复框、提升小目标表现。训练仍使用 Focal + L1 + GIoU。推理时 CDN 分支被移除。
训练/推理时的数据流
- 训练: Backbone → Encoder → (A)主分支:Query Selection 产生初始化锚 + 可学习内容查询 → Decoder(逐层 refine)→ Matching 损失; (B)CDN 分支:由 GT+Noise 生成 Pos/Neg 查询 → 同一个 Decoder → 与主分支一起计算损失。
- 推理: 仅走 主分支(不启用 CDN),解码器输出的一组去重后的目标,即为最终结果(端到端、无需 NMS)。
关键设计与图中要点的对齐
- “Multi-Scale Features / Positional Embeddings / Flatten” → 编码器输入。
- “Encoder Layers × N” → 多层特征增强,输出 Key & Value。
- “Query Selection + Init Anchors” → 以 top-K 编码器特征初始化位置查询(锚),内容查询可学习。
- “Decoder Layers × M” → 自注意 + 交叉注意,层层 box refine;每层有辅助预测头。
- “Matching” → 一对一集合匹配与分配损失。
- “CDN(Pos/Neg) + GT+Noise” → 训练期对比去噪查询,提升稳定性与去重能力。
一句话小结
DINO = 混合查询选择(位置由编码器 top-K 初始化,内容可学习)
- 可变形注意的编解码器(多尺度、迭代细化)
- 对比去噪分支(正负带噪查询联合训练) → 端到端、无需 NMS、收敛更快、精度更高。