Fast R-CNN(2015):开山鼻祖模型的进化,引入ROI Pooling
导出时间:2025/11/23 20:25:46
1、Fast R-CNN的背景和动机
1.1、回顾 R-CNN 的问题(为什么需要改进?)
R-CNN 虽然在当年实现了“划时代的突破”,但用起来却非常笨重,有三个致命缺陷:
- 计算冗余,太慢 🐢
- 一张图片里,R-CNN 要对大约 2000 个候选框,逐个送进 CNN。
- 相当于把同一张图片重复计算 2000 次,效率极其低下。
- 举个例子:在 PASCAL VOC 数据集上,R-CNN 处理一张图要 数十秒,几乎不能用在实际场景。
👉 就像工厂流水线上,每个零件都要从头重新加工一遍,完全没有复用效率。
- 训练复杂 😵
- R-CNN 要分三步训练: ① 微调 CNN → ② 训练 SVM 分类器 → ③ 训练边界框回归器。
- 各部分割裂,不能“端到端”一起优化。
👉 就像警察办案:一个部门只训练观察力,另一个部门只训练判断力,第三个部门只训练标尺对齐——最后要把三拨人凑一起,流程超级麻烦。
- 存储开销大 💾
- R-CNN 会把每个候选框的 CNN 特征(4096 维)存到硬盘上。
- 对大数据集来说,光存储就要几个百 GB。
👉 就像侦探调查时,要把每个嫌疑人的长篇报告都复印存档,资料室爆满。
1.2、Fast R-CNN 的动机(为什么提出它?)
Ross Girshick(R-CNN 的作者)在 2015 年提出 Fast R-CNN,主要是为了解决上述三大问题:
- 减少重复计算 → 加快速度
- 能不能整张图只跑一次 CNN?
- 得到特征图(feature map)之后,再从特征图上切出候选区域的特征,而不是每个候选框都重复跑 CNN。
- 这样候选框共享卷积计算,速度直接提升几个数量级。
- 端到端训练 → 简化流程
- 能不能把 CNN 特征提取、分类、边界框回归全都放进一个网络里,一次性训练?
- Fast R-CNN 就这样做到了,把流程整合到一个统一的框架里。
- 丢掉大规模存储 → 内存友好
- Fast R-CNN 不再保存中间的候选框特征,而是直接在 GPU 内存里计算和更新。
- 避免了 R-CNN 那种“硬盘爆炸”的情况。
1.3、一句话总结背景与动机
- 背景:R-CNN 解决了“深度学习能不能做检测”的问题,但它速度太慢、训练太复杂、存储太浪费。
- 动机:Fast R-CNN 想要一个更高效、更简洁的目标检测框架:
- 快(共享卷积特征)、
- 准(端到端优化)、
- 省(减少存储开销)。
2、 Fast R-CNN 的整体流程(对比 R-CNN)
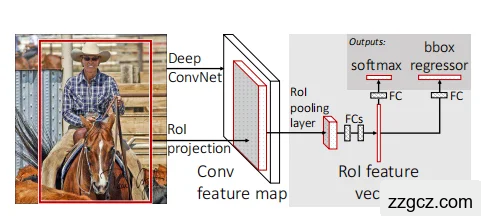
- 整张图过一次“大型扫描仪”(Deep ConvNet)
- 左边的图是一张输入图像(牛仔+马)。
- 我们不再像 R-CNN 那样,把每个框单独送进 CNN 里算 2000 次。
- Fast R-CNN 只需要 整张图过一次卷积神经网络,得到一张“特征地图”。
👉 类比:你进机场安检,不用每个人拆开检查 2000 次,而是直接让大家一起过安检门,扫描仪一次搞定。
- 把候选框投影到特征地图(RoI Projection)
- 在原图里,传统算法(Selective Search)自动提前给我们画出一些“可疑区域”(比如红色方框框住牛仔)。
- 我们把这些区域映射到“特征地图”上。
👉 类比:安检时,系统在扫描结果上用方框标出“可能有问题的地方”。
- RoI Pooling:把框“压缩成统一大小”
- 不同的候选框大小不一样,有的大(整个牛仔+马),有的小(牛仔的脸)。
- 但神经网络的全连接层要求输入大小必须固定。
- RoI Pooling 就是一个“自动裁剪+压缩”的工具,把每个候选框都缩放成一样大小的“特征小方块”(比如 7×7)。
👉 类比:就像把大件行李、小件包裹都放进同样大小的托盘里,这样后面的机器才能统一处理。
- RoI 特征向量 → 全连接层(FCs)
- RoI Pooling 得到固定大小的“特征小方块”,再展平成一个“特征向量”。
- 送进全连接层,提取更高级的抽象信息。
👉 类比:安检员拿到托盘里的东西,做进一步精细分析。
- 两个结果输出:分类 + 框微调
- Softmax 分类器:判断这个区域里是什么 → 是“人”?是“马”?还是背景?
- BBox regressor(边界框回归器):对框的位置做微调,让方框更准确地贴合目标。
👉 类比:安检员最后结论:① 托盘里确实是“人”,② 重新画个更精确的红框,把人的范围标清楚。
方面
| R-CNN
| Fast R-CNN
| 相同点/不同点
| 优化的好处
|
候选框生成
| 使用 Selective Search(约 2000 个 RoI)
| 仍然使用 Selective Search(约 2000 个 RoI)
| ✅ 相同
| ——(候选框部分还未优化,等到 Faster R-CNN 才改进)
|
CNN 特征提取
| 每个候选框单独裁剪 → 输入 CNN 计算特征
| 整张图只过一次 CNN,得到共享特征图
| ❌ 不同
| 减少重复计算,大幅提升速度
|
候选框特征获取
| 直接裁剪图像区域送 CNN
| 在共享特征图上用 RoI Pooling 提取固定大小特征
| ❌ 不同
| 保证输入大小统一,计算更高效
|
分类器
| 用 SVM 分类
| 用 Softmax 分类
| ❌ 不同
| 整合进网络,避免额外训练步骤
|
边界框回归
| 单独训练一个线性回归器
| 融合进网络,多任务一起训练
| ❌ 不同
| 更精准,训练更简单
|
训练方式
| 分三步:① 微调 CNN ② 训练 SVM ③ 训练回归器
| 端到端,多任务联合训练(分类+回归一起优化)
| ❌ 不同
| 训练流程简化,更稳定
|
存储开销
| 需要存储每个候选框的特征(上百 GB)
| 不存储中间特征,直接在 GPU 里处理
| ❌ 不同
| 大幅降低存储需求
|
速度
| 非常慢(几十秒/张图)
| 快很多(几百毫秒/张图)
| ❌ 不同
| 更接近实际应用需求
|
精度
| 提升了传统方法,但受限于效率
| 精度相当甚至更好
| ❌ 不同
| 兼顾“更快”和“更准”
|
3、Fast R-CNN 仍然存在的缺陷
- 候选框(Region Proposals)生成太慢 🚶♂️
- Fast R-CNN 虽然共享了卷积计算,但 候选框还是靠 Selective Search 生成。
- Selective Search 是一个“传统算法”,在 CPU 上运行,一张图大约要 2 秒钟。
- 这成为整个系统的瓶颈:网络部分已经很快,但候选框生成拖后腿。
👉 类比:你安检时,X 光机(CNN)很快,但工作人员(Selective Search)手动在屏幕上画方框,速度还是很慢。
- 不是完全端到端 🔀
- 候选框生成和后续网络(CNN+分类+回归)还是两个独立步骤。
- 网络只能学“分类”和“微调”,但不会学“如何生成候选框”。
👉 类比:侦探自己能识别人,但还要依赖别人帮他先圈“嫌疑区域”,不能从头到尾独立完成。
- 候选框数量大 📦
- 一张图 2000 个候选框,即使后面计算快了,数量依然庞大。
- 很多候选框其实是“冗余”的(比如 10 个几乎重叠的框)。
👉 类比:机场安检抓了 2000 个嫌疑人来复查,虽然检查快了,但嫌疑人还是太多。
4、Faster R-CNN 的改进(核心创新:RPN)
Faster R-CNN 的关键在于:把候选框生成这一步,也交给 CNN 来做。
候选框生成、分类、边界框回归,全部整合在一个网络里训练。
从 Fast R-CNN 的 秒级 → Faster R-CNN 的 百毫秒级,真正接近实时。