EfficientDet(2019):可扩展且高效的目标检测,使用EfficientNet主干
导出时间:2025/11/23 20:27:11
1、研究背景和动机
一、研究背景
- 目标检测的进步与代价
- 从 Faster R-CNN → RetinaNet → YOLOv3,这些模型的精度在不断提升。
- 但问题是:精度越高,代价越大。
- NAS-FPN 需要 1.67 亿参数 和 3045 亿次 FLOPs,计算量是 RetinaNet 的 30 倍。
- 这类“大模型”在真实应用(自动驾驶、机器人、移动端)里很难部署,因为它们既 占空间,又 费算力。
- 现实需求:高效又准确
- 工业界(比如 Google、特斯拉)需要检测器能 兼顾速度、体积和精度。
- 以前的做法:
- YOLOv3 追求实时性 → 速度快但精度一般;
- RetinaNet 追求精度 → 但计算量大;
- 因此提出了一个问题: 👉 能否设计出既高效(省算力、省内存),又能在不同硬件平台灵活伸缩的检测器?
二、EfficientDet 的研究动机
论文里明确提出了两大核心挑战:
挑战 1:高效的多尺度特征融合
- FPN、PANet、NAS-FPN 已经证明:多尺度特征融合对检测很重要。
- 但问题是:
- FPN 信息流是单向的(自上而下),有限;
- PANet 引入双向,但参数和计算量太大;
- 动机:设计一个 更简洁高效 的多尺度融合方式。 👉 EfficientDet 提出了 BiFPN(加权双向特征金字塔),既保留效果,又降低计算量。
挑战 2:模型扩展方式不合理
- 以往提高精度的方式:
- 增大 backbone 网络(ResNet → ResNeXt → AmoebaNet);
- 增大输入分辨率;
- 堆叠更多 FPN 层。
- 但这些都是单一维度扩展 → 往往效率不高,资源浪费。
- 动机:提出一种 统一的、多维度的缩放方法,可以同时在深度、宽度、分辨率上进行合理扩展。 👉 EfficientDet 引入了复合缩放(Compound Scaling),让模型在不同资源约束下都能找到最优平衡。
三、研究目标
EfficientDet 的目标就是:
- 在相同精度下,大幅减少参数量和计算量(比 YOLOv3 少 28 倍 FLOPs,比 RetinaNet 少 30 倍,比 NAS-FPN 少 19 倍)。
- 在相同计算预算下,精度超过所有现有模型(EfficientDet-D7 在 COCO 上达到了 51.0 mAP,新 SOTA)。
- 模型系列化:从 D0 → D7,不同规模对应不同算力环境(比如 D0 用在手机,D7 用在服务器)。
✅ 一句话总结背景和动机:
EfficientDet 的提出是为了应对 检测器“越准越大”的困境,通过 BiFPN(高效特征融合)+ 复合缩放(合理扩展),打造了一套既高效、又可伸缩的目标检测器家族,能在 移动端到云端 各类环境下灵活部署。
2、 EfficientDet 的四大核心创新
1. BiFPN(聪明的特征金字塔)
- 问题:我们要检测的目标有大有小(比如大卡车、小猫咪),模型需要同时看“远景”和“近景”的信息。
- 以前的方法:就是把不同层的特征“直接加在一起”,好像开会时每个人的意见都一样重要。
- EfficientDet 的改进:
- 它让模型 自动学会“谁说话更重要”,比如检测小猫时更依赖细节层,检测大卡车时更依赖语义层。
- 信息可以 上下双向流动(像电梯一样可以上上下下),而不是只从上往下传。
- 还用了“轻量化卷积”,计算更快。
👉 类比:开会时,不再是所有人发言权一样,而是根据情况分配话语权,让会议高效又有结果。
2. 复合缩放(均衡训练法)
- 问题:以前模型升级就像“只练胳膊”或者“只练腿”,比如:
- YOLOv3 → 只加大图片尺寸;
- RetinaNet → 换更大的 backbone;
- FPN → 堆更多层。
- 结果:某些地方很强,但整体不均衡,效率低。
- EfficientDet 的改进:
- 提出一个“统一缩放法”,就像健身时 同时练胳膊、腿、核心肌群,保持全身均衡。
- 这样,模型在“大小、宽度、分辨率”三个维度一起升级,效率最高。
- 用一个参数 φ(phi)来控制“升级等级”,于是就有了 D0~D7,不同等级适配不同设备(手机用 D0,服务器用 D7)。
👉 类比:YOLO/RetinaNet 升级像“偏科生”,EfficientDet 升级像“全面发展的学霸”。
3. EfficientNet 主干(省钱的照相机)
- 问题:传统的 backbone(比如 ResNet)很强,但太“笨重”。
- EfficientDet 的改进:用 EfficientNet,当主干更小、更快、更省算力。
- 效果:拍照(提取特征)这一步就省了大笔开销。
👉 类比:别人用单反相机(重、贵),EfficientDet 用的是“轻便又清晰的无反相机”。
4. 共享子网络(共用老师批改作业)
- 问题:以前每个层级都要安排一套“分类器 + 回归器”(相当于请很多老师来批改作业),参数多,效率低。
- EfficientDet 的改进:所有层级共用一套老师(共享参数),避免浪费。
👉 类比:以前是每个班级单独请老师,现在是一个老师走班批改 → 效率更高,还能保持标准一致。
🔑 总结一句话
EfficientDet 就像是:
- 开会时更聪明(BiFPN),
- 训练时更均衡(复合缩放),
- 照相机更轻便(EfficientNet),
- 批改作业更高效(共享子网络)。
👉 最终效果:小身材,大能量,省算力,还比别人更准! 🚀
3、特征金字塔
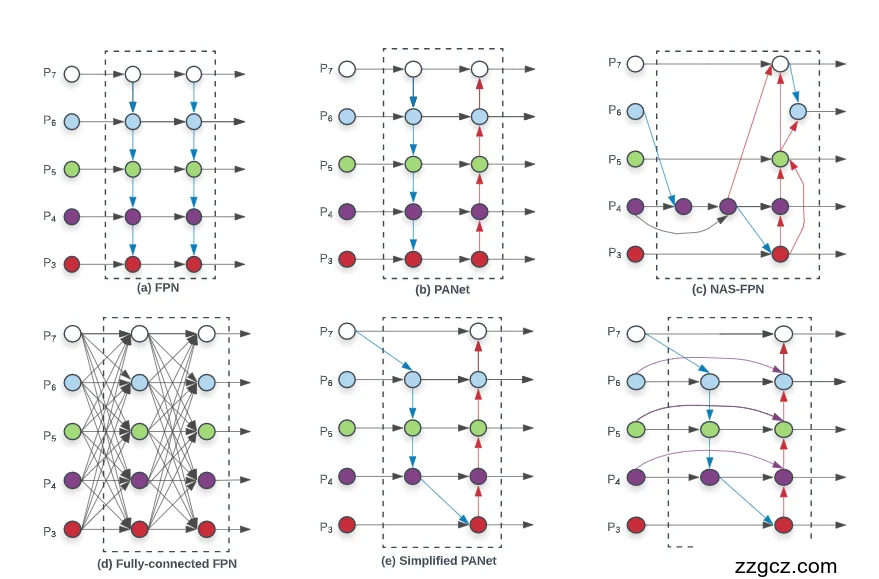
背景:为什么要特征金字塔?
在目标检测里:
- 小目标(比如猫的眼睛)需要高分辨率、细节多的特征(低层)。
- 大目标(比如整辆卡车)需要低分辨率、语义强的特征(高层)。 👉 所以我们必须把不同层级的特征融合起来,形成一个“多尺度视角”。
图中六种方法
(a) FPN(Feature Pyramid Network)
- 蓝色箭头:只做 自上而下 的融合。
- 高层(语义强)往下传给低层(细节强),最后各层都得到融合特征。 👉 优点:结构简单,效果不错。 👉 缺点:信息流是单向的,低层的信息不能往上传递。
(b) PANet(Path Aggregation Network)
- 在 FPN 基础上又加了一条 自下而上的路径(红色箭头)。
- 这样就变成 双向流动:上层给下层,下层也能给上层。 👉 好处:融合更充分,检测小目标更好。 👉 缺点:结构更复杂,计算量增加。
(c) NAS-FPN(Neural Architecture Search FPN)
- 用神经架构搜索 (NAS) 自动设计特征融合方式。
- 结果:连接方式很奇怪、不规则(图里红蓝乱连),但效果很好。 👉 优点:精度很高。 👉 缺点:网络复杂、训练代价超级大(要花几千 GPU 小时)。
(d) Fully-connected FPN
- 每一层都和其他层相连(全连接)。
- 信息流最丰富,但计算代价极大,基本不可用。 👉 就像所有人同时对话,效率反而低下。
(e) Simplified PANet
- 对 PANet 进行简化,去掉了一些没必要的连接。
- 保留核心路径,减少冗余。 👉 算是一个折中方案,比 PANet 省算力,但效果没 BiFPN 好。
(f) BiFPN(Bidirectional FPN) —— EfficientDet 的核心
- 保留 双向路径(上到下、下到上都有)。
- 加入 跨层连接(比如 P3 直连 P4),信息更充分。
- 每条边有 可学习权重(图里粗细不同的箭头),网络自己学“谁更重要”。
- 用 轻量化卷积,算力开销比 PANet 小很多。 👉 优点:融合最合理,计算最省,效果最好。
总结类比
你可以把这几种方法类比成“开会沟通方式”:
- FPN:只有领导(高层)讲话,下属只能听。
- PANet:上下级都能交流,但沟通渠道比较多,稍显冗余。
- NAS-FPN:AI 乱安排会议议程,效果好,但代价巨大。
- Fully-connected:所有人同时说话,会议一团乱。
- Simplified PANet:只保留重要沟通渠道,省事但不是最优。
- BiFPN:有上下交流,关键人有权重(说话份量不同),而且会议安排很高效。
👉 所以 EfficientDet 选择了 BiFPN,既保留 PANet 的优势,又比 NAS-FPN 更高效。
4、模型的核心网络结构
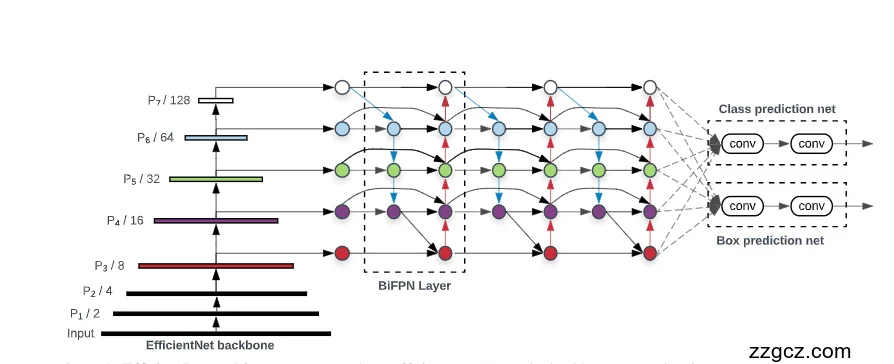
1)左边:EfficientNet 主干(Backbone)
- 黑色粗条是 EfficientNet 在逐步下采样图片:
P3/8、P4/16、P5/32、P6/64、P7/128表示分辨率被缩小了 8、16、32、64、128 倍的特征图。- 直觉上:
- P3:图还比较细,适合看小目标细节;
- P7:图很粗但语义强,适合看大目标的大概轮廓。
- 这些五张“不同远近的照片”,会一起送到中间的融合模块。
2)中间:BiFPN 层(多尺度特征融合的“聪明会议室”)
虚线框里写着 BiFPN Layer,右边还连着好几层同样的 BiFPN,表示“重复几次融合会更稳更强”。
BiFPN 做三件事:
- 双向流动
- 蓝色箭头(自上而下):把“语义更强”的高层特征往下传,帮助底层理解“大概是什么”。
- 红色箭头(自下而上):把“细节更足”的低层特征往上传,帮助高层看清“具体在哪/边缘如何”。
- 这样上下都能“说话”,信息来回流动,比只单向传更全面。
- 跨层连线 + 多次叠加
- 你会看到同一层级(比如 P5)既接来自上面的信息、也接来自下面的信息,还和邻层有横向/弧线连接;
- 这些 跨层 的“捷径”让信息融合更充分;
- 多个 BiFPN 层串起来,相当于“把会开几轮”,每轮都把各层要点再揉一遍,越揉越均衡。
- 学会“谁更重要”
- 每条箭头就像一个发言人;BiFPN 给每条边一个可学习的“话语权”(权重),不是一刀切地平均相加;
- 检测小目标时,底层(清晰度高)的意见更重要;大目标时,高层(语义强)的意见更重要;
- 同时用深度可分离卷积处理,既快又省算力(先“各通道各做各的”,再合并,计算量比普通卷积小很多)。
小结:BiFPN 就是一个高效又会分配话语权的多层会议系统,把 P3~P7 的不同“视角”融合得又全又省。
3)右边:两套“预测头”(Heads)——分类头 & 框回归头
- 图右侧有两条并行的小网络:
- Class prediction net:判断每个位置/锚框是“哪一类”;
- Box prediction net:给出这个框该往哪儿挪、变多大(边界框回归)。
- 这两套小网络会 在所有金字塔层上“共享同一套参数”:
- 好处:参数更少、不容易过拟合;不同尺度用同一把尺子评判,标准一致;
- 所以你看到它们从每层 BiFPN 特征都拉了虚线过去,表示同一套头复用在每一层上。
- 最终把所有层的预测框汇总,再做 NMS 去重,就得到检测结果。
把整条流水线串起来(一句话)
图片 → EfficientNet 抽多尺度特征 (P3~P7) → 多层 BiFPN 双向加权融合 → 共享的分类头 & 回归头在每层上做预测 → 合并去重 → 输出目标类别与位置。
为什么它“又小、又快、又准”
- 准:多轮 BiFPN 把大小目标的信息揉得更充分;可学习权重让“该谁说话大声”由数据决定。
- 快/小:EfficientNet 做主干本身就省;BiFPN 用深度可分离卷积、砍掉无用连线;预测头共享参数,不重复造轮子。
5、EfficientDet 的重大缺陷
- 依然是 Anchor-based(基于锚框)
- EfficientDet 还是需要预定义锚框(不同尺寸和长宽比),这会导致:
- 设计复杂:锚框参数要人工调节;
- 计算冗余:大量无效的负样本预测(和 RetinaNet 类似);
- 对小目标不友好:锚框如果设计不合适,小目标容易漏检。
- EfficientDet 还是需要预定义锚框(不同尺寸和长宽比),这会导致:
- 训练仍然复杂 & 不够灵活
- 虽然复合缩放解决了效率问题,但它的 超参数 φ 是通过启发式公式得到的,不一定是全局最优。
- 不同应用场景(移动端 vs 云端)还要重新挑选合适的 D0~D7,灵活性有限。
- 对动态场景适应性差
- EfficientDet 的结构是固定的 BiFPN 层数和固定的缩放策略。
- 在视频、多任务检测(比如检测 + 分割)、复杂场景里,可能显得僵化,难以动态调整。
- 比 YOLO 系列在推理速度上仍有差距
- 虽然它比 RetinaNet、NAS-FPN 高效得多,但在极端实时应用(如无人机、手机端实时检测),YOLOv4/YOLOv5 后来居上,速度更快、生态更好。
- 缺乏 Transformer 思想(这是当时的时代限制)
- EfficientDet 仍然是 CNN 结构,没有用到后续大热的 Transformer + 自注意力。
- 在处理长距离依赖(如密集小目标、复杂背景)时,效果不如后来的 DETR、Deformable DETR。
6、后续改进与创新方向
很多新模型就是在 弥补 EfficientDet 的不足。可以分为几类:
1. Anchor-free 方向(去掉锚框)
- FCOS (2019)、ATSS (2020)
- 不再依赖锚框,而是直接预测目标中心点和大小。
- 避免锚框设计的复杂性和计算冗余。
- YOLOX (2021)
- 基于 YOLOv5 改进为 Anchor-free,更简单高效。
👉 这些方法解决了 EfficientDet 的 “锚框依赖”问题。
2. Transformer 检测器
- DETR (2020):用 Transformer 直接把检测任务看作“序列到序列”的预测,完全去掉锚框和 NMS。
- Deformable DETR (2021):在 DETR 基础上提高收敛速度,提升小目标检测效果。
👉 这些方法解决了 EfficientDet 在长程建模和小目标检测上的不足。
3. YOLO 系列进化(极致实时化)
- YOLOv4 (2020) → 提升精度的同时保持实时;
- YOLOv5/6/7/8 (2020~2023) → 通过模块优化(CSPNet、PAN-FPN 等)、无锚框策略,兼顾速度和精度;
- YOLO-NAS (2023) → 自动架构搜索,精度和效率更优。
👉 它们在部署友好性和速度上远超 EfficientDet。
4. 更智能的特征融合网络
- NAS-FPN → BiFPN → DyHead (2022)
- DyHead 引入动态选择不同层特征,更灵活。
- DetectoRS (2020)
- 用 递归 FPN 和 Switchable Atrous Convolution,提升小目标检测能力。
👉 解决 EfficientDet “融合方式固定”的问题。