Deformable DETR(2021):用于端到端目标检测的可变形Transformer,加速收敛,关键改进版
导出时间:2025/11/23 20:28:45
1、研究背景和动机
✅ 总结一句话: Deformable DETR 的提出,是为了继承 DETR 的“简洁端到端”优势,同时解决其“训练慢、小目标难”的致命问题。研究者通过引入可变形注意力和多尺度特征,把 DETR 从一个“笨拙但有潜力的学徒”,打造成了“高效且灵活的专家”。
从传统检测器到 DETR
在目标检测领域,早期方法(如 Faster R-CNN、RetinaNet)都依赖很多 手工设计的组件,比如:
- 锚框(anchor boxes):预设不同大小和长宽比的矩形框,模型需要在这些候选框里判断有没有目标。
- NMS(非极大值抑制):后处理步骤,用来去掉重叠度过高的框。
这些机制虽然有效,但复杂度高、需要大量超参数调试,也不是真正端到端的。
2020 年提出的 DETR 试图解决这个问题:它用 Transformer 编码器-解码器 结构,直接把目标检测转化为 “集合匹配”问题,从而摆脱锚框、NMS 等手工设计。DETR 的设计非常优雅简洁,被认为是一次重要的突破
DETR 的主要问题
虽然 DETR 思路新颖,但它在实际应用中暴露出严重问题
- 训练收敛慢
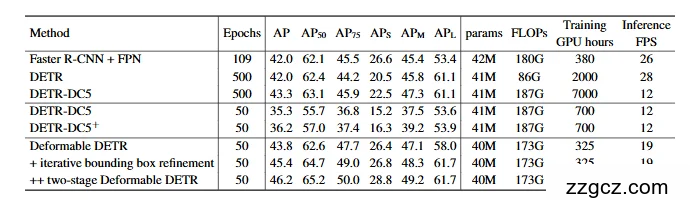
- 在 COCO 数据集上,DETR 通常需要 500 个训练周期才能收敛,而 Faster R-CNN 只要几十个周期。
- 原因在于:Transformer 的注意力机制一开始对整张特征图平均关注,需要很长时间才能学会聚焦到目标上。
- 小目标检测效果差
- DETR 主要依赖单一分辨率的特征图,对小物体的特征表达不足。
- 高分辨率特征虽然能帮助检测小目标,但计算复杂度会变得难以承受(注意力机制复杂度随像素数平方增长)。
换句话说,DETR 就像一个“很聪明但新手的学徒”,虽然方法优雅,但一开始没有任何线索去寻找目标,需要花大量时间自我学习,而且容易忽略小而重要的细节。
Deformable DETR 的动机
研究者们的目标是:
- 保持 DETR 端到端的优雅性(不回到锚框/NMS 这种复杂机制)。
- 解决收敛慢和小目标检测差的问题。
于是,他们从 可变形卷积(Deformable Convolution) 得到启发:
- 卷积本来是固定在规则网格上采样,而 可变形卷积允许模型自动选择少量关键点进行采样,从而在不增加大量计算的前提下捕捉目标的关键区域。
Deformable DETR 借鉴了这个思路:
- 提出了 可变形注意力(Deformable Attention),让注意力机制不再平均关注整张特征图,而是只聚焦在目标附近的少量采样点。
- 同时结合 多尺度特征图,显著增强对小目标的建模能力。
结果就是:
- 在 COCO 数据集上,训练周期减少 10 倍,性能反而比 DETR 更好,尤其是小目标检测能力显著提升
2、核心创新点总结
1. 提出 可变形注意力机制(Deformable Attention)
- 传统问题:在原始 DETR 中,Transformer 的自注意力要在整张特征图上“平均交流”,这导致计算量巨大(复杂度随像素数平方增长),而且模型很难快速学会聚焦目标。
- 创新点:Deformable DETR 借鉴“可变形卷积”的思想,让注意力不再对全图计算,而是只在少量关键采样点上聚焦。
- 直观理解:
- 可变形注意力更像“直接去找几个和自己最相关的同学聊天”,既快又有效。
- 效果:大幅降低计算复杂度,模型更快学会聚焦到物体区域。
引入 多尺度特征融合
- 传统问题:DETR 只用单一分辨率特征图,对小目标检测能力不足。
- 创新点:Deformable DETR 把 多尺度特征(高分辨率看小物体、低分辨率看大物体)同时输入到 Transformer。
- 直观理解:
- 就像给模型配备了“放大镜”和“广角镜”,既能看清角落里的蚂蚁,也能看清整张画面的大象。
- 效果:小目标检测能力显著提升,同时保持大目标的检测精度。
3. 显著加快收敛速度
- 传统问题:原始 DETR 在 COCO 上要训练 500 个 epoch 才能收敛,比传统检测器慢太多。
- 创新点:由于可变形注意力更高效、更聚焦,模型学习效率大幅提升。
- 效果:
- 在相同性能下,Deformable DETR 只需要 50 个 epoch,训练速度提升 10 倍。
- 这使得 DETR 系列第一次具备了实际落地应用的可行性。
支持 两阶段检测(可选模式)
- 原始 DETR:所有预测都来自随机初始化的查询向量,缺少引导。
- 创新点:Deformable DETR 可以先由编码器生成一批 候选框(proposal),再把这些候选作为查询输入解码器。
- 直观理解:
- 原始 DETR 像“毫无头绪地到处找”;
- 两阶段版本相当于“先粗筛一遍,再把可能的目标交给专家精修”。
- 效果:进一步提升收敛速度和检测精度。
3、可变形注意力机制
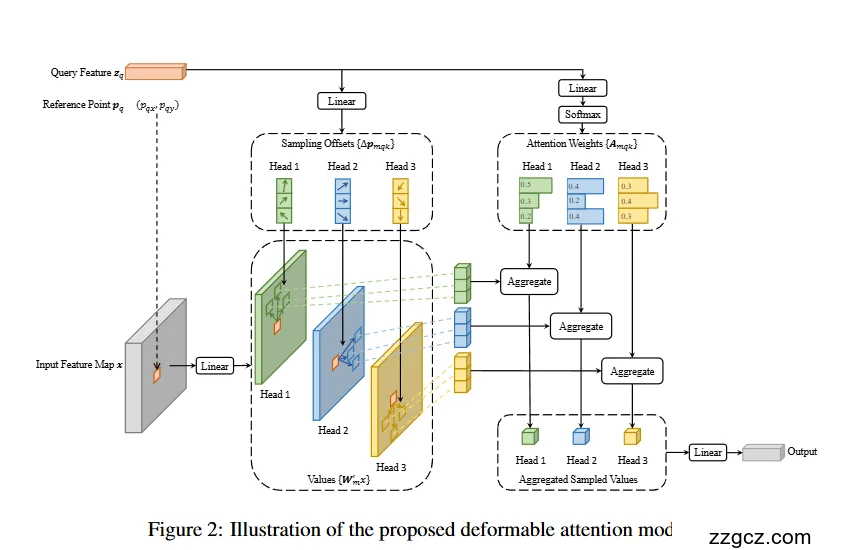
(a) 输入
- Query Feature zq:查询特征,通常是目标检测中的查询向量。
- Reference Point pq = (px, py):查询对应的参考点(位置),比如初步预测的物体位置。
- Input Feature Map x:来自 backbone 的图像特征图。
(b) 采样位置生成
- Query 特征经过 Linear 映射,得到每个注意力头的 采样偏移量 (Δp)。
- 例如,Head 1 偏移 (↖↘),Head 2 偏移 (↑↓),Head 3 偏移 (↔)。
- 这些偏移加在 参考点 pq 上,得到一组采样位置。
直观理解: 参考点好比你大概知道“猫在这里”,然后每个 head 学习不同的“观察角度”,在参考点附近采几个点。
(c) 从特征图采样
- 根据采样位置,从 输入特征图 x 中取值(这里用双线性插值获取非整数坐标的特征)。
- 每个 head 会采到一小组特征值。
(d) 注意力权重计算
Query 特征再经过 Linear + Softmax,生成每个 head、每个采样点的 权重 A。
例如,Head 1 可能分配 (0.2, 0.5, 0.3),表示更关注某些采样点。
(e) 聚合
- 每个 head 将采样值按权重加权求和,得到一个聚合特征。
- 不同 head 的结果再合并,经过一个 Linear,输出最终的特征。
4、Figure 1: Deformable DETR 整体框架图
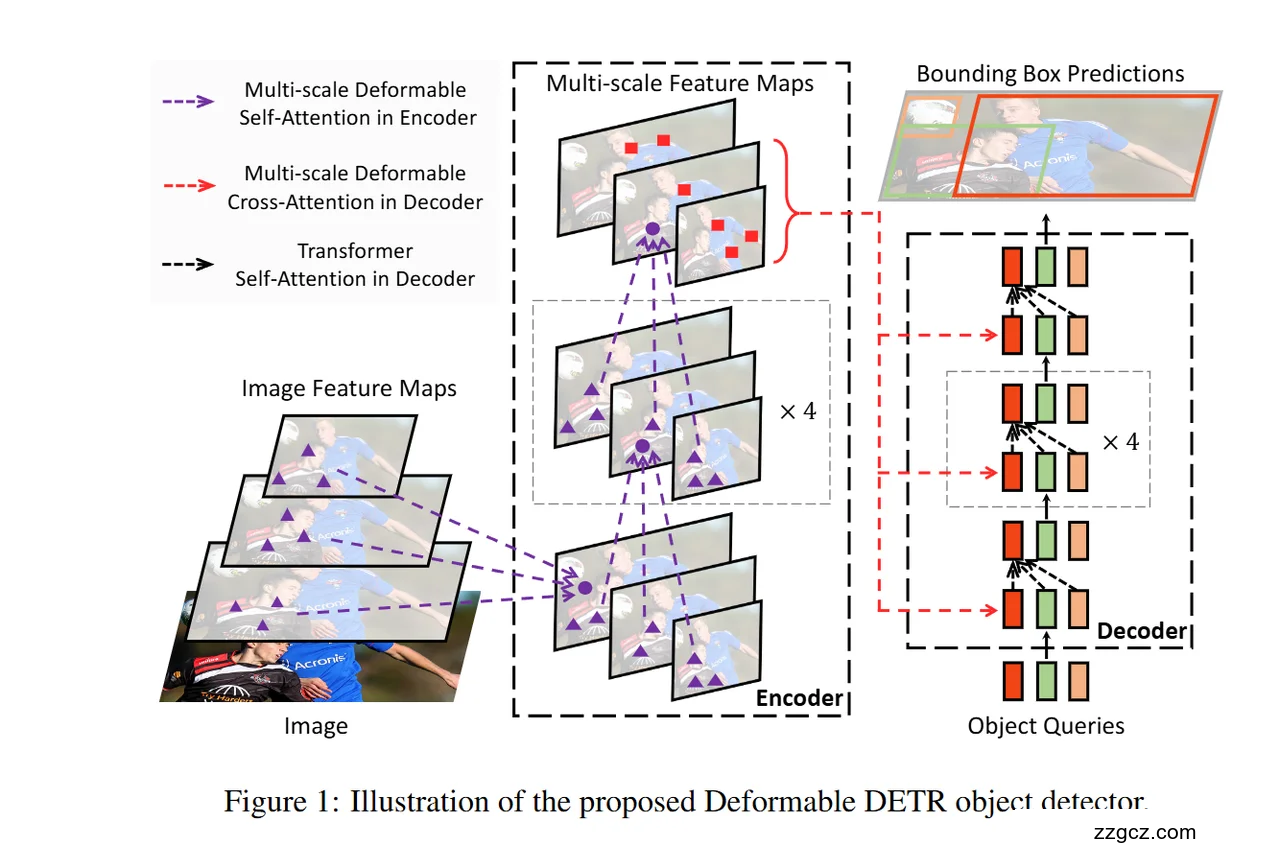
1. 输入与特征提取
- Image → Image Feature Maps
原始图像先经过 CNN(如 ResNet + FPN)提取出不同分辨率的特征图(multi-scale feature maps)。
- 低层特征:分辨率高,细节多。
- 高层特征:语义强,但分辨率低。
👉 多尺度特征对于检测大小不同的目标很关键(小目标靠高分辨率,大目标靠语义特征)。
Encoder:多尺度可变形自注意力
- 图中紫色虚线箭头: Multi-scale Deformable Self-Attention in Encoder。
- Encoder 会处理多尺度特征图,利用 Deformable Attention 机制(你在 Figure 2 看到的模块)。
- 每个位置只在少数采样点上做注意力,而不是全局。
- 这样 Encoder 能高效整合多尺度上下文信息。
👉 相比原始 DETR 的全局自注意力,计算量大大降低。
Decoder:多尺度可变形交叉注意力
- 输入:Object Queries(相当于 N 个“检测目标槽位”,等待填充为物体预测)。
- Decoder 包含两类注意力:
- 自注意力 (black dashed line):Queries 之间互相交互,避免重复预测同一个物体。
- 跨注意力 (red dashed line):Queries 去关注 Encoder 的特征图(跨尺度),通过 Deformable Cross-Attention 聚合相关的特征。
👉 这样,每个 Query 都能灵活地从多尺度特征图中采样信息,逐渐“收敛”为某个物体的表示。
输出:边界框预测
- Decoder 的每一层都会输出一批 边界框预测 (Bounding Box Predictions)。
- 最终输出包含:
- 预测的目标类别
- 边界框位置 (x, y, w, h)
训练时,和真实标注框进行 Hungarian Matching(一一匹配),使得 Query 和真实物体对应上。
直观理解
你可以这样理解整张图的流程:
- CNN → 多尺度特征图 (看图像不同层次的内容)
- Encoder → 压缩整理信息 (用高效的 Deformable Attention 整合上下文)
- Decoder → 目标查询 (像一个个“空槽位”去问:这里有猫吗?那里有狗吗?)
- 输出检测框 (最终每个 Query 给出一个物体预测或空预测)
与原始 DETR 的区别
- 原始 DETR:全局注意力,收敛慢,检测小目标困难。
- Deformable DETR:
- 多尺度特征 → 更适合小目标检测。
- 可变形注意力 → 计算更快(只看部分关键点)。
- 收敛速度更快,检测精度更高。
5、模型的严重缺陷和后续的模型如何基于此改进与创新
一、Deformable DETR 的严重缺陷
虽然 Deformable DETR 相比原始 DETR 已经大幅提升,但它依旧存在一些痛点问题:
- 推理速度依旧偏慢
- 尽管通过 稀疏采样(deformable attention) 降低了复杂度, 但 Decoder 依旧要多层迭代更新 object queries,导致推理速度在实时应用(如自动驾驶、视频检测)中仍然不够快。
- 对小目标检测仍然有限
- 引入 多尺度特征 后,小目标检测有所改善,但由于:
- 小目标本身特征弱;
- query 数量固定(可能浪费在背景上); 检测小目标时仍不够稳健。
- 模型训练依赖大数据集
- 虽然比原始 DETR 收敛更快(50 epoch vs. DETR 的 500 epoch), 但对 数据和算力的需求依旧很高,在小规模数据集上泛化不佳。
- Query 表达方式较死板
- 每个目标 query 本质上是一个随机初始化的向量,通过训练学习到“物体槽位”的语义。
- 但这种表示比较“抽象”,缺乏显式的先验,可能浪费了学习资源。
二、后续改进与创新方向
在 Deformable DETR 之后,学界和业界提出了许多改进方案,可以归纳为以下几类:
1. 提高收敛和推理速度
- DN-DETR (Denoising DETR, 2022)
- 在训练时引入“噪声标签 + 匹配”任务,加快训练收敛。
- 让模型更快学会如何做匹配,而不是完全依赖 Hungarian Matching。
- DAB-DETR (Dynamic Anchor Boxes, 2022)
- 不再用随机初始化 query,而是用 可学习的 anchor(位置先验) 作为 query 起点。
- 更快收敛,更直观地对应到边界框预测。
- Anchor-DETR
- 将 anchor-based 检测器的 prior 融入到 DETR 中,提高速度和精度。
2. 增强小目标检测
- SMCA (Spatially Modulated Co-Attention)
- 给 query 附加空间分布约束,让注意力聚焦在合理区域,而不是到处乱搜。
- 对小目标检测更友好。
- Conditional DETR
- 用条件注意力机制,把 query 和图像特征更紧密地绑定,提升对小物体的感知。
3. 利用更强的特征金字塔
- Deformable DETR 本身用了多尺度,但后续工作进一步强化:
- 改进 跨尺度交互(让高低层特征更好融合)。
- 在语义上增强小目标的分辨能力。
4. 简化结构,走向实用化
- Efficient DETR 系列:在保持 Transformer 架构的同时,减少 Decoder 层数或优化注意力机制。
- YOLOv8, RT-DETR (2023-2024):开始把 DETR 思想和 YOLO 的高效推理框架结合,兼顾精度与实时性。